《从Paxos到zookeeper分布式一致性原理与实践》笔记
《从Paxos到zookeeper分布式一致性原理与实践》笔记
文章目录
- 《从Paxos到zookeeper分布式一致性原理与实践》笔记
- 一、概念
- 二、一致性协调
- 2.1 2PC (Two-Phase Commit)
- 前提
- 基本算法
- 算法示意
- 缺点
- 2.2 3PC (Three-Phase Commit)
- 基本算法
- 1.CanCommit阶段
- 2.PreCommit阶段
- 3.DoCommit阶段
- 算法示意
- 2PC和3PC区别
- 优缺点
- 2.3 Paxos(解决单点问题)
- Paxos算法原理
- Paxos算法过程
- 三、Zookeeper
- 3.1、初识Zookeeper
- 3.1.1 zookeeper可以保证如下分布式一致性特性
- 3.1.2 zookeeper的四个设计目标
- 3.1.3 zookeeper的基本概念
- 1、集群角色
- 2、会话
- 3、数据节点
- 4、版本
- 5、Watcher
- 6、ACL
- 3.2、ZAB
- 3.2.1、ZAB协议
- 3.2.2、ZAB两种基本的模式:崩溃恢复和消息广播。
- 崩溃恢复
- 消息广播
- 基本特性
- 数据同步
- 3.2.3、ZAB协议原理
- 3.3、ZAB与Paxos的联系和区别
- 四、使用Zookeeper
- 4.1、部署与运行
- 4.2、客户端脚本
- 4.3、Java客户端API使用
- 4.4、开源客户端
- 4.4.1、ZkClient
- 4.1.1 添加依赖
- 4.4.2、Curator客户端
- 4.4.2.1 添加依赖
- 4.4.2.2 创建会话
- 4.4.2.3 创建节点
- 4.4.2.7 异步接口
- 4.2.8 节点监听
- 4.2.9 子节点监听
- 4.2.10 Master选举
- 4.2.11 分布式锁
- 4.4.2.12 分布式计数器 DistributedAtomicInteger
- 4.4.2.13 分布式Barrier
- 4.4.3、Curator工具类
- 4.4.3.1 ZKPaths
- 4.4.3.2 EnsurePath
- 五、Zookeeper应用场景
- 5.1、典型应用场景及实现
- 5.1.1 数据发布/订阅
- 5.1.2 负载均衡
- 5.1.3 命名服务
- 5.1.4 分布式协调/通知
- 5.1.5 集群管理
- 5.1.6 Master选举
- 5.1.7 分布式锁
- 5.1.8 分布式队列
- 5.2、zk在大型分布式系统中的应用
- 5.2.1 Hadoop
- 5.2.1.1 YARN
- 5.2.1.2 ResourceManager HA
- 5.2.1.3 主备切换
- 5.2.1.4 隔离(Fencing)
- 5.2.1.5 ResourceManager状态存储
- 5.2.2 HBase
- 5.2.3 Kafka
- 5.2.3.1 Broker注册
- 5.2.3.2 Topic注册
- 5.2.3.3 生产者负载均衡
- 5.2.3.4 消费者负载均衡
- 5.2.3.5 消费分区与消费者的关系
- 5.2.3.6 消息消费进度Offset记录
- 5.2.3.7 消费者注册
- 5.2.3.8 负载均衡
- 《从Paxos到zookeeper分布式一致性原理与实践》笔记
- 第6章ZooKeeper技术内幕
- 6.1 系统模型
- 6.1.1 数据模型
- 6.1.2 节点特性
- 6.1.3 版本——保证分布式数据原子性操作
- 6.1.4 Watcher——数据变更的通知
- 6.1.5 ACL——保障数据的安全
- 6.2 序列化与协议
- 6.2.1 Jute介绍
- 6.2.2 使用Jute进行序列化
- 6.2.3 深入Jute
- 6.2.4 通信协议
- 6.2.4.1 请求协议
- 6.2.4.2 响应协议
- 6.2.5 stat状态说明
- 6.3 客户端
- 6.3.1 一次会话的创建过程
- 6.3.2 服务器地址列表
- 6.3.3 ClientCnxn:网络I/O
- 6.4 会话
- 6.4.1 会话状态
- 6.4.2 会话创建
- 6.4.3 会话管理
- 6.4.4 会话清理
- 6.4.5 重连
- 6.4.5.1 重连状态(CONNECTED & EXPIRED)
- 6.4.5.2 重连异常: CONNECTION_LOSS(连接断开)和SESSION_EXPIRED(会话过期)
- 6.5 服务器启动
- 6.5.1 单机版服务器启动
- 6.5.1.1 单机版服务器启动 - 预启动
- 6.5.1.2 单机版服务器启动 - 初始化
- 6.5.2 集群版服务器启动
- 6.5.2.1 集群版服务器启动 - 预启动
- 6.5.2.2 集群版服务器启动 - 初始化
- 6.6 Leader选举
- 6.6.1 Leader选举概述
- 6.6.1.1 服务器启动时期的Leader选举
- 6.6.1.2 服务器运行时期的Leader选举
- 6.6.2 Leader选举的算法分析
- 6.6.2.1 术语解释
- 6.6.2.2 进入leader选举
- 6.6.3 Leader选举的实现细节
- 6.7 各服务器角色介绍
- 6.7.1 Leader
- 6.7.1.1 请求处理链
- 6.7.1.2 LearnerHandler
- 6.7.2 Follower
- 6.7.3 Observer
- 6.7.4 集群间消息通信
- 6.8 请求处理
- 6.8.1 会话创建请求
- 6.8.1.1 请求接收
- 6.8.1.2 会话创建
- 6.8.1.3 预处理
- 6.8.1.4 事务处理
- 6.8.1.5 事务应用
- 6.8.1.6 会话响应
- 6.8.2 SetData请求
- 6.8.3 事务请求转发
- 6.8.4 GetData请求
- 6.9 数据与存储
- 6.9.1 内存数据
- 6.9.2 事务日志
- 6.9.2.1 文件存储
- 6.9.2.2 日志格式
- 6.9.2.3 日志写入
- 6.9.2.4 日志截断
- 6.9.3 snapshot——数据快照
- 6.9.3.1 文件存储
- 6.9.3.2 数据快照
- 6.9.4 初始化
- 6.9.4.1 初始化流程
- 6.9.5 数据同步
- 七、Zookeeper运维
- 7.1 配置参数
- 7.1 2四字命令
- reference
================
一、概念
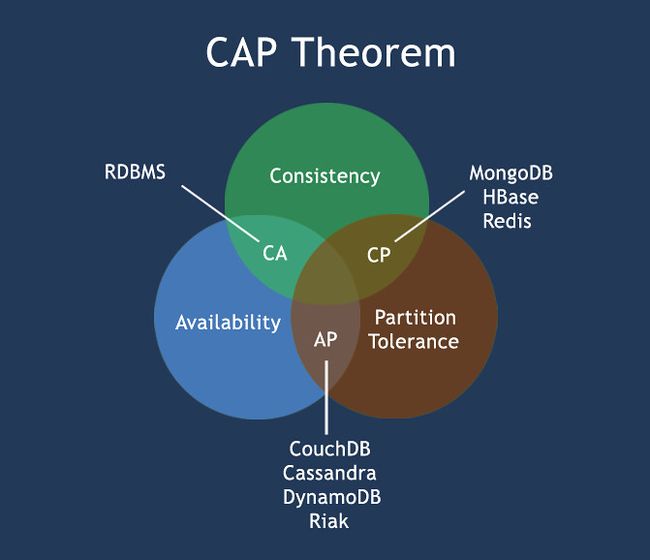
ACID: Automaticy、consistency、isolation、 Durability
CAP: consistency、 Availability、 Partition tolerance
BASE: Basically Available、 Soft state、 Eventually consistent
二、一致性协调
协调者
在分布式系统中,每一个机器节点虽然都能明确的知道自己执行的事务是成功还是失败,但是却无法知道其他分布式节点的事务执行情况。因此,当一个事务要跨越多个分布式节点的时候,为了保证该事务可以满足ACID,就要引入一个协调者(Cooradinator)。其他的节点被称为参与者(Participant)。协调者负责调度参与者的行为,并最终决定这些参与者是否要把事务进行提交。
2.1 2PC (Two-Phase Commit)
前提
二阶段提交算法的成立基于以下假设:
- 1/ 该分布式系统中,存在一个节点作为协调者(Coordinator),其他节点作为参与者(Cohorts)。且节点之间可以进行网络通信。
- 2/ 所有节点都采用预写式日志,且日志被写入后即被保持在可靠的存储设备上,即使节点损坏不会导致日志数据的消失。
- 3/ 所有节点不会永久性损坏,即使损坏后仍然可以恢复。
基本算法
二阶段提交协议主要分为来个阶段:准备阶段和提交阶段。
** 第一阶段(提交请求阶段) **
- 1.协调者节点向所有参与者节点询问是否可以执行提交操作,并开始等待各参与者节点的响应。
- 2.参与者节点执行询问发起为止的所有事务操作,并将Undo信息和Redo信息写入日志。
- 3.各参与者节点响应协调者节点发起的询问。如果参与者节点的事务操作实际执行成功,则它返回一个"同意"消息;如果参与者节点的事务操作实际执行失败,则它返回一个"中止"消息。
有时候,第一阶段也被称作投票阶段,即各参与者投票是否要继续接下来的提交操作。
第二阶段(提交执行阶段)
成功
当协调者节点从所有参与者节点获得的相应消息都为"同意"时:
- 1.协调者节点向所有参与者节点发出"正式提交"的请求。
- 2.参与者节点正式完成操作,并释放在整个事务期间内占用的资源。
- 3.参与者节点向协调者节点发送"完成"消息。
- 4.协调者节点收到所有参与者节点反馈的"完成"消息后,完成事务。
失败
如果任一参与者节点在第一阶段返回的响应消息为"终止",或者 协调者节点在第一阶段的询问超时之前无法获取所有参与者节点的响应消息时:
- 1.协调者节点向所有参与者节点发出"回滚操作"的请求。
- 2.参与者节点利用之前写入的Undo信息执行回滚,并释放在整个事务期间内占用的资源。
- 3.参与者节点向协调者节点发送"回滚完成"消息。
- 4.协调者节点收到所有参与者节点反馈的"回滚完成"消息后,取消事务。
有时候,第二阶段也被称作完成阶段,因为无论结果怎样,协调者都必须在此阶段结束当前事务。
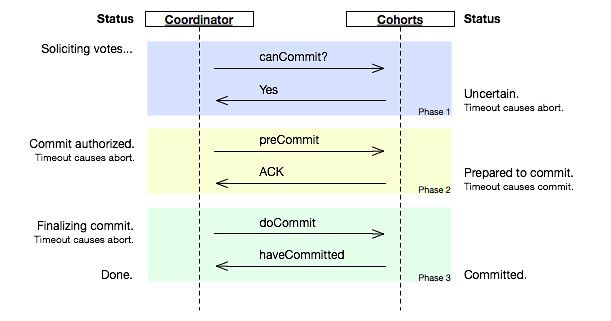
算法示意
协调者 参与者
QUERY TO COMMIT
-------------------------------->
VOTE YES/NO prepare*/abort*
<-------------------------------
commit*/abort* COMMIT/ROLLBACK
-------------------------------->
ACKNOWLEDGMENT commit*/abort*
<--------------------------------
end
- 所标记的操作意味着此类操作必须记录在稳固存储上.
缺点
1、同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
2、单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
3、数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
4、二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
2.2 3PC (Three-Phase Commit)
除了引入超时机制之外,3PC把2PC的准备阶段再次一分为二,这样三阶段提交就有CanCommit、PreCommit、DoCommit三个阶段。
基本算法
1.CanCommit阶段
3PC的CanCommit阶段其实和2PC的准备阶段很像。
协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
2.PreCommit阶段
协调者(Coordinator)根据参与者(Cohort)的反应情况来决定是否可以继续事务的PreCommit操作。
根据响应情况,有以下两种可能。
执行提交
假如Coordinator从所有的Cohort获得的反馈都是Yes响应,那么就会进行事务的预执行:
发送预提交请求。Coordinator向Cohort发送PreCommit请求,并进入Prepared阶段。
事务预提交。Cohort接收到PreCommit请求后,会执行事务操作,并将undo和redo信息记录到事务日志中。
响应反馈。如果Cohort成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。
中断事务
假如有任何一个Cohort向Coordinator发送了No响应,或者等待超时之后,Coordinator都没有接到Cohort的响应,那么就中断事务:
发送中断请求。Coordinator向所有Cohort发送abort请求。
中断事务。Cohort收到来自Coordinator的abort请求之后(或超时之后,仍未收到Cohort的请求),执行事务的中断。
3.DoCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况:
** 执行提交 **
A.发送提交请求。Coordinator接收到Cohort发送的ACK响应,那么他将从预提交状态进入到提交状态。并向所有Cohort发送doCommit请求。
B.事务提交。Cohort接收到doCommit请求之后,执行正式的事务提交。并在完成事务提交之后释放所有事务资源。
C.响应反馈。事务提交完之后,向Coordinator发送ACK响应。
D.完成事务。Coordinator接收到所有Cohort的ACK响应之后,完成事务。
** 中断事务 **
Coordinator没有接收到Cohort发送的ACK响应(可能是接受者发送的不是ACK响应,也可能响应超时),那么就会执行中断事务。
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。(其实这个应该是基于概率来决定的,当进入第三阶段时,说明参与者在第二阶段已经收到了PreCommit请求,那么协调者产生PreCommit请求的前提条件是他在第二阶段开始之前,收到所有参与者的CanCommit响应都是Yes。(一旦参与者收到了PreCommit,意味他知道大家其实都同意修改了)所以,一句话概括就是,当进入第三阶段时,由于网络超时等原因,虽然参与者没有收到commit或者abort响应,但是他有理由相信:成功提交的几率很大。 )
算法示意
2PC和3PC区别
| 区别 | 2PC | 3PC |
|---|---|---|
| 阶段 | 提交事务请求 以及 执行事务提交 | 只有协调者有超时判断。3PC将2PC的提交事务请求分成了CanCommit以及PreCommit |
| 超时 | 只有协调者有超时判断 | 3PC上参与者和协调者都有超时的判断 |
优缺点
优点:降低参与者阻塞范围,并能够在出现单点故障后继续达成一致
缺点:引入preCommit阶段,在这个阶段如果出现网络分区,协调者无法与参与者正常通信,参与者依然会进行事务提交,造成数据不一致。
无论是二阶段提交还是三阶段提交都无法彻底解决分布式的一致性问题。Google Chubby的作者Mike Burrows说过, there is only one consensus protocol, and that’s Paxos” – all other approaches are just broken versions of Paxos. 意即世上只有一种一致性算法,那就是Paxos,所有其他一致性算法都是Paxos算法的不完整版。
2.3 Paxos(解决单点问题)
首先推荐larmport自己写的和paxos相关的三篇论文:<< The Part-Time Parliament>>、<>、<>
Paxos算法原理
Paxos算法是Lesile Lamport提出的一种基于消息传递且具有高度容错特性的一致性算法。分布式系统中的节点通信存在两种模型: 共享内存和消息传递。基于消息传递通信模型的分布式系统,不可避免会发生进程变慢被杀死,消息延迟、丢失、重复等问题,Paxos算法就是在存在以上异常的情况下仍能保持一致性的协议。
Paxos算法使用一个希腊故事来描述,在Paxos中,存在三种角色,分别为Propose(提议者,用来发出提案proposal), Acceptor(接受者,可以接受或拒绝提案), Learner(学习者,学习被选定的提案,当提案被超过半数的Acceptor接受后为被批准)。下面更精确的定义Paxos要解决的问题:
- 1.决议(value)只有在被proposer提出后才能被批准
- 2.在一次Paxos算法的执行实例中,只批准(chose)一个value
- 3.learner只能获得被批准(chosen)的value。
一般的Paxos说明都会采用不断加强条件的方式来最终达成一致性条件,这样的方式看上去不太容易理解,容易让人以为是一步一步推出来的,实际上更像一致性的一种充分不必要条件。
Paxos算法过程
首先有一个递增的编号生成器,可以保证生成的需要递增,用来为Proposer生成提议的编号。
第一阶段 prepare阶段:
- 1.Proposer生成编号n并使用v作为value的提案(n, v)发送prepare请求给Acceptor中的大多数。
- 2.Acceptor收到prepare请求后,如果提案的编号大于它已经回复的所有prepare消息,则Acceptor将上次接收的提案和已接收的value回复给Proposer,并承若不再回复编号小于n的提案。如果Acceptor没有接收过prepare请求或收到的prepare请求的编号都比n小则回复该prepare请求。
第二阶段 批准阶段:
- 1.当一个Proposer收到了多数Acceptor对prepare的回复后,就进入批准阶段。它要想回复prepare请求的Acceptor发送accept请求,包括编号n和上一阶段中返回的消息中的value。
- 2.在不违背自己向其他Proposer的承诺的前提下,Acceptor收到accept请求后接收这个请求。
http://codemacro.com/2014/10/15/explain-poxos/
https://www.zhihu.com/question/19787937
https://baike.baidu.com/item/Paxos 算法
基于消息传递且具有高度容错性的一致性算法。Paxos算法要解决的问题就是如何在可能发生几起宕机或网络异常的分布式系统中,快速且正确地在集群内部对某个数据的值达成一致,并且保证不论发生以上任何异常,都不会破坏整个系统的一致性。
三、Zookeeper
3.1、初识Zookeeper
zookeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、master选举、分布式锁和分布式队列等。
3.1.1 zookeeper可以保证如下分布式一致性特性
- 1、顺序一致性:从同一个客户端发起的事务请求,最终将会严格地按照其发起顺序被应用到Zookeeper中;
- 2、原子性:所有事务的请求结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么在整个集群中所有机器上都成功应用了某一个事务,要么都没有应用,没有中间状态;
- 3、单一视图:无论客户端连接的是哪个Zookeeper服务器,其看到的服务端数据模型都是一致的。
- 4.可靠性:一旦服务端成功应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会被一直保留下来,除非有另一个事务又对其进行了变更。
- 5、实时性:Zookeeper仅仅保证在一定的时间内,客户端最终一定能够从服务端上读到最终的数据状态。
3.1.2 zookeeper的四个设计目标
1、简单的数据模型:能够通过一个共享的、树型结构的名字空间来进行相互协调。
2、可以构建集群:Zookeeper使得分布式程序能够通过一个共享的树形结构的名字空间来进行相互协调,即Zookeeper服务器内存中的数据模型由一系列被称为ZNode的数据节点组成,Zookeeper将全量的数据存储在内存中,以此来提高服务器吞吐、减少延迟的目的。
3、顺序访问:对于来自客户端的每个更新请求,Zookeeper都会分配一个全局唯一的递增编号,这个编号反映了所有事务操作的先后顺序。
4、高性能:Zookeeper将全量数据存储在内存中,并直接服务于客户端的所有非事务请求,因此它尤其适用于以读操作为主的应用场景。
3.1.3 zookeeper的基本概念
1、集群角色
最典型的集群就是Master/Slave模式(主备模式),此情况下把所有能够处理写操作的机器称为Master机器,把所有通过异步复制方式获取最新数据,并提供读服务的机器为Slave机器。Zookeeper引入了Leader、Follower、Observer三种角色,Zookeeper集群中的所有机器通过Leaser选举过程来选定一台被称为Leader的机器,Leader服务器为客户端提供写服务,Follower和Observer提供读服务,但是Observer不参与Leader选举过程,不参与写操作的"过半写成功"策略,Observer可以在不影响写性能的情况下提升集群的性能。
leader:
是整个集群工作机制中的核心,其主要工作有:
1、事务请求的唯一调度和处理者,保证集群事务处理的顺序性。
2、集群内部各服务器的调度者。
follower:
是zookeeper集群状态的跟随者,其主要工作是:
1、处理客户端的非事务请求,转发事务请求给leader服务器。
2、参与事务请求proposal的投票
3、参与leader选举投票
observer
和follower唯一的区别在于,observer服务器只提供非事务服务,不参与任何形式的投票,包括事务请求proposal的投票和leader选举投票。
通常在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
2、会话
指客户端会话,一个客户端连接是指客户端和服务端之间的一个TCP长连接,Zookeeper对外的服务端口默认为2181,客户端启动的时候,首先会与服务器建立一个TCP连接,从第一次连接建立开始,客户端会话的生命周期也开始了,通过这个连接,客户端能够心跳检测与服务器保持有效的会话,也能够向Zookeeper服务器发送请求并接受响应,同时还能够通过该连接接受来自服务器的Watch事件通知。
3、数据节点
第一类指构成集群的机器,称为机器节点,第二类是指数据模型中的数据单元,称为数据节点-Znode,Zookeeper将所有数据存储在内存中,数据模型是一棵树,由斜杠/进行分割的路径,就是一个ZNode,如/foo/path1,每个ZNode都会保存自己的数据内存,同时还会保存一些列属性信息。ZNode分为持久节点和临时节点两类,持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上,而临时节点的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。另外,Zookeeper还允许用户为每个节点添加一个特殊的属性:SEQUENTIAL。一旦节点被标记上这个属性,那么在这个节点被创建的时候,Zookeeper会自动在其节点后面追加一个整形数字,其是由父节点维护的自增数字。
4、版本
对于每个ZNode,Zookeeper都会为其维护一个叫作Stat的数据结构,Stat记录了这个ZNode的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)、aversion(当前ZNode的ACL版本)。
5、Watcher
Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,Zookeeper服务端会将事件通知到感兴趣的客户端。
6、ACL
Zookeeper采用ACL(Access Control Lists)策略来进行权限控制,其定义了如下五种权限:
- CREATE:创建子节点的权限。
- READ:获取节点数据和子节点列表的权限。
- WRITE:更新节点数据的权限。
- DELETE:删除子节点的权限。
- ADMIN:设置节点ACL的权限。
3.2、ZAB
Zookeeper为分布式应用提供高效且可靠的分布式协调服务,提供了统一命名服务、配置管理、分布式锁等分布式的基础服务。Zookeeper并没有直接采用Paxos算法,而是采用了一种被称为** ZAB(Zookeeper Atomic Broadcast) ** 的一致性协议。
Zookeeper使用了Zookeeper Atomic Broadcast(ZAB,Zookeeper原子消息广播协议)的协议作为其数据一致性的核心算法。ZAB协议是为Zookeeper专门设计的一种__支持崩溃恢复的原子广播协议__。
3.2.1、ZAB协议
所有事务请求必须由一个全局唯一的服务器来协调处理,这样的服务器被称为leader服务器,而余下的其他服务器则成为follower服务器。leader服务器负责将一个客户端事务请求转换成一个事务proposal,并将该proposal分发给集群中所有的follower服务器。之后leader服务器需要等待所有follower服务器的反馈,一旦超过半数的follower服务器进行了正确的反馈后,那么leader就会再次向所有的follower服务器分发commit消息,要求其将前一个proposal进行提交。
ZAB协议需要确保那些已经在leader服务器上提交的事务最终被所有服务器都提交。ZAB协议需要确保丢弃那些只在leader服务器上被提出的事务。如果让leader选举算法能够保证新选举出来的leader服务器拥有集群中所有机器最高编号(ZXID)的事务proposal,那么就可以保证这个新选举出来的leader一定具有所有已经提交的提案。
3.2.2、ZAB两种基本的模式:崩溃恢复和消息广播。
崩溃恢复
当整个服务框架启动过程中或Leader服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB协议就会进入恢复模式并选举产生新的Leader服务器。
当选举产生了新的Leader服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出恢复模式,那么整个服务框架就可以进入消息广播模式。
Leader选举算法不仅仅需要让Leader自身知道已经被选举为Leader,同时还需要让集群中的所有其他机器也能够快速地感知到选举产生的新的Leader服务器。
当Leader服务器出现崩溃或者机器重启、集群中已经不存在过半的服务器与Leader服务器保持正常通信时,那么在重新开始新的一轮的原子广播事务操作之前,所有进程首先会使用崩溃恢复协议来使彼此到达一致状态,于是整个ZAB流程就会从消息广播模式进入到崩溃恢复模式。
消息广播
ZAB协议的消息广播过程使用原子广播协议,类似于一个二阶段提交过程,针对客户端的事务请求,Leader服务器会为其生成对应的事务Proposal,并将其发送给集群中其余所有的机器,然后再分别收集各自的选票,最后进行事务提交。
整个消息广播协议是基于具有FIFO特性的TCP协议来进行网络通信的,因此能够很容易保证消息广播过程中消息接受与发送的顺序性。
整个消息广播过程中,Leader服务器会为每个事务请求生成对应的Proposal来进行广播,并且在广播事务Proposal之前,Leader服务器会首先为这个事务Proposal分配一个全局单调递增的唯一ID,称之为事务ID(ZXID),由于ZAB协议需要保证每个消息严格的因果关系,因此必须将每个事务Proposal按照其ZXID的先后顺序来进行排序和处理。
当一台同样遵守ZAB协议的服务器启动后加入到集群中,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么加入的服务器就会自觉地进入数据恢复模式:找到Leader所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
基本特性
ZAB协议规定了如果一个事务Proposal在一台机器上被处理成功,那么应该在所有的机器上都被处理成功,哪怕机器出现故障崩溃。
ZAB协议需要确保那些已经在Leader服务器上提交的事务最终被所有服务器都提交。
ZAB协议需要确保丢弃那些只在Leader服务器上被提出的事务
如果在崩溃恢复过程中出现一个需要被丢弃的提议,那么在崩溃恢复结束后需要跳过该事务Proposal
在崩溃恢复过程中需要处理的特殊情况,就决定了ZAB协议必须设计这样的
Leader选举算法
能够确保提交已经被Leader提交的事务的Proposal,同时丢弃已经被跳过的事务Proposal。如果让Leader选举算法能够保证新选举出来的Leader服务器拥有集群中所有机器最高编号(ZXID最大)的事务Proposal,那么就可以保证这个新选举出来的Leader一定具有所有已经提交的提议,更为重要的是如果让具有最高编号事务的Proposal机器称为Leader,就可以省去Leader服务器查询Proposal的提交和丢弃工作这一步骤了。
数据同步
完成Leader选举后,在正式开始工作前,Leader服务器首先会确认日志中的所有Proposal是否都已经被集群中的过半机器提交了,即是否完成了数据同步。
下面分析ZAB协议如何处理需要丢弃的事务Proposal的,ZXID是一个64位的数字,其中低32位可以看做是一个简单的单调递增的计数器,针对客户端的每一个事务请求,Leader服务器在产生一个新的事务Proposal时,都会对该计数器进行加1操作;而高32位则代表了Leader周期epoch的编号,每当选举产生一个新的Leader时,就会从这个Leader上取出其本地日志中最大事务Proposal的ZXID,并解析出epoch['ɛpək]值,然后加1,之后以该编号作为新的epoch,低32位从0来开始生成新的ZXID,ZAB协议通过epoch号来区分Leader周期变化的策略,能够有效地避免不同的Leader服务器错误地使用不同的ZXID编号提出不一样的事务Proposal的异常情况。当一个包含了上一个Leader周期中尚未提交过的事务Proposal的服务器启动时,其肯定无法成为Leader,因为当前集群中一定包含了一个Quorum(过半)集合,该集合中的机器一定包含了更高epoch的事务的Proposal,因此这台机器的事务Proposal并非最高,也就无法成为Leader。
3.2.3、ZAB协议原理
ZAB主要包括消息广播和崩溃恢复两个过程,进一步可以分为三个阶段,分别是发现(Discovery)、同步(Synchronization)、广播(Broadcast)阶段。ZAB的每一个分布式进程会循环执行这三个阶段,称为主进程周期。
- 发现,选举产生PL(prospective leader),PL收集Follower epoch(cepoch),根据Follower的反馈,PL产生newepoch(每次选举产生新Leader的同时产生新epoch)。
- 同步,PL补齐相比Follower多数派缺失的状态、之后各Follower再补齐相比PL缺失的状态,PL和Follower完成状态同步后PL变为正式Leader(established leader)。
- 广播,Leader处理客户端的写操作,并将状态变更广播至Follower,Follower多数派通过之后Leader发起将状态变更落地(deliver/commit)。
在正常运行过程中,ZAB协议会一直运行于阶段三来反复进行消息广播流程,如果出现崩溃或其他原因导致Leader缺失,那么此时ZAB协议会再次进入发现阶段,选举新的Leader。
每个进程都有可能处于如下三种状态之一
- LOOKING:Leader选举阶段。
- FOLLOWING:Follower服务器和Leader服务器保持同步状态。
- LEADING:Leader服务器作为主进程领导状态。
一个Follower只能和一个Leader保持同步,Leader进程和所有与所有的Follower进程之间都通过心跳检测机制来感知彼此的情况。若Leader能够在超时时间内正常收到心跳检测,那么Follower就会一直与该Leader保持连接,而如果在指定时间内Leader无法从过半的Follower进程那里接收到心跳检测,或者TCP连接断开,那么Leader会放弃当前周期的领导,转换到LOOKING状态。
3.3、ZAB与Paxos的联系和区别
联系:
- 都存在一个类似于Leader进程的角色,由其负责协调多个Follower进程的运行。
- Leader进程都会等待超过半数的Follower做出正确的反馈后,才会将一个提议进行提交。
- 在ZAB协议中,每个Proposal中都包含了一个epoch值,用来代表当前的Leader周期,在Paxos算法中,同样存在这样的一个标识,名字为Ballot。
区别:
- Paxos算法中,新选举产生的主进程会进行两个阶段的工作,第一阶段称为读阶段,新的主进程和其他进程通信来收集主进程提出的提议,并将它们提交。第二阶段称为写阶段,当前主进程开始提出自己的提议。
- ZAB协议在Paxos基础上添加了同步阶段,此时,新的Leader会确保存在过半的Follower已经提交了之前的Leader周期中的所有事务Proposal。
- ZAB协议主要用于构建一个高可用的分布式数据主备系统,而Paxos算法则用于构建一个分布式的一致性状态机系统。
四、使用Zookeeper
4.1、部署与运行
4.2、客户端脚本
4.3、Java客户端API使用
4.4、开源客户端
4.4.1、ZkClient
ZkClient是在Zookeeper原声API接口之上进行了包装,是一个更易用的Zookeeper客户端,其内部还实现了诸如Session超时重连、Watcher反复注册等功能
4.1.1 添加依赖
<dependency>
<groupId>com.101tecgroupId>
<artifactId>zkclientartifactId>
<version>0.2version>
dependency>
4.4.2、Curator客户端
Curator解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连,反复注册Watcher和NodeExistsException异常等,现已成为Apache的顶级项目
4.4.2.1 添加依赖
在pom.xml文件中添加如下内容即可。
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-frameworkartifactId>
<version>2.4.2version>
dependency>
4.4.2.2 创建会话
Curator除了使用一般方法创建会话外,还可以使用fluent风格进行创建。
package com.hust.grid.leesf.curator.examples;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class Create_Session_Sample {
public static void main(String[] args) throws Exception {
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", 5000, 3000, retryPolicy);
client.start();
System.out.println("Zookeeper session1 established. ");
CuratorFramework client1 = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181")
.sessionTimeoutMs(5000).retryPolicy(retryPolicy).namespace("base").build();
client1.start();
System.out.println("Zookeeper session2 established. ");
}
}
值得注意的是session2会话含有隔离命名空间,即客户端对Zookeeper上数据节点的任何操作都是相对/base目录进行的,这有利于实现不同的Zookeeper的业务之间的隔离。
4.4.2.3 创建节点
通过使用Fluent风格的接口,开发人员可以进行自由组合来完成各种类型节点的创建
package com.hust.grid.leesf.curator.examples;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
public class Create_Node_Sample {
public static void main(String[] args) throws Exception {
String path = "/zk-book/c1";
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181")
.sessionTimeoutMs(5000).retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
client.start();
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path, "init".getBytes());
System.out.println("success create znode: " + path);
}
}
4.4.2.7 异步接口
如同Zookeeper原生API提供了异步接口,Curator也提供了异步接口。在Zookeeper中,所有的异步通知事件处理都是由EventThread这个线程来处理的,EventThread线程用于串行处理所有的事件通知,其可以保证对事件处理的顺序性,但是一旦碰上复杂的处理单元,会消耗过长的处理时间,从而影响其他事件的处理,Curator允许用户传入Executor实例,这样可以将比较复杂的事件处理放到一个专门的线程池中去。
package com.hust.grid.leesf.curator.examples;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.api.BackgroundCallback;
import org.apache.curator.framework.api.CuratorEvent;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
public class Create_Node_Background_Sample {
static String path = "/zk-book";
static CuratorFramework client = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181")
.sessionTimeoutMs(5000).retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
static CountDownLatch semaphore = new CountDownLatch(2);
static ExecutorService tp = Executors.newFixedThreadPool(2);
public static void main(String[] args) throws Exception {
client.start();
System.out.println("Main thread: " + Thread.currentThread().getName());
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).inBackground(new BackgroundCallback() {
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("event[code: " + event.getResultCode() + ", type: " + event.getType() + "]" + ", Thread of processResult: " + Thread.currentThread().getName());
System.out.println();
semaphore.countDown();
}
}, tp).forPath(path, "init".getBytes());
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).inBackground(new BackgroundCallback() {
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("event[code: " + event.getResultCode() + ", type: " + event.getType() + "]" + ", Thread of processResult: " + Thread.currentThread().getName());
semaphore.countDown();
}
}).forPath(path, "init".getBytes());
semaphore.await();
tp.shutdown();
}
}
运行结果:
Main thread: main
event[code: -110, type: CREATE], Thread of processResult: main-EventThread
event[code: 0, type: CREATE], Thread of processResult: pool-3-thread-1
其中,创建节点的事件由线程池自己处理,而非默认线程处理。
Curator除了提供很便利的API,还提供了一些典型的应用场景,开发人员可以使用参考更好的理解如何使用Zookeeper客户端,所有的都在recipes包中,只需要在pom.xml中添加如下依赖即可
<dependency>
<groupId>org.apache.curatorgroupId>
<artifactId>curator-recipesartifactId>
<version>2.4.2version>
dependency>
4.2.8 节点监听
4.2.9 子节点监听
4.2.10 Master选举
4.2.11 分布式锁
为了保证数据的一致性,经常在程序的某个运行点需要进行同步控制。以流水号生成场景为例,普通的后台应用通常采用时间戳方式来生成流水号,但是在用户量非常大的情况下,可能会出现并发问题。
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.CountDownLatch;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class Recipes_Lock {
static String lock_path = "/curator_recipes_lock_path";
static CuratorFramework client = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
public static void main(String[] args) throws Exception {
client.start();
final InterProcessMutex lock = new InterProcessMutex(client, lock_path);
final CountDownLatch down = new CountDownLatch(1);
for (int i = 0; i < 30; i++) {
new Thread(new Runnable() {
public void run() {
try {
down.await();
lock.acquire();
} catch (Exception e) {
}
SimpleDateFormat sdf = new SimpleDateFormat("HH:mm:ss|SSS");
String orderNo = sdf.format(new Date());
System.out.println("生成的订单号是 : " + orderNo);
try {
lock.release();
} catch (Exception e) {
}
}
}).start();
}
down.countDown();
}
}
4.4.2.12 分布式计数器 DistributedAtomicInteger
分布式计数器的典型应用是统计系统的在线人数,借助Zookeeper也可以很方便实现分布式计数器功能:指定一个Zookeeper数据节点作为计数器,多个应用实例在分布式锁的控制下,通过更新节点的内容来实现计数功能。
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.atomic.AtomicValue;
import org.apache.curator.framework.recipes.atomic.DistributedAtomicInteger;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.curator.retry.RetryNTimes;
public class Recipes_DistAtomicInt {
static String distatomicint_path = "/curator_recipes_distatomicint_path";
static CuratorFramework client = CuratorFrameworkFactory.builder().connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
public static void main(String[] args) throws Exception {
client.start();
DistributedAtomicInteger atomicInteger = new DistributedAtomicInteger(client, distatomicint_path,
new RetryNTimes(3, 1000));
AtomicValue<Integer> rc = atomicInteger.add(8);
System.out.println("Result: " + rc.succeeded());
}
}
4.4.2.13 分布式Barrier
如同JDK的CyclicBarrier,Curator提供了DistributedBarrier来实现分布式Barrier。
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.barriers.DistributedBarrier;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class Recipes_Barrier {
static String barrier_path = "/curator_recipes_barrier_path";
static DistributedBarrier barrier;
public static void main(String[] args) throws Exception {
for (int i = 0; i < 5; i++) {
new Thread(new Runnable() {
public void run() {
try {
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString("127.0.0.1:2181")
.retryPolicy(new ExponentialBackoffRetry(1000, 3)).build();
client.start();
barrier = new DistributedBarrier(client, barrier_path);
System.out.println(Thread.currentThread().getName() + "号barrier设置");
barrier.setBarrier();
barrier.waitOnBarrier();
System.err.println("启动...");
} catch (Exception e) {
}
}
}).start();
}
Thread.sleep(2000);
barrier.removeBarrier();
}
}
4.4.3、Curator工具类
4.4.3.1 ZKPaths
其提供了简单的API来构建znode路径、递归创建、删除节点等。
4.4.3.2 EnsurePath
其提供了一种能够确保数据节点存在的机制,当上层业务希望对一个数据节点进行操作时,操作前需要确保该节点存在。
EnsurePath采取了如下节点创建方式,试图创建指定节点,如果节点已经存在,那么就不进行任何操作,也不对外抛出异常,否则正常创建数据节点。
五、Zookeeper应用场景
5.1、典型应用场景及实现
Zookeeper是一个高可用的分布式数据管理和协调框架,并且能够很好的保证分布式环境中数据的一致性。在越来越多的分布式系统(Hadoop、HBase、Kafka)中,Zookeeper都作为核心组件使用。
典型应用场景
- 数据发布/订阅
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master选举
- 分布式锁
- 分布式队列
5.1.1 数据发布/订阅
数据发布/订阅系统,即配置中心。需要发布者将数据发布到Zookeeper的节点上,供订阅者进行数据订阅,进而达到动态获取数据的目的,实现配置信息的集中式管理和数据的动态更新。发布/订阅一般有两种设计模式:推模式和拉模式,服务端主动将数据更新发送给所有订阅的客户端称为推模式;客户端主动请求获取最新数据称为拉模式,Zookeeper采用了推拉相结合的模式,客户端向服务端注册自己需要关注的节点,一旦该节点数据发生变更,那么服务端就会向相应的客户端推送Watcher事件通知,客户端接收到此通知后,主动到服务端获取最新的数据。
若将配置信息存放到Zookeeper上进行集中管理,在通常情况下,应用在启动时会主动到Zookeeper服务端上进行一次配置信息的获取,同时,在指定节点上注册一个Watcher监听,这样在配置信息发生变更,服务端都会实时通知所有订阅的客户端,从而达到实时获取最新配置的目的。
5.1.2 负载均衡
负载均衡是一种相当常见的计算机网络技术,用来对多个计算机、网络连接、CPU、磁盘驱动或其他资源进行分配负载,以达到优化资源使用、最大化吞吐率、最小化响应时间和避免过载的目的。
使用Zookeeper实现动态DNS服务
· 域名配置,首先在Zookeeper上创建一个节点来进行域名配置,如DDNS/app1/server.app1.company1.com。
· 域名解析,应用首先从域名节点中获取IP地址和端口的配置,进行自行解析。同时,应用程序还会在域名节点上注册一个数据变更Watcher监听,以便及时收到域名变更的通知。
· 域名变更,若发生IP或端口号变更,此时需要进行域名变更操作,此时,只需要对指定的域名节点进行更新操作,Zookeeper就会向订阅的客户端发送这个事件通知,客户端之后就再次进行域名配置的获取。
5.1.3 命名服务
命名服务是分步实现系统中较为常见的一类场景,分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等,通过命名服务,客户端可以根据指定名字来获取资源的实体、服务地址和提供者的信息。Zookeeper也可帮助应用系统通过资源引用的方式来实现对资源的定位和使用,广义上的命名服务的资源定位都不是真正意义上的实体资源,在分布式环境中,上层应用仅仅需要一个全局唯一的名字。Zookeeper可以实现一套分布式全局唯一ID的分配机制。

5.1.4 分布式协调/通知
Zookeeper中特有的Watcher注册于异步通知机制,能够很好地实现分布式环境下不同机器,甚至不同系统之间的协调与通知,从而实现对数据变更的实时处理。通常的做法是不同的客户端都对Zookeeper上的同一个数据节点进行Watcher注册,监听数据节点的变化(包括节点本身和子节点),若数据节点发生变化,那么所有订阅的客户端都能够接收到相应的Watcher通知,并作出相应处理。
MySQL数据复制总线是一个实时的数据复制框架,用于在不同的MySQL数据库实例之间进行异步数据复制和数据变化通知,整个系统由MySQL数据库集群、消息队列系统、任务管理监控平台、Zookeeper集群等组件共同构成的一个包含生产者、复制管道、数据消费等部分的数据总线系统。
Zookeeper主要负责进行分布式协调工作,在具体的实现上,根据功能将数据复制组件划分为三个模块:Core(实现数据复制核心逻辑,将数据复制封装成管道,并抽象出生产者和消费者概念)、Server(启动和停止复制任务)、Monitor(监控任务的运行状态,若数据复制期间发生异常或出现故障则进行告警)
在绝大多数分布式系统中,系统机器间的通信无外乎心跳检测、工作进度汇报和系统调度。
① 心跳检测,不同机器间需要检测到彼此是否在正常运行,可以使用Zookeeper实现机器间的心跳检测,基于其临时节点特性(临时节点的生存周期是客户端会话,客户端若当即后,其临时节点自然不再存在),可以让不同机器都在Zookeeper的一个指定节点下创建临时子节点,不同的机器之间可以根据这个临时子节点来判断对应的客户端机器是否存活。通过Zookeeper可以大大减少系统耦合。
② 工作进度汇报,通常任务被分发到不同机器后,需要实时地将自己的任务执行进度汇报给分发系统,可以在Zookeeper上选择一个节点,每个任务客户端都在这个节点下面创建临时子节点,这样不仅可以判断机器是否存活,同时各个机器可以将自己的任务执行进度写到该临时节点中去,以便中心系统能够实时获取任务的执行进度。
③ 系统调度,Zookeeper能够实现如下系统调度模式:分布式系统由控制台和一些客户端系统两部分构成,控制台的职责就是需要将一些指令信息发送给所有的客户端,以控制他们进行相应的业务逻辑,后台管理人员在控制台上做一些操作,实际上就是修改Zookeeper上某些节点的数据,Zookeeper可以把数据变更以时间通知的形式发送给订阅客户端。
5.1.5 集群管理
Zookeeper的两大特性:
- 客户端如果对Zookeeper的数据节点注册Watcher监听,那么当该数据及该单内容或是其子节点列表发生变更时,Zookeeper服务器就会向订阅的客户端发送变更通知。
- 对在Zookeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么临时节点也会被自动删除。
- 变化的日志源机器
- 变化的收集器机器
5.1.6 Master选举
在分布式系统中,Master往往用来协调集群中其他系统单元,具有对分布式系统状态变更的决定权,如在读写分离的应用场景中,客户端的写请求往往是由Master来处理,或者其常常处理一些复杂的逻辑并将处理结果同步给其他系统单元。利用Zookeeper的强一致性,能够很好地保证在分布式高并发情况下节点的创建一定能够保证全局唯一性,即Zookeeper将会保证客户端无法重复创建一个已经存在的数据节点。
首先创建/master_election/2016-11-12节点,客户端集群每天会定时往该节点下创建临时节点,如/master_election/2016-11-12/binding,这个过程中,只有一个客户端能够成功创建,此时其变成master,其他节点都会在节点/master_election/2016-11-12上注册一个子节点变更的Watcher,用于监控当前的Master机器是否存活,一旦发现当前Master挂了,其余客户端将会重新进行Master选举。
5.1.7 分布式锁
分布式锁用于控制分布式系统之间同步访问共享资源的一种方式,可以保证不同系统访问一个或一组资源时的一致性,主要分为排它锁和共享锁。
排它锁又称为写锁或独占锁,若事务T1对数据对象O1加上了排它锁,那么在整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能再对这个数据对象进行任何类型的操作,直到T1释放了排它锁。
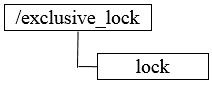
① 获取锁,在需要获取排它锁时,所有客户端通过调用接口,在/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。Zookeeper可以保证只有一个客户端能够创建成功,没有成功的客户端需要注册/exclusive_lock节点监听。
② 释放锁,当获取锁的客户端宕机或者正常完成业务逻辑都会导致临时节点的删除,此时,所有在/exclusive_lock节点上注册监听的客户端都会收到通知,可以重新发起分布式锁获取。
共享锁又称为读锁,若事务T1对数据对象O1加上共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都被释放。
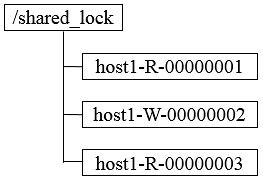
① 获取锁,在需要获取共享锁时,所有客户端都会到/shared_lock下面创建一个临时顺序节点,如果是读请求,那么就创建例如/shared_lock/host1-R-00000001的节点,如果是写请求,那么就创建例如/shared_lock/host2-W-00000002的节点。
② 判断读写顺序,不同事务可以同时对一个数据对象进行读写操作,而更新操作必须在当前没有任何事务进行读写情况下进行,通过Zookeeper来确定分布式读写顺序,大致分为四步。
1. 创建完节点后,获取/shared_lock节点下所有子节点,并对该节点变更注册监听。
2. 确定自己的节点序号在所有子节点中的顺序。
3. 对于读请求:若没有比自己序号小的子节点或所有比自己序号小的子节点都是读请求,那么表明自己已经成功获取到共享锁,同时开始执行读取逻辑,若有写请求,则需要等待。对于写请求:若自己不是序号最小的子节点,那么需要等待。
4. 接收到Watcher通知后,重复步骤1。
③ 释放锁,其释放锁的流程与独占锁一致。
上述共享锁的实现方案,可以满足一般分布式集群竞争锁的需求,但是如果机器规模扩大会出现一些问题,下面着重分析判断读写顺序的步骤3。

针对如上图所示的情况进行分析
1. host1首先进行读操作,完成后将节点/shared_lock/host1-R-00000001删除。
2. 余下4台机器均收到这个节点移除的通知,然后重新从/shared_lock节点上获取一份新的子节点列表。
3. 每台机器判断自己的读写顺序,其中host2检测到自己序号最小,于是进行写操作,余下的机器则继续等待。
4. 继续…
可以看到,host1客户端在移除自己的共享锁后,Zookeeper发送了子节点更变Watcher通知给所有机器,然而除了给host2产生影响外,对其他机器没有任何作用。大量的Watcher通知和子节点列表获取两个操作会重复运行,这样会造成系能鞥影响和网络开销,更为严重的是,如果同一时间有多个节点对应的客户端完成事务或事务中断引起节点小时,Zookeeper服务器就会在短时间内向其他所有客户端发送大量的事件通知,这就是所谓的羊群效应。
可以有如下改动来避免羊群效应。
1. 客户端调用create接口常见类似于/shared_lock/[Hostname]-请求类型-序号的临时顺序节点。
2. 客户端调用getChildren接口获取所有已经创建的子节点列表(不注册任何Watcher)。
3. 如果无法获取共享锁,就调用exist接口来对比自己小的节点注册Watcher。对于读请求:向比自己序号小的最后一个写请求节点注册Watcher监听。对于写请求:向比自己序号小的最后一个节点注册Watcher监听。
4. 等待Watcher通知,继续进入步骤2。
此方案改动主要在于:每个锁竞争者,只需要关注/shared_lock节点下序号比自己小的那个节点是否存在即可。
5.1.8 分布式队列
分布式队列可以简单分为先入先出队列模型和等待队列元素聚集后统一安排处理执行的Barrier模型。
① FIFO先入先出,先进入队列的请求操作先完成后,才会开始处理后面的请求。FIFO队列就类似于全写的共享模型,所有客户端都会到/queue_fifo这个节点下创建一个临时节点,如/queue_fifo/host1-00000001。
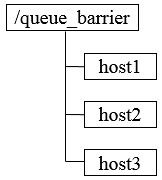
创建完节点后,按照如下步骤执行。
1. 通过调用getChildren接口来获取/queue_fifo节点的所有子节点,即获取队列中所有的元素。
2. 确定自己的节点序号在所有子节点中的顺序。
3. 如果自己的序号不是最小,那么需要等待,同时向比自己序号小的最后一个节点注册Watcher监听。
4. 接收到Watcher通知后,重复步骤1。
② Barrier分布式屏障,最终的合并计算需要基于很多并行计算的子结果来进行,开始时,/queue_barrier节点已经默认存在,并且将结点数据内容赋值为数字n来代表Barrier值,之后,所有客户端都会到/queue_barrier节点下创建一个临时节点,例如/queue_barrier/host1。
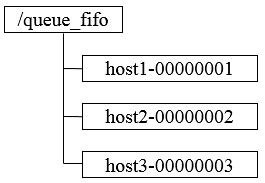
创建完节点后,按照如下步骤执行。
1. 通过调用getData接口获取/queue_barrier节点的数据内容,如10。
2. 通过调用getChildren接口获取/queue_barrier节点下的所有子节点,同时注册对子节点变更的Watcher监听。
3. 统计子节点的个数。
4. 如果子节点个数还不足10个,那么需要等待。
5. 接受到Wacher通知后,重复步骤3。
5.2、zk在大型分布式系统中的应用
5.2.1 Hadoop
Hadoop的核心是HDFS(Hadoop Distributed File System)和MapReduce,分别提供了对海量数据的存储和计算能力,后来,Hadoop又引入了全新MapReduce框架YARN(Yet Another Resource Negotiator)。在Hadoop中,Zookeeper主要用于实现HA(High Availability),这部分逻辑主要集中在Hadoop Common的HA模块中,HDFS的NameNode与YARN的ResourceManager都是基于此HA模块来实现自己的HA功能,YARN又使用了Zookeeper来存储应用的运行状态。
5.2.1.1 YARN
YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。其可以支持MapReduce模型,同时也支持Tez、Spark、Storm、Impala、Open MPI等。
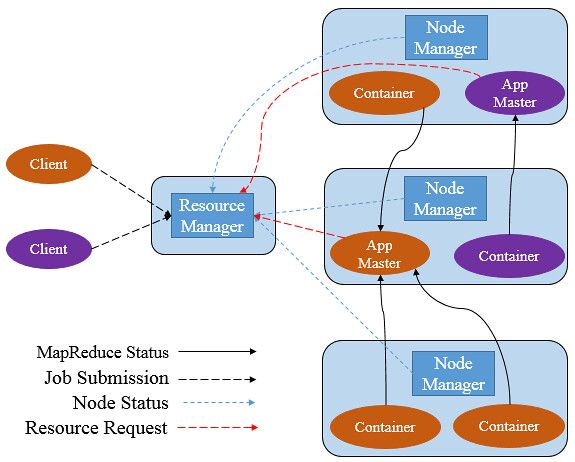
YARN主要由ResourceManager(RM)、NodeManager(NM)、ApplicationManager(AM)、Container四部分构成。其中,ResourceManager为全局资源管理器,负责整个系统的资源管理和分配。由YARN体系架构可以看到ResourceManager的单点问题,ResourceManager的工作状况直接决定了整个YARN架构是否可以正常运转。
5.2.1.2 ResourceManager HA
为了解决ResourceManager的单点问题,YARN设计了一套Active/Standby模式的ResourceManager HA架构。
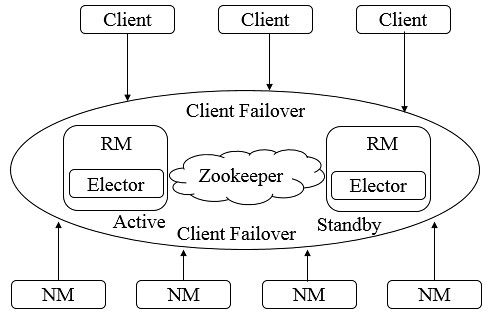
由上图可知,在运行期间,会有多个ResourceManager并存,并且其中只有一个ResourceManager处于Active状态,另外一些(允许一个或者多个)则处于Standby状态,当Active节点无法正常工作时,其余处于Standby状态的节点则会通过竞争选举产生新的Active节点。
5.2.1.3 主备切换
ResourceManager使用基于Zookeeper实现的ActiveStandbyElector组件来确定ResourceManager的状态。具体步骤如下
1. 创建锁节点。在Zookeeper上会有一个类似于/yarn-leader-election/pseudo-yarn-rm-cluster的锁节点,所有的ResourceManager在启动时,都会去竞争写一个Lock子节点(/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock),子节点类型为临时节点,利用Zookeeper的特性,创建成功的那个ResourceManager切换为Active状态,其余的为Standby状态。
2. 注册Watcher监听。所有Standby状态的ResourceManager都会向/yarn-leader-election/pseudo-yarn-rm-cluster/ActiveStandbyElectorLock节点注册一个节点变更监听,利用临时节点的特性,能够快速感知到Active状态的ResourceManager的运行情况。
3. 主备切换。当Active的ResourceManager无法正常工作时,其创建的Lock节点也会被删除,此时,其余各个Standby的ResourceManager都会收到通知,然后重复步骤1。
5.2.1.4 隔离(Fencing)
在分布式环境中,经常会出现诸如单机假死(机器由于网络闪断或是其自身由于负载过高,常见的有GC占用时间过长或CPU负载过高,而无法正常地对外进行及时响应)情况。假设RM集群由RM1和RM2两台机器构成,某一时刻,RM1发生了假死,此时,Zookeeper认为RM1挂了,然后进行主备切换,RM2会成为Active状态,但是在随后,RM1恢复了正常,其依然认为自己还处于Active状态,这就是分布式脑裂现象,即存在多个处于Active状态的RM工作,可以使用隔离来解决此类问题。
YARN引入了Fencing机制,借助Zookeeper的数据节点的ACL权限控制机制来实现不同RM之间的隔离。在上述主备切换时,多个RM之间通过竞争创建锁节点来实现主备状态的确定,此时,只需要在创建节点时携带Zookeeper的ACL信息,目的是为了独占该节点,以防止其他RM对该节点进行更新。
还是上述案例,若RM1出现假死,Zookeeper会移除其创建的节点,此时RM2会创建相应的锁节点并切换至Active状态,RM1恢复之后,会试图去更新Zookeeper相关数据,但是此时其没有权限更新Zookeeper的相关节点数据,因为节点不是由其创建的,于是就自动切换至Standby状态,这样就避免了脑裂现象的出现。
5.2.1.5 ResourceManager状态存储
在ResourceManager中,RMStateStore可以存储一些RM的内部状态信息,包括Application以及Attempts信息、Delegation Token及Version Information等,值得注意的是,RMStateStore的绝大多数状态信息都是不需要持久化存储的(如资源使用情况),因为其很容易从上下文信息中重构,,在存储方案设计中,提供了三种可能的实现。
1. 基于内存实现,一般用于日常开发测试。
2. 基于文件系统实现,如HDFS。
3. 基于Zookeeper实现。
由于存储的信息不是特别大,Hadoop官方建议基于Zookeeper来实现状态信息的存储,在Zookeeper中,ResourceManager的状态信息都被存储在/rmstore这个根节点下,其数据结构如下。
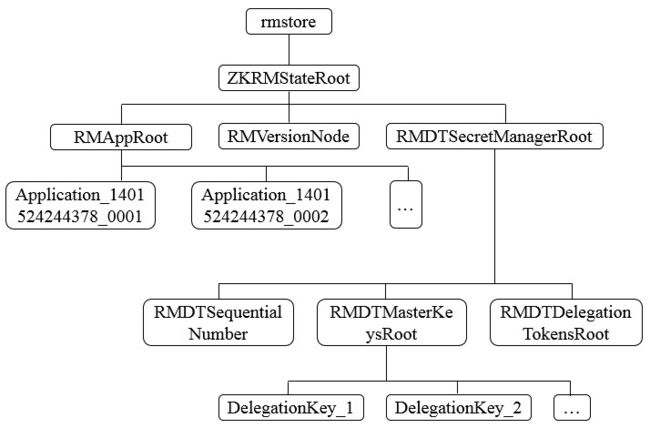
在RMAppRoot节点下存储的是与各个Application相关的信息,RMDTSecretManagerRoot存储的是与安全相关的Token信息。每个Active状态的ResourceManager在初始化节点都会从Zookeeper上读取到这些信息,并根据这些状态信息继续后续的处理。
5.2.2 HBase
省略,如需查看,请点击
5.2.3 Kafka
kafka是一个吞吐量极高的分布式消息系统,其整体设计是典型的发布与订阅系统模式,在Kafka集群中,没有中心主节点概念,所有服务器都是对等的,因此,可以在不做任何配置更改的情况下实现服务器的添加与删除,同样,消息的生产者和消费者也能够随意重启和机器的上下线。
生产者(Producer):消息产生的源头,负责生成消息并发送到Kafka服务器。
消费者(Consumer):消息的使用方,负责消费Kafka服务器上的消息。
主题(Topic):由用户定义并配置在Kafka服务端,用于建立生产者和消费者之间的订阅关系,生产者发送消息到指定Topic下,消费者从这个Topic中消费消息。
消息分区(Partition):一个Topic下会分为多个分区,如"kafka-test"这个Topic可以分为10个分区,分别由两台服务器提供,那么通常可以配置让每台服务器提供5个分区,假设服务器ID为0和1,那么分区为0-0、0-1、0-2、0-3、0-4和1-0、 1-1、1-2、1-3、1-4。消息分区机制和分区的数量与消费者的负载均衡机制有很大的关系。
服务器(Broker):用于存储信息,在消息中间件中通常被称为Broker。
消费者分组(Group):归组同类消费者,多个消费者可以共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者组成了消费者分组,拥有同一个分组名称,通常也被称为消费者集群。
偏移量(Offset):消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量。
5.2.3.1 Broker注册
Broker是分布式部署并且相互之间相互独立,但是需要有一个注册系统能够将整个集群中的Broker管理起来,此时就使用到了Zookeeper。在Zookeeper上会有一个专门用来进行Broker服务器列表记录的节点/brokers/ids。每个Broker在启动时,都会到Zookeeper上进行注册,即到/brokers/ids下创建属于自己的节点,如/brokers/ids/[0…N]。Kafka使用了全局唯一的数字来指代每个Broker服务器,不同的Broker必须使用不同的Broker ID进行注册,创建完节点后,每个Broker就会将自己的IP地址和端口信息记录到该节点中去。其中,Broker创建的节点类型是临时节点,一旦Broker宕机,则对应的临时节点也会被自动删除。
5.2.3.2 Topic注册
在Kafka中,同一个Topic的消息会被分成多个分区并将其分布在多个Broker上,这些分区信息及与Broker的对应关系也都是由Zookeeper在维护,由专门的节点来记录,如/borkers/topics。Kafka中每个Topic都会以/brokers/topics/[topic]的形式被记录,如/brokers/topics/login和/brokers/topics/search等。Broker服务器启动后,会到对应Topic节点(/brokers/topics)上注册自己的Broker ID并写入针对该Topic的分区总数,如/brokers/topics/login/3->2,这个节点表示Broker ID为3的一个Broker服务器,对于"login"这个Topic的消息,提供了2个分区进行消息存储,同样,这个分区节点也是临时节点。
5.2.3.3 生产者负载均衡
由于同一个Topic消息会被分区并将其分布在多个Broker上,因此,生产者需要将消息合理地发送到这些分布式的Broker上,那么如何实现生产者的负载均衡,Kafka支持传统的四层负载均衡,也支持Zookeeper方式实现负载均衡。
① 四层负载均衡,根据生产者的IP地址和端口来为其确定一个相关联的Broker。通常,一个生产者只会对应单个Broker,然后该生产者产生的消息都发往该Broker。这种方式逻辑简单,每个生产者不需要同其他系统建立额外的TCP连接,只需要和Broker维护单个TCP连接即可。但是,其无法做到真正的负载均衡,因为实际系统中的每个生产者产生的消息量及每个Broker的消息存储量都是不一样的,如果有些生产者产生的消息远多于其他生产者的话,那么会导致不同的Broker接收到的消息总数差异巨大,同时,生产者也无法实时感知到Broker的新增和删除。
② 使用Zookeeper进行负载均衡,由于每个Broker启动时,都会完成Broker注册过程,生产者会通过该节点的变化来动态地感知到Broker服务器列表的变更,这样就可以实现动态的负载均衡机制。
5.2.3.4 消费者负载均衡
与生产者类似,Kafka中的消费者同样需要进行负载均衡来实现多个消费者合理地从对应的Broker服务器上接收消息,每个消费者分组包含若干消费者,每条消息都只会发送给分组中的一个消费者,不同的消费者分组消费自己特定的Topic下面的消息,互不干扰。
5.2.3.5 消费分区与消费者的关系
对于每个消费者分组,Kafka都会为其分配一个全局唯一的Group ID,同一个消费者分组内部的所有消费者共享该ID。同时,Kafka为每个消费者分配一个Consumer ID,通常采用"Hostname:UUID"形式表示。在Kafka中,规定了每个消息分区有且只能同时有一个消费者进行消费,因此,需要在Zookeeper上记录消息分区与消费者之间的关系,每个消费者一旦确定了对一个消息分区的消费权力,需要将其Consumer ID 写入到对应消息分区的临时节点上,例如/consumers/[group_id]/owners/[topic]/[broker_id-partition_id],其中,[broker_id-partition_id]就是一个消息分区的标识,节点内容就是该消费分区上消息消费者的Consumer ID。
5.2.3.6 消息消费进度Offset记录
在消费者对指定消息分区进行消息消费的过程中,需要定时地将分区消息的消费进度Offset记录到Zookeeper上,以便在该消费者进行重启或者其他消费者重新接管该消息分区的消息消费后,能够从之前的进度开始继续进行消息消费。Offset在Zookeeper中由一个专门节点进行记录,其节点路径为/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id],节点内容就是Offset的值。
5.2.3.7 消费者注册
消费者服务器在初始化启动时加入消费者分组的步骤如下
① 注册到消费者分组。每个消费者服务器启动时,都会到Zookeeper的指定节点下创建一个属于自己的消费者节点,例如/consumers/[group_id]/ids/[consumer_id],完成节点创建后,消费者就会将自己订阅的Topic信息写入该临时节点。
② 对消费者分组中的消费者的变化注册监听。每个消费者都需要关注所属消费者分组中其他消费者服务器的变化情况,即对/consumers/[group_id]/ids节点注册子节点变化的Watcher监听,一旦发现消费者新增或减少,就触发消费者的负载均衡。
③ 对Broker服务器变化注册监听。消费者需要对/broker/ids/[0-N]中的节点进行监听,如果发现Broker服务器列表发生变化,那么就根据具体情况来决定是否需要进行消费者负载均衡。
④ 进行消费者负载均衡。为了让同一个Topic下不同分区的消息尽量均衡地被多个消费者消费而进行消费者与消息分区分配的过程,通常,对于一个消费者分组,如果组内的消费者服务器发生变更或Broker服务器发生变更,会发出消费者负载均衡。
5.2.3.8 负载均衡
Kafka借助Zookeeper上记录的Broker和消费者信息,采用消费者均衡算法进行负载均衡,其具体步骤如下。假设一个消息分组的每个消费者记为C1,C2,Ci,…,Cn。那么对于消费者Ci,其对应的消息分区分配策略如下:
1. 设置Pr为指定Topic所有的消息分区。
2. 设置Cg为统一消费者分组中的所有消费者。
3. 对Pr进行排序,使分布在同一个Broker服务器上的分区尽量靠在一起。
4. 对Cg进行排序。
5. 设置i为Ci在Cg中的位置索引,同时设置N = size (Pr) / size (Cg)。
6. 将编号为i * N ~ (i + 1) * N - 1的消息分区分配给Ci。
7. 重新更新Zookeeper上消息分区与消费者Ci的关系。
《从Paxos到zookeeper分布式一致性原理与实践》笔记
第6章ZooKeeper技术内幕
6.1 系统模型
6.1.1 数据模型
Zookeeper的数据节点称为ZNode,ZNode是Zookeeper中数据的最小单元,每个ZNode都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,称为树。

在Zookeeper中,事务是指能够改变Zookeeper服务器状态的操作,一般包括节点创建与删除,数据节点内容更新和客户端会话创建与失效,对于每个事务请求,Zookeeper都会为其分配一个全局唯一的事务ID,用ZXID表示,通常是64位的数字,每个ZXID对应一次更新操作,从这些ZXID中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序。
6.1.2 节点特性
在Zookeeper中,每个数据节点都是由生命周期的,类型不同则会不同的生命周期,节点类型可以分为持久节点(PERSISTENT)、临时节点(EPHEMERAL)、顺序节点(SEQUENTIAL)三大类,可以通过组合生成如下四种类型节点
1. 持久节点(PERSISTENT)。节点创建后便一直存在于Zookeeper服务器上,直到有删除操作来主动清楚该节点。
2. 持久顺序节点(PERSISTENT_SEQUENTIAL)。相比持久节点,其新增了顺序特性,每个父节点都会为它的第一级子节点维护一份顺序,用于记录每个子节点创建的先后顺序。在创建节点时,会自动添加一个数字后缀,作为新的节点名,该数字后缀的上限是整形的最大值。
3. 临时节点(EPEMERAL)。临时节点的生命周期与客户端会话绑定,客户端失效,节点会被自动清理。同时,Zookeeper规定不能基于临时节点来创建子节点,即临时节点只能作为叶子节点。
4. 临时顺序节点(EPEMERAL_SEQUENTIAL)。在临时节点的基础添加了顺序特性。
每个节点除了存储数据外,还存储了节点本身的一些状态信息,可通过get命令获取。
6.1.3 版本——保证分布式数据原子性操作
每个数据节点都具有三种类型的版本信息,对数据节点的任何更新操作都会引起版本号的变化。
version-- 当前数据节点数据内容的版本号
cversion-- 当前数据子节点的版本号
aversion-- 当前数据节点ACL变更版本号
上述各版本号都是表示修改次数,如version为1表示对数据节点的内容变更了一次。即使前后两次变更并没有改变数据内容,version的值仍然会改变。version可以用于写入验证,类似于CAS。
6.1.4 Watcher——数据变更的通知
Zookeeper使用Watcher机制实现分布式数据的发布/订阅功能。
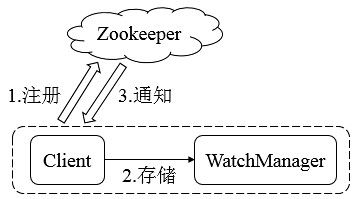
Zookeeper的Watcher机制主要包括客户端线程、客户端WatcherManager、Zookeeper服务器三部分。客户端在向Zookeeper服务器注册的同时,会将Watcher对象存储在客户端的WatcherManager当中。当Zookeeper服务器触发Watcher事件后,会向客户端发送通知,客户端线程从WatcherManager中取出对应的Watcher对象来执行回调逻辑。
6.1.5 ACL——保障数据的安全
Zookeeper内部存储了分布式系统运行时状态的元数据,这些元数据会直接影响基于Zookeeper进行构造的分布式系统的运行状态,如何保障系统中数据的安全,从而避免因误操作而带来的数据随意变更而导致的数据库异常十分重要,Zookeeper提供了一套完善的ACL权限控制机制来保障数据的安全。
我们可以从三个方面来理解ACL机制:权限模式(Scheme)、授权对象(ID)、权限(Permission),通常使用"**scheme : id : permission **"来标识一个有效的ACL信息。
权限模式用来确定权限验证过程中使用的检验策略,有如下四种模式:
1. IP,通过IP地址粒度来进行权限控制,如"ip:192.168.0.110"表示权限控制针对该IP地址,同时IP模式可以支持按照网段方式进行配置,如"ip:192.168.0.1/24"表示针对192.168.0.*这个网段进行权限控制。
2. Digest,使用"username:password"形式的权限标识来进行权限配置,便于区分不同应用来进行权限控制。Zookeeper会对其进行SHA-1加密和BASE64编码。
3. World,最为开放的权限控制模式,数据节点的访问权限对所有用户开放。
4. Super,超级用户,是一种特殊的Digest模式,超级用户可以对任意Zookeeper上的数据节点进行任何操作。
授权对象是指权限赋予的用户或一个指定实体,如IP地址或机器等。不同的权限模式通常有不同的授权对象。
权限是指通过权限检查可以被允许执行的操作,Zookeeper对所有数据的操作权限分为CREATE(节点创建权限)、DELETE(节点删除权限)、READ(节点读取权限)、WRITE(节点更新权限)、ADMIN(节点管理权限),这5种权限简写为crwda。
自定义权限控制
权限控制器需要实现AuthenticationProvider接口,注册自定义权限控制器通过在zoo.cfg配置文件中配置如下配置项:
authProvider.1=com.zkbook.CustomAuthenticationProvider
6.2 序列化与协议
Zookeeper的客户端与服务端之间会进行一系列的网络通信来实现数据传输,Zookeeper使用Jute组件来完成数据的序列化和反序列化操作。
6.2.1 Jute介绍
Jute是Zookeeper底层序列化组件,其用于Zookeeper进行网络数据传输和本地磁盘数据存储的序列化和反序列化工作。
在Zookeeper的src文件夹下有zookeeper.jute文件,定义了所有的实体类的所属包名、类名及类的所有成员变量和类型,该文件会在源代码编译时,Jute会使用不同的代码生成器为这些类定义生成实际编程语言的类文件,如java语言生成的类文件保存在src/java/generated目录下,每个类都会实现Record接口。
6.2.2 使用Jute进行序列化
6.2.3 深入Jute
6.2.4 通信协议
基于TCP/IP协议,Zookeeper实现了自己的通信协议来玩按成客户端与服务端、服务端与服务端之间的网络通信,对于请求,主要包含请求头和请求体,对于响应,主要包含响应头和响应体。

6.2.4.1 请求协议
对于请求协议而言,如下为获取节点数据请求的完整协议定义

class RequestHeader {
int xid;
int type;
}
从zookeeper.jute中可知RequestHeader包含了xid和type,xid用于记录客户端请求发起的先后序号,用来确保单个客户端请求的响应顺序,type代表请求的操作类型,如创建节点(OpCode.create)、删除节点(OpCode.delete)、获取节点数据(OpCode.getData)。
协议的请求主体内容部分,包含了请求的所有操作内容,不同的请求类型请求体不同。对于会话创建而言,其请求体如下
class ConnectRequest {
int protocolVersion;
long lastZxidSeen;
int timeOut;
long sessionId;
buffer passwd;
}
Zookeeper客户端和服务器在创建会话时,会发送ConnectRequest请求,该请求包含协议版本号protocolVersion、最近一次接收到服务器ZXID lastZxidSeen、会话超时时间timeOut、会话标识sessionId和会话密码passwd。
对于获取节点数据而言,其请求体如下
class GetDataRequest {
ustring path;
boolean watch;
}
Zookeeper客户端在向服务器发送节点数据请求时,会发送GetDataRequest请求,该请求包含了数据节点路径path、是否注册Watcher的标识watch。
对于更新节点数据而言,其请求体如下
class SetDataRequest {
ustring path;
buffer data;
int version;
}
Zookeeper客户端在向服务器发送更新节点数据请求时,会发送SetDataRequest请求,该请求包含了数据节点路径path、数据内容data、节点数据的期望版本号version。
针对不同的请求类型,Zookeeper都会定义不同的请求体,可以在zookeeper.jute中查看。
6.2.4.2 响应协议
对于响应协议而言,如下为获取节点数据响应的完整协议定义
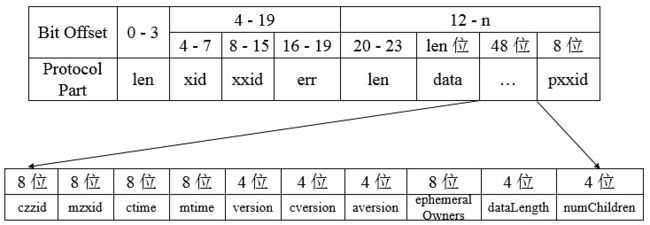
响应头中包含了每个响应最基本的信息,包括xid、zxid和err:
class ReplyHeader {
int xid;
long zxid;
int err;
}
xid与请求头中的xid一致,zxid表示Zookeeper服务器上当前最新的事务ID,err则是一个错误码,表示当请求处理过程出现异常情况时,就会在错误码中标识出来,常见的包括处理成功(Code.OK)、节点不存在(Code.NONODE)、没有权限(Code.NOAUTH)。
协议的响应主体内容部分,包含了响应的所有数据,不同的响应类型请求体不同。对于会话创建而言,其响应体如下
class ConnectResponse {
int protocolVersion;
int timeOut;
long sessionId;
buffer passwd;
}
针对客户端的会话创建请求,服务端会返回客户端一个ConnectResponse响应,该响应体包含了版本号protocolVersion、会话的超时时间timeOut、会话标识sessionId和会话密码passwd。
对于获取节点数据而言,其响应体如下
class GetDataResponse {
buffer data;
org.apache.zookeeper.data.Stat stat;
}
针对客户端的获取节点数据请求,服务端会返回客户端一个GetDataResponse响应,该响应体包含了数据节点内容data、节点状态stat。
对于更新节点数据而言,其响应体如下
class SetDataResponse {
org.apache.zookeeper.data.Stat stat;
}
针对客户端的更新节点数据请求,服务端会返回客户端一个SetDataResponse响应,该响应体包含了最新的节点状态stat。
针对不同的响应类型,Zookeeper都会定义不同的响应体,可以在zookeeper.jute中查看。
6.2.5 stat状态说明
stat对象状态属性说明:
1、czxid:即created zxid,表示该数据节点被创建时的事务id
2、mzxid:即modified zxid,表示该节点最后一次被更新时的事务id
3、ctime:即created time,表示节点被创建的时间
4、mtime:即modified time,表示该节点最后一次被更新的时间
5、version:数据节点的版本号
6、cversion:子节点的版本号
7、aversion:节点的acl版本号
8、ephemeralOwner:创建该临时节点的会话的sessionid,如果该节点是持久节点,那么这个属性值为0
9、dataLength:数据内容的长度
10、numChildren:当前节点的子节点个数
11、pzxid:表示该节点的子节点列表最后一次被修改时的事务id,注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid
在一个数据节点/zk-book被创建完毕后,节点的version值是0,表示的含义是“当前节点自从创建之后,被更新过0次”。如果现在对该节点的数据内容
进行更新操作,那么随后,version值就会变成1,同时需要注意的是,其表示的是对数据节点数据内容的变更次数,强调的是变更次数,因此即使前后
两次变更并没有使得数据内容的值发生变化,version的值任然会变更。
6.3 客户端
客户端是开发人员使用Zookeeper最主要的途径,很有必要弄懂客户端是如何与服务端通信的。
Zookeeper客户端主要由如下核心部件构成。
1. Zookeeper实例,客户端入口。
2. ClientWatchManager, 客户端Watcher管理器。
3. HostProvider,客户端地址列表管理器。
4. ClientCnxn,客户端核心线程,内部包含了SendThread和EventThread两个线程,SendThread为I/O线程,主要负责Zookeeper客户端和服务器之间的网络I/O通信;EventThread为事件线程,主要负责对服务端事件进行处理。
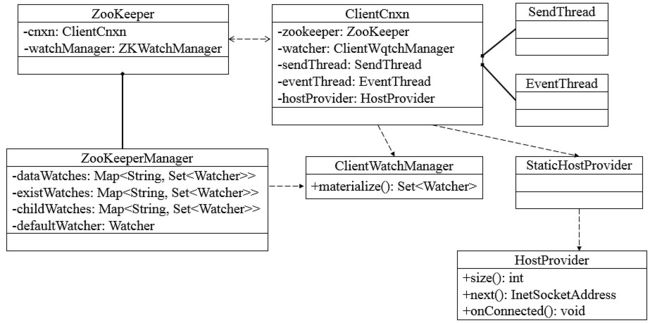
Zookeeper客户端初始化与启动环节,就是Zookeeper对象的实例化过程。客户端在初始化和启动过程中大体可以分为如下3个步骤
1. 设置默认Watcher
2. 设置Zookeeper服务器地址列表
3. 创建ClientCnxn。
若在Zookeeper构造方法中传入Watcher对象时,那么Zookeeper就会将该Watcher对象保存在ZKWatcherManager的defaultWatcher中,并作为整个客户端会话期间的默认Watcher。
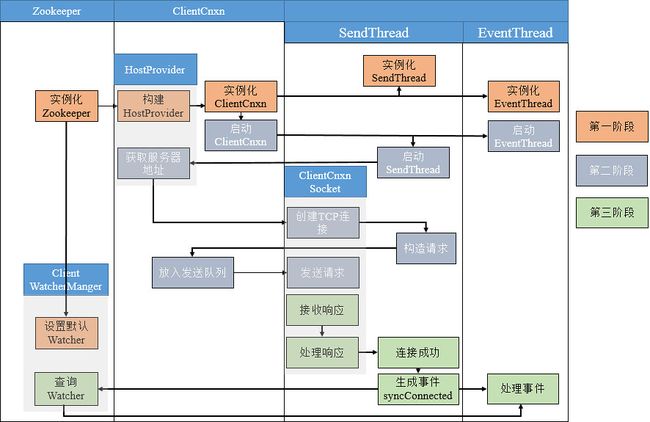
6.3.1 一次会话的创建过程
下图表示了客户端与服务端会话建立的整个过程,包括初始化阶段(第一阶段)、会话创建阶段(第二阶段)、响应处理阶段(第三阶段)三个阶段。
6.3.2 服务器地址列表
在实例化Zookeeper时,用户传入Zookeeper服务器地址列表,如192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181,此时,Zookeeper客户端在连接服务器的过程中,是如何从这个服务器列表中选择服务器的呢?Zookeeper收到服务器地址列表后,会解析出chrootPath和保存服务器地址列表。
1. Chroot,每个客户端可以设置自己的命名空间,若客户端设置了Chroot,此时,该客户端对服务器的任何操作都将被限制在自己的命名空间下,如设置Choot为/app/X,那么该客户端的所有节点路径都是以/app/X为根节点。
2. 地址列表管理,Zookeeper使用StaticHostProvider打散服务器地址(shuffle),并将服务器地址形成一个环形循环队列,然后再依次取出服务器地址。
6.3.3 ClientCnxn:网络I/O
ClientCnxn是Zookeeper客户端中负责维护客户端与服务端之间的网络连接并进行一系列网络通信的核心工作类,Packet是ClientCnxn内部定义的一个堆协议层的封装,用作Zookeeper中请求和响应的载体。Packet包含了请求头(requestHeader)、响应头(replyHeader)、请求体(request)、响应体(response)、节点路径(clientPath/serverPath)、注册的Watcher(watchRegistration)等信息,然而,并非Packet中所有的属性都在客户端与服务端之间进行网络传输,只会将requestHeader、request、readOnly三个属性序列化,并生成可用于底层网络传输的ByteBuffer,其他属性都保存在客户端的上下文中,不会进行与服务端之间的网络传输。
ClientCnxn维护着 outgoingQueue(客户端的请求发送队列 和 pendingQueue(服务端响应的等待队列),outgoingQueue专门用于存储那些需要发送到服务端的Packet集合,pendingQueue用于存储那些已经从客户端发送到服务端的,但是需要等待服务端响应的Packet集合。
在正常情况下,会从outgoingQueue中取出一个可发送的Packet对象,同时生成一个客户端请求序号XID并将其设置到Packet请求头中去,然后序列化后再发送,请求发送完毕后,会立即将该Packet保存到pendingQueue中,以便等待服务端响应返回后进行相应的处理。
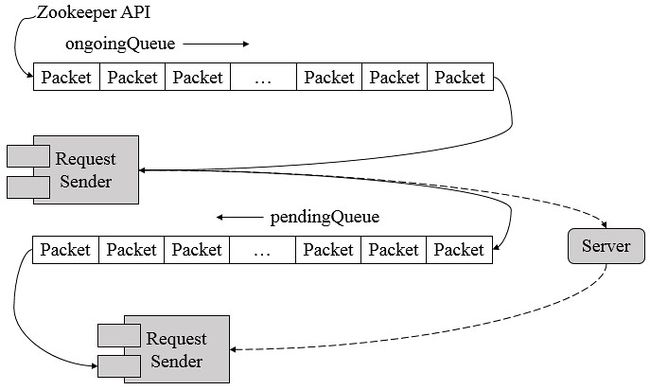
客户端获取到来自服务端的完整响应数据后,根据不同的客户端请求类型,会进行不同的处理。
1. 若检测到此时客户端尚未进行初始化,那么说明当前客户端与服务端之间正在进行会话创建,直接将接收的ByteBuffer序列化成ConnectResponse对象。
2. 若当前客户端已经处于正常会话周期,并且接收到服务端响应是一个事件,那么将接收的ByteBuffer序列化成WatcherEvent对象,并将该事件放入待处理队列中。
3. 若是一个常规请求(Create、GetData、Exist等),那么从pendingQueue队列中取出一个Packet来进行相应处理。首先会检验响应中的XID来确保请求处理的顺序性,然后再将接收到的ByteBuffer序列化成Response对象。
SendThread是客户端ClientCnxn内部的一个核心I/O调度线程,用于管理客户端与服务端之间的所有网络I/O操作,在Zookeeper客户端实际运行中,SendThread的作用如下
1. 维护了客户端与服务端之间的会话生命周期(通过一定周期频率内向服务端发送PING包检测心跳),如果会话周期内客户端与服务端出现TCP连接断开,那么就会自动且透明地完成重连操作。
2. 管理了客户端所有的请求发送和响应接收操作,其将上层客户端API操作转换成相应的请求协议并发送到服务端,并完成对同步调用的返回和异步调用的回调。
3. 将来自服务端的事件传递给EventThread去处理。
EventThread是客户端ClientCnxn内部的一个事件处理线程,负责客户端的事件处理,并触发客户端注册的Watcher监听。EventThread中的watingEvents队列用于临时存放那些需要被触发的Object,包括客户端注册的Watcher和异步接口中注册的回调器AsyncCallback。同时,EventThread会不断地从watingEvents中取出Object,识别具体类型(Watcher或AsyncCallback),并分别调用process和processResult接口方法来实现对事件的触发和回调。
6.4 会话
客户端与服务端之间任何交互操作都与会话息息相关,如临时节点的生命周期、客户端请求的顺序执行、Watcher通知机制等。Zookeeper的连接与会话就是客户端通过实例化Zookeeper对象来实现客户端与服务端创建并保持TCP连接的过程.
6.4.1 会话状态
在Zookeeper客户端与服务端成功完成连接创建后,就创建了一个会话,Zookeeper会话在整个运行期间的生命周期中,会在不同的会话状态中之间进行切换,这些状态可以分为CONNECTING、CONNECTED、RECONNECTING、RECONNECTED、CLOSE等。
一旦客户端开始创建Zookeeper对象,那么客户端状态就会变成CONNECTING状态,同时客户端开始尝试连接服务端,连接成功后,客户端状态变为CONNECTED,通常情况下,由于断网或其他原因,客户端与服务端之间会出现断开情况,一旦碰到这种情况,Zookeeper客户端会自动进行重连服务,同时客户端状态再次变成CONNCTING,直到重新连上服务端后,状态又变为CONNECTED,在通常情况下,客户端的状态总是介于CONNECTING和CONNECTED之间。但是,如果出现诸如会话超时、权限检查或是客户端主动退出程序等情况,客户端的状态就会直接变更为CLOSE状态。
6.4.2 会话创建
Session是Zookeeper中的会话实体,代表了一个客户端会话,其包含了如下四个属性
1. sessionID。会话ID,唯一标识一个会话,每次客户端创建新的会话时,Zookeeper都会为其分配一个全局唯一的sessionID。
2. TimeOut。会话超时时间,客户端在构造Zookeeper实例时,会配置sessionTimeout参数用于指定会话的超时时间,Zookeeper客户端向服务端发送这个超时时间后,服务端会根据自己的超时时间限制最终确定会话的超时时间。
3. TickTime。下次会话超时时间点,为了便于Zookeeper对会话实行"分桶策略"管理,同时为了高效低耗地实现会话的超时检查与清理,Zookeeper会为每个会话标记一个下次会话超时时间点,其值大致等于当前时间加上TimeOut。
4. isClosing。标记一个会话是否已经被关闭,当服务端检测到会话已经超时失效时,会将该会话的isClosing标记为"已关闭",这样就能确保不再处理来自该会话的心情求了。
Zookeeper为了保证请求会话的全局唯一性,在SessionTracker初始化时,调用initializeNextSession方法生成一个sessionID,之后在Zookeeper运行过程中,会在该sessionID的基础上为每个会话进行分配,初始化算法如下
public static long initializeNextSession(long id) {
long nextSid = 0;
// 无符号右移8位使为了避免左移24后,再右移8位出现负数而无法通过高8位确定sid值
nextSid = (System.currentTimeMillis() << 24) >>> 8;
nextSid = nextSid | (id << 56);
return nextSid;
}
其中的id表示配置在myid文件中的值,通常是一个整数,如1、2、3。该算法的高8位确定了所在机器,后56位使用当前时间的毫秒表示进行随机。SessionTracker是Zookeeper服务端的会话管理器,负责会话的创建、管理和清理等工作。
6.4.3 会话管理
Zookeeper的会话管理主要是通过SessionTracker来负责,其采用了分桶策略(将类似的会话放在同一区块中进行管理)进行管理,以便Zookeeper对会话进行不同区块的隔离处理以及同一区块的统一处理。
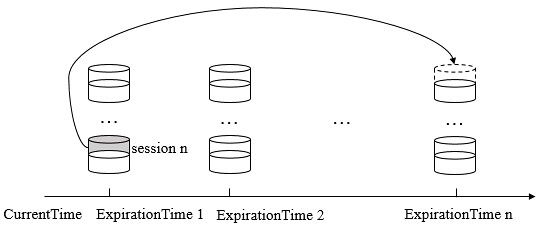
Zookeeper将所有的会话都分配在不同的区块一种,分配的原则是每个会话的下次超时时间点(ExpirationTime)。ExpirationTime指该会话最近一次可能超时的时间点。同时,Zookeeper Leader服务器在运行过程中会定时地进行会话超时检查,时间间隔是ExpirationInterval,默认为tickTime的值,ExpirationTime的计算时间如下
ExpirationTime = ((CurrentTime + SessionTimeOut) / ExpirationInterval + 1) * ExpirationInterval
会了保持客户端会话的有效性,客户端会在会话超时时间过期范围内向服务端发送PING请求来保持会话的有效性(心跳检测)。同时,服务端需要不断地接收来自客户端的心跳检测,并且需要重新激活对应的客户端会话,这个重新激活过程称为TouchSession。会话激活不仅能够使服务端检测到对应客户端的存货性,同时也能让客户端自己保持连接状态,其流程如下
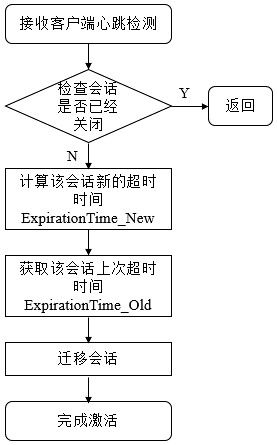
如上图所示,整个流程分为四步
1. 检查该会话是否已经被关闭。若已经被关闭,则直接返回即可。
2. 计算该会话新的超时时间ExpirationTime_New。使用上面提到的公式计算下一次超时时间点。
3. 获取该会话上次超时时间ExpirationTime_Old。计算该值是为了定位其所在的区块。
3. 迁移会话。将该会话从老的区块中取出,放入ExpirationTime_New对应的新区块中。
在上面会话激活过程中,只要客户端发送心跳检测,服务端就会进行一次会话激活,心跳检测由客户端主动发起,以PING请求形式向服务端发送,在Zookeeper的实际设计中,只要客户端有请求发送到服务端,那么就会触发一次会话激活,以下两种情况都会触发会话激活。
1. 客户端向服务端发送请求,包括读写请求,就会触发会话激活。
2. 客户端发现在sessionTimeout/3时间内尚未和服务端进行任何通信,那么就会主动发起PING请求,服务端收到该请求后,就会触发会话激活。
对于会话的超时检查而言,Zookeeper使用SessionTracker来负责,SessionTracker使用单独的线程(超时检查线程)专门进行会话超时检查,即逐个一次地对会话桶中剩下的会话进行清理。如果一个会话被激活,那么Zookeeper就会将其从上一个会话桶迁移到下一个会话桶中,如ExpirationTime 1 的session n 迁移到ExpirationTime n 中,此时ExpirationTime 1中留下的所有会话都是尚未被激活的,超时检查线程就定时检查这个会话桶中所有剩下的未被迁移的会话,超时检查线程只需要在这些指定时间点(ExpirationTime 1、ExpirationTime 2…)上进行检查即可,这样提高了检查的效率,性能也非常好。
6.4.4 会话清理
当SessionTracker的会话超时线程检查出已经过期的会话后,就开始进行会话清理工作,大致可以分为如下七步。
1. 标记会话状态为已关闭。由于会话清理过程需要一段时间,为了保证在此期间不再处理来自该客户端的请求,SessionTracker会首先将该会话的isClosing标记为true,这样在会话清理期间接收到该客户端的心情求也无法继续处理了。
2. 发起会话关闭请求。为了使对该会话的关闭操作在整个服务端集群都生效,Zookeeper使用了提交会话关闭请求的方式,并立即交付给PreRequestProcessor进行处理。
3. 收集需要清理的临时节点。一旦某个会话失效后,那么和该会话相关的临时节点都需要被清理,因此,在清理之前,首先需要将服务器上所有和该会话相关的临时节点都整理出来。Zookeeper在内存数据库中会为每个会话都单独保存了一份由该会话维护的所有临时节点集合,在Zookeeper处理会话关闭请求之前,若正好有以下两类请求到达了服务端并正在处理中。
· 节点删除请求,删除的目标节点正好是上述临时节点中的一个。
· 临时节点创建请求,创建的目标节点正好是上述临时节点中的一个。
对于第一类请求,需要将所有请求对应的数据节点路径从当前临时节点列表中移出,以避免重复删除,对于第二类请求,需要将所有这些请求对应的数据节点路径添加到当前临时节点列表中,以删除这些即将被创建但是尚未保存到内存数据库中的临时节点。
4. 添加节点删除事务变更。完成该会话相关的临时节点收集后,Zookeeper会逐个将这些临时节点转换成"节点删除"请求,并放入事务变更队列outstandingChanges中。
5. 删除临时节点。FinalRequestProcessor会触发内存数据库,删除该会话对应的所有临时节点。
6. 移除会话。完成节点删除后,需要将会话从SessionTracker中删除。
7. 关闭NIOServerCnxn。最后,从NIOServerCnxnFactory找到该会话对应的NIOServerCnxn,将其关闭。
6.4.5 重连
6.4.5.1 重连状态(CONNECTED & EXPIRED)
当客户端与服务端之间的网络连接断开时,Zookeeper客户端会自动进行反复的重连,直到最终成功连接上Zookeeper集群中的一台机器。此时,再次连接上服务端的客户端有可能处于以下两种状态之一
1. CONNECTED。如果在会话超时时间内重新连接上集群中一台服务器 。
2. EXPIRED。如果在会话超时时间以外重新连接上,那么服务端其实已经对该会话进行了会话清理操作,此时会话被视为非法会话。
在客户端与服务端之间维持的是一个长连接,在sessionTimeout时间内,服务端会不断地检测该客户端是否还处于正常连接,服务端会将客户端的每次操作视为一次有效的心跳检测来反复地进行会话激活。因此,在正常情况下,客户端会话时一直有效的。然而,当客户端与服务端之间的连接断开后,用户在客户端可能主要看到两类异常:CONNECTION_LOSS(连接断开)和SESSION_EXPIRED(会话过期)。
6.4.5.2 重连异常: CONNECTION_LOSS(连接断开)和SESSION_EXPIRED(会话过期)
连接断开connection_loss:
有时因为网络闪断导致客户端与服务器断开连接,或是因为客户端当前连接的服务器出现问题导致连接断开,我么称“客户端与服务器断开连接”现象,即connection_loss。在这种情况下,zookeeper客户端会自动从地址列表中重新获取新的地址并尝试进行重新连接,直到最终成功连接上服务器。
举个例子:某应用在使用zookeeper客户端进行setData操作时,正好出现了connection_loss现象,那么客户端会记录接收到事件:none-disconnected通知,同时会抛出异常ConnectionLossException。这时,我们的应用需要做的事情是捕获异常,然后等待zookeeper的客户端自动完成重连,一旦客户端成功连上一台zookeeper机器后,那么客户端就会收到事件none-syncconnnected通知,之后就可以重试刚才的setData操作。
会话失效session_expired
通常发生在connection_loss期间,客户端和服务器连接断开后,由于重连期间耗时过长,超过了会话超时时间限制后还没有成功连接上服务器,那么服务器认为这个会话已经结束了,就会开始进行会话清理,但是另一方面,该客户端本身不知道会话已经失效了,并且其客户端状态还是disconnected。之后,如果客户端重新连接上了服务器,服务器会告知客户端会话已经失效,在这时,用户就需要重新实例化一个zookeeper对象,并看应用的复杂程度,重新恢复临时数据。
会话转移session_moved
是指客户端会话从一台服务器转移到另一台服务器上,假设客户端和服务器s1之间的连接断开后,如果通过尝试重连后,成功连接上了新的服务器s2并且延续了有效会话,那么就可以说会话从s1转移到了s2上。
6.5 服务器启动
服务端整体架构如下
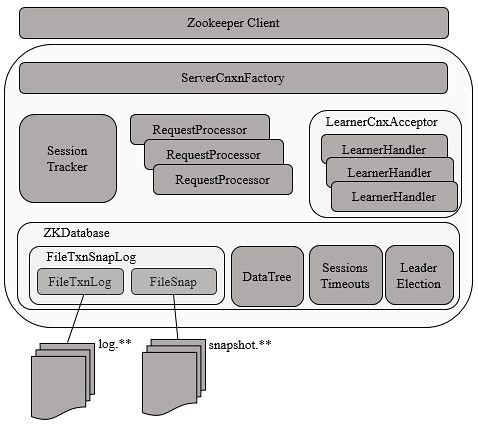
Zookeeper服务器的启动,大致可以分为以下五个步骤
1. 配置文件解析。
2. 初始化数据管理器。
3. 初始化网络I/O管理器。
4. 数据恢复。
5. 对外服务。
6.5.1 单机版服务器启动
单机版服务器的启动其流程图如下

上图的过程可以分为预启动和初始化过程。
6.5.1.1 单机版服务器启动 - 预启动
1. 统一由QuorumPeerMain作为启动类。无论单机或集群,在zkServer.cmd和zkServer.sh中都配置了QuorumPeerMain作为启动入口类。
2. 解析配置文件zoo.cfg。zoo.cfg配置运行时的基本参数,如tickTime、dataDir、clientPort等参数。
3. 创建并启动历史文件清理器DatadirCleanupManager。对事务日志和快照数据文件进行定时清理。
4. 判断当前是集群模式还是单机模式启动。若是单机模式,则委托给ZooKeeperServerMain进行启动。
5. 再次进行配置文件zoo.cfg的解析。
6. 创建服务器实例ZooKeeperServer。Zookeeper服务器首先会进行服务器实例的创建,然后对该服务器实例进行初始化,包括连接器、内存数据库、请求处理器等组件的初始化。
6.5.1.2 单机版服务器启动 - 初始化
1. 创建服务器统计器ServerStats。ServerStats是Zookeeper服务器运行时的统计器。
2. 创建Zookeeper数据管理器FileTxnSnapLog。FileTxnSnapLog是Zookeeper上层服务器和底层数据存储之间的对接层,提供了一系列操作数据文件的接口,如事务日志文件和快照数据文件。Zookeeper根据zoo.cfg文件中解析出的快照数据目录dataDir和事务日志目录dataLogDir来创建FileTxnSnapLog。
3. 设置服务器tickTime和会话超时时间限制。
4. 创建ServerCnxnFactory。通过配置系统属性zookeper.serverCnxnFactory来指定使用Zookeeper自己实现的NIO还是使用Netty框架作为Zookeeper服务端网络连接工厂。
5. 初始化ServerCnxnFactory。Zookeeper会初始化Thread作为ServerCnxnFactory的主线程,然后再初始化NIO服务器。
6. 启动ServerCnxnFactory主线程。进入Thread的run方法,此时服务端还不能处理客户端请求。
7. 恢复本地数据。启动时,需要从本地快照数据文件和事务日志文件进行数据恢复。
8. 创建并启动会话管理器。Zookeeper会创建会话管理器SessionTracker进行会话管理。
9. 初始化Zookeeper的请求处理链。Zookeeper请求处理方式为责任链模式的实现。会有多个请求处理器依次处理一个客户端请求,在服务器启动时,会将这些请求处理器串联成一个请求处理链。
10. 注册JMX服务。Zookeeper会将服务器运行时的一些信息以JMX的方式暴露给外部。
11. 注册Zookeeper服务器实例。将Zookeeper服务器实例注册给ServerCnxnFactory,之后Zookeeper就可以对外提供服务。
至此,单机版的Zookeeper服务器启动完毕。
6.5.2 集群版服务器启动
单机和集群服务器的启动在很多地方是一致的,其流程图如下
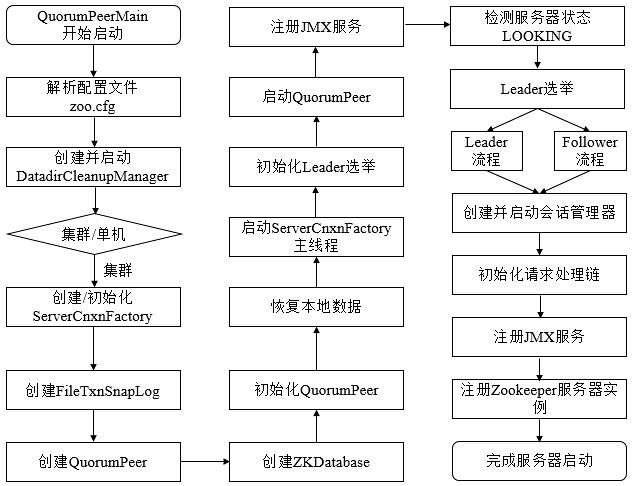
上图的过程可以分为预启动、初始化、Leader选举、Leader与Follower启动期交互过程、Leader与Follower启动等过程。
6.5.2.1 集群版服务器启动 - 预启动
1. 统一由QuorumPeerMain作为启动类。
2. 解析配置文件zoo.cfg。
3. 创建并启动历史文件清理器DatadirCleanupFactory。
4. 判断当前是集群模式还是单机模式的启动。在集群模式中,在zoo.cfg文件中配置了多个服务器地址,可以选择集群启动。
6.5.2.2 集群版服务器启动 - 初始化
1. 创建ServerCnxnFactory。
2. 初始化ServerCnxnFactory。
3. 创建Zookeeper数据管理器FileTxnSnapLog。
4. 创建QuorumPeer实例。Quorum是集群模式下特有的对象,是Zookeeper服务器实例(ZooKeeperServer)的托管者,QuorumPeer代表了集群中的一台机器,在运行期间,QuorumPeer会不断检测当前服务器实例的运行状态,同时根据情况发起Leader选举。
5. 创建内存数据库ZKDatabase。ZKDatabase负责管理ZooKeeper的所有会话记录以及DataTree和事务日志的存储。
6. 初始化QuorumPeer。将核心组件如FileTxnSnapLog、ServerCnxnFactory、ZKDatabase注册到QuorumPeer中,同时配置QuorumPeer的参数,如服务器列表地址、Leader选举算法和会话超时时间限制等。
7. 恢复本地数据。
8. 启动ServerCnxnFactory主线程。
6.6 Leader选举
1. 初始化Leader选举。集群模式特有,Zookeeper首先会根据自身的服务器ID(SID)、最新的ZXID(lastLoggedZxid)和当前的服务器epoch(currentEpoch)来生成一个初始化投票,在初始化过程中,每个服务器都会给自己投票。然后,根据zoo.cfg的配置,创建相应Leader选举算法实现,Zookeeper提供了三种默认算法(LeaderElection、AuthFastLeaderElection、FastLeaderElection),可通过zoo.cfg中的electionAlg属性来指定,但现只支持FastLeaderElection选举算法。在初始化阶段,Zookeeper会创建Leader选举所需的网络I/O层QuorumCnxManager,同时启动对Leader选举端口的监听,等待集群中其他服务器创建连接。
2. 注册JMX服务。
3. 检测当前服务器状态。运行期间,QuorumPeer会不断检测当前服务器状态。在正常情况下,Zookeeper服务器的状态在LOOKING、LEADING、FOLLOWING/OBSERVING之间进行切换。在启动阶段,QuorumPeer的初始状态是LOOKING,因此开始进行Leader选举。
4. Leader选举。通过投票确定Leader,其余机器称为Follower和Observer。具体算法在后面会给出。
6.6.1 Leader选举概述
6.6.1.1 服务器启动时期的Leader选举
1、每个server会发出一个投票,由于是初始情况,因此对于server1和server2来说,都会将自己作为leader服务器来投票,每次投票包含的最基本的元素为:所推举的服务器的myid和zxid,我们以(myid, zxid)的形式来表示。因为是初始化阶段,因此无论是server1和是server2都会投给自己,即server1的投票为(1, 0),server2的投票为(2, 0),然后各自将这个投票发给集群中其它所有机器。
2、接收来自各个服务器的投票
每个服务器都会接收来自其它服务器的投票,接收到后会判断该投票的有效性,包括检查是否是本轮投票,是否来自looking状态的服务器。
3、处理投票
在接收到来自其它服务器的投票后,针对每一个投票,服务器都需要将别人的投票和自己的投票进行pk,pk的规则如下:优先检查zxid,zxid大的服务器优先作为leader。如果zxid相同,那么比较myid,myid大的服务器作为leader服务器。
现在我们来看server1和server2实际是如何进行投票的,对于server1来说,他自己的投票是(1, 0),而接收到的投票为(2, 0)。首先会对比两者的zxid,因为都是0,所以接下来会比较两者的myid,server1发现接收到的投票中的myid是2,大于自己,于是就会更新自己的投票为(2, 0),然后重新将投票发出去,而对于server2,不需要更新自己的投票信息,只是再一次向集群中的所有机器发出上一次投票信息即可。
4、统计投票
每次投票后,服务器都会统计所有投票,判断是否已经有过半的机器接收到相同的投票信息,对于server1和server2来说,都统计出集群中已经
有两台机器接受了(2, 0)这个投票信息。这里过半的概念是指大于集群机器数量的一半,即大于或等于(n/2+1)。对于这里由3台机器构成的集群
大于等于2台即为达到过半要求。
5、改变服务器状态
一旦确定了leader,每个服务器就会更新自己的状态,如果是follower,那么就变更为following,如果是leader,就变更为leading。
6.6.1.2 服务器运行时期的Leader选举
1、变更状态
当leader挂了之后,余下的非observer服务器都会将自己的状态变为looking,然后开始进行leader选举流程。
2、每个server会发出一个投票
在这个过程中,需要生成投票信息(myid, zxid),因为是运行期间,因此每个服务器上的zxid可能不同,我们假定server1的zxid为123,而server3的zxid为122.在第一轮投票中,server1和server3都会投给自己,即分别产生投票(1, 123)和(3, 122),然后各自将这个投票发给集群中的所有机器。
3、接收来自各个服务器的投票
4、处理投票
对于投票的处理,和上面提到的服务器启动期间的处理规则是一致的,在这个例子中,由于server1的zxid是123,server3的zxid是122,显然server1会成为leader。
5、统计投票
6、改变服务器状态
6.6.2 Leader选举的算法分析
6.6.2.1 术语解释
SID: 在zoo.cfg文件中,对集群中的每一个server都赋予一个id,标识着集群中的一台server。每台机器不能重复,和myid值一致
epoch:代表一个Leader周期。每当一个新的leader产生,该leader便会从服务器本地日志中最大事务Proposal的zxid解析出epoch值,然后对其进行+1操作,作为新的epoch.
zxid:事务ID,标识这对一次服务器状态的变更。是一个64bit的long数值,高32位标识着当前epoch,低32位是计数器。Leader在产生一个新的事务Proposal的时候,都会对该计数器进行+1操作。
新的Leader产生的时候,epoch+1的同时,低32会被置为0,在此基础上开始生成新的ZXID
Vote:投票
Quorum:过半机器数
6.6.2.2 进入leader选举
当zookeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入leader选举:
1、服务器初始化启动
2、服务器运行期间无法和leader保持连接
而当一台机器进入leader选举流程时,当前集群也可能会处于以下两种状态:
1、集群中本来就已经存在一个leader
2、集群中确实不存在leader
我们首先来看第一种已经存在leader的情况,这种情况通常是集群中的某一台机器启动比较晚,在它启动之前,集群已经可以正常工作,即已经存在一台leader服务器。针对这种情况,当该机器试图去选举leader的时候,会被告知当前服务器的leader信息,对于该机器来说,仅仅需要
和leader机器建立连接,并进行状态同步即可。
6.6.3 Leader选举的实现细节
1.LOOKING:寻找Leader状态。处于该状态的服务器会认为当前集群中不存在Leader,然后发起leader选举。
2.FOLLOWING:表明当前服务器角色是Follwer
3.LEADING:表明当前服务器角色是Leader
4.OBSERVING:表明当前服务器角色是Observer,不参与Leader选举
6.7 各服务器角色介绍
leader:
是整个集群工作机制中的核心,其主要工作有:
1、事务请求的唯一调度和处理者,保证集群事务处理的顺序性。
2、集群内部各服务器的调度者。
follower:
是zookeeper集群状态的跟随者,其主要工作是:
1、处理客户端的非事务请求,转发事务请求给leader服务器。
2、参与事务请求proposal的投票
3、参与leader选举投票
observer
和follower唯一的区别在于,observer服务器只提供非事务服务,不参与任何形式的投票,包括事务请求proposal的投票和leader选举投票。
通常在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
6.7.1 Leader
Leader服务器是Zookeeper集群工作的核心,其主要工作如下
(1) 事务请求的唯一调度和处理者,保证集群事务处理的顺序性。
(2) 集群内部各服务器的调度者。
6.7.1.1 请求处理链
使用责任链来处理每个客户端的请求时Zookeeper的特色,Leader服务器的请求处理链如下
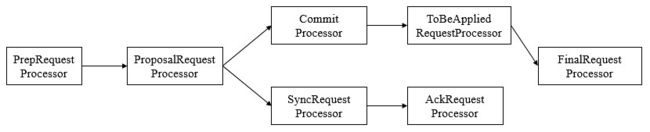
(1) PrepRequestProcessor。请求预处理器。在Zookeeper中,那些会改变服务器状态的请求称为事务请求(创建节点、更新数据、删除节点、创建会话等),PrepRequestProcessor能够识别出当前客户端请求是否是事务请求。对于事务请求,PrepRequestProcessor处理器会对其进行一系列预处理,如创建请求事务头、事务体、会话检查、ACL检查和版本检查等。
(2) ProposalRequestProcessor。事务投票处理器。Leader服务器事务处理流程的发起者,对于非事务性请求,ProposalRequestProcessor会直接将请求转发到CommitProcessor处理器,不再做任何处理,而对于事务性请求,处理将请求转发到CommitProcessor外,还会根据请求类型创建对应的Proposal提议,并发送给所有的Follower服务器来发起一次集群内的事务投票。同时,ProposalRequestProcessor还会将事务请求交付给SyncRequestProcessor进行事务日志的记录。
(2) SyncRequestProcessor。事务日志记录处理器。用来将事务请求记录到事务日志文件中,同时会触发Zookeeper进行数据快照。
(3) AckRequestProcessor。负责在SyncRequestProcessor完成事务日志记录后,向Proposal的投票收集器发送ACK反馈,以通知投票收集器当前服务器已经完成了对该Proposal的事务日志记录。
(4) CommitProcessor。事务提交处理器。对于非事务请求,该处理器会直接将其交付给下一级处理器处理;对于事务请求,其会等待集群内针对Proposal的投票直到该Proposal可被提交,利用CommitProcessor,每个服务器都可以很好地控制对事务请求的顺序处理。
(5) ToBeCommitProcessor。该处理器有一个toBeApplied队列,用来存储那些已经被CommitProcessor处理过的可被提交的Proposal。其会将这些请求交付给FinalRequestProcessor处理器处理,待其处理完后,再将其从toBeApplied队列中移除。
(6) FinalRequestProcessor。用来进行客户端请求返回之前的操作,包括创建客户端请求的响应,针对事务请求,该处理还会负责将事务应用到内存数据库中去。
6.7.1.2 LearnerHandler
为了保证整个集群内部的实时通信,同时为了确保可以控制所有的Follower/Observer服务器,Leader服务器会与每个Follower/Observer服务器建立一个TCP长连接。同时也会为每个Follower/Observer服务器创建一个名为LearnerHandler的实体。LearnerHandler是Learner服务器的管理者,主要负责Follower/Observer服务器和Leader服务器之间的一系列网络通信,包括数据同步、请求转发和Proposal提议的投票等。Leader服务器中保存了所有Follower/Observer对应的LearnerHandler。
6.7.2 Follower
Follower是Zookeeper集群的跟随者,其主要工作如下
(1) 处理客户端非事务性请求(读取数据),转发事务请求给Leader服务器。
(2) 参与事务请求Proposal的投票。
(3) 参与Leader选举投票。
Follower也采用了责任链模式组装的请求处理链来处理每一个客户端请求,由于不需要对事务请求的投票处理,因此Follower的请求处理链会相对简单,其处理链如下
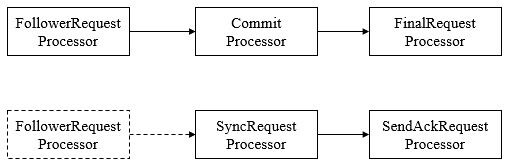
(1) FollowerRequestProcessor。其用作识别当前请求是否是事务请求,若是,那么Follower就会将该请求转发给Leader服务器,Leader服务器是在接收到这个事务请求后,就会将其提交到请求处理链,按照正常事务请求进行处理。
(2) SendAckRequestProcessor。其承担了事务日志记录反馈的角色,在完成事务日志记录后,会向Leader服务器发送ACK消息以表明自身完成了事务日志的记录工作。
6.7.3 Observer
Observer充当观察者角色,观察Zookeeper集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器进行处理。Observer不会参与任何形式的投票,包括事务请求Proposal的投票和Leader选举投票。其处理链如下
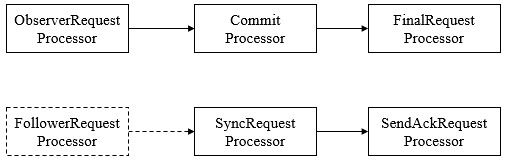
6.7.4 集群间消息通信
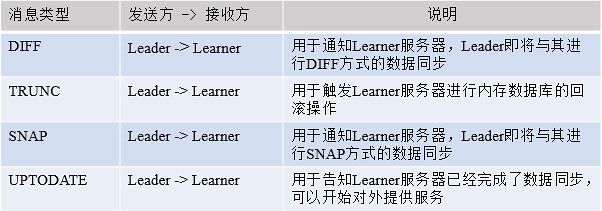
Zookeeper的消息类型大体分为数据同步型、服务器初始化型、请求处理型和会话管理型。
(1) 数据同步型。指在Learner和Leader服务器进行数据同步时,网络通信所用到的消息,通常有DIFF、TRUNC、SNAP、UPTODATE。
(2) 服务器初始化型。指在整个集群或是某些新机器初始化时,Leader和Learner之间相互通信所使用的消息类型,常见的有OBSERVERINFO、FOLLOWERINFO、LEADERINFO、ACKEPOCH和NEWLEADER五种。

(3) 请求处理型。指在进行清理时,Leader和Learner服务器之间互相通信所使用的消息,常见的有REQUEST、PROPOSAL、ACK、COMMIT、INFORM和SYNC六种。

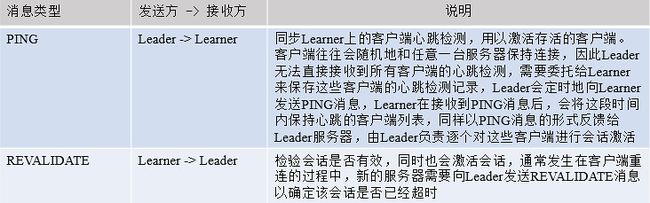
(4) 会话管理型。指Zookeeper在进行会话管理时和Learner服务器之间互相通信所使用的消息,常见的有PING和REVALIDATE两种。
6.8 请求处理
6.8.1 会话创建请求
Zookeeper服务端对于会话创建的处理,大体可以分为请求接收、会话创建、预处理、事务处理、事务应用和会话响应六大环节,其大体流程如

细分为以下23步
6.8.1.1 请求接收
(1) I/O层接收来自客户端的请求。NIOServerCnxn维护每一个客户端连接,客户端与服务器端的所有通信都是由NIOServerCnxn负责,其负责统一接收来自客户端的所有请求,并将请求内容从底层网络I/O中完整地读取出来。
(2) 判断是否是客户端会话创建请求。每个会话对应一个NIOServerCnxn实体,对于每个请求,Zookeeper都会检查当前NIOServerCnxn实体是否已经被初始化,如果尚未被初始化,那么就可以确定该客户端一定是会话创建请求。
(3) 反序列化ConnectRequest请求。一旦确定客户端请求是否是会话创建请求,那么服务端就可以对其进行反序列化,并生成一个ConnectRequest载体。
(4) 判断是否是ReadOnly客户端。如果当前Zookeeper服务器是以ReadOnly模式启动,那么所有来自非ReadOnly型客户端的请求将无法被处理。因此,服务端需要先检查是否是ReadOnly客户端,并以此来决定是否接受该会话创建请求。
(5) 检查客户端ZXID。正常情况下,在一个Zookeeper集群中,服务端的ZXID必定大于客户端的ZXID,因此若发现客户端的ZXID大于服务端ZXID,那么服务端不接受该客户端的会话创建请求。
(6) 协商sessionTimeout。在客户端向服务器发送超时时间后,服务器会根据自己的超时时间限制最终确定该会话超时时间,这个过程就是sessionTimeout协商过程。
(7) 判断是否需要重新激活创建会话。服务端根据客户端请求中是否包含sessionID来判断该客户端是否需要重新创建会话,若客户单请求中包含sessionID,那么就认为该客户端正在进行会话重连,这种情况下,服务端只需要重新打开这个会话,否则需要重新创建。
6.8.1.2 会话创建
(8) 为客户端生成sessionID。在为客户端创建会话之前,服务端首先会为每个客户端分配一个sessionID,服务端为客户端分配的sessionID是全局唯一的。
(9) 注册会话。向SessionTracker中注册会话,SessionTracker中维护了sessionsWithTimeout和sessionsById,在会话创建初期,会将客户端会话的相关信息保存到这两个数据结构中。
(10) 激活会话。激活会话涉及Zookeeper会话管理的分桶策略,其核心是为会话安排一个区块,以便会话清理程序能够快速高效地进行会话清理。
(11) 生成会话密码。服务端在创建一个客户端会话时,会同时为客户端生成一个会话密码,连同sessionID一同发给客户端,作为会话在集群中不同机器间转移的凭证。
6.8.1.3 预处理
(12) 将请求交给PrepRequestProcessor处理器处理。在提交给第一个请求处理器之前,Zookeeper会根据该请求所属的会话,进行一次激活会话操作,以确保当前会话处于激活状态,完成会话激活后,则提交请求至处理器。
(13) 创建请求事务头。对于事务请求,Zookeeper会为其创建请求事务头,服务端后续的请求处理器都是基于该请求头来识别当前请求是否是事务请求,请求事务头包含了一个事务请求最基本的一些信息,包括sessionID、ZXID(事务请求对应的事务ZXID)、CXID(客户端的操作序列)和请求类型(如create、delete、setData、createSession等)等。
(14) 创建请求事务体。由于此时是会话创建请求,其事务体是CreateSessionTxn。
(15) 注册于激活会话。处理由非Leader服务器转发过来的会话创建请求。
6.8.1.4 事务处理
(16) 将请求交给ProposalRequestProcessor处理器。
与提议相关的处理器,从ProposalRequestProcessor开始,请求的处理将会进入三个子处理流程,分别是Sync流程、Proposal流程、Commit流程。

Sync流程
使用SyncRequestProcessor处理器记录事务日志,针对每个事务请求,都会通过事务日志的形式将其记录,完成日志记录后,每个Follower都会向Leader发送ACK消息,表明自身完成了事务日志的记录,以便Leader统计每个事务请求的投票情况。
Proposal流程
每个事务请求都需要集群中过半机器投票认可才能被真正应用到内存数据库中,这个投票与统计过程就是Proposal流程。
· 发起投票。若当前请求是事务请求,Leader会发起一轮事务投票,在发起事务投票之前,会检查当前服务端的ZXID是否可用。
· 生成提议Proposal。若ZXID可用,Zookeeper会将已创建的请求头和事务体以及ZXID和请求本身序列化到Proposal对象中,此Proposal对象就是一个提议。
· 广播提议。Leader以ZXID作为标识,将该提议放入投票箱outstandingProposals中,同时将该提议广播给所有Follower。
· 收集投票。Follower接收到Leader提议后,进入Sync流程进行日志记录,记录完成后,发送ACK消息至Leader服务器,Leader根据这些ACK消息来统计每个提议的投票情况,当一个提议获得半数以上投票时,就认为该提议通过,进入Commit阶段。
· 将请求放入toBeApplied队列中。
· 广播Commit消息。Leader向Follower和Observer发送COMMIT消息。向Observer发送INFORM消息,向Leader发送ZXID。
Commit流程
· 将请求交付CommitProcessor。CommitProcessor收到请求后,将其放入queuedRequests队列中。
· 处理queuedRequest队列请求。CommitProcessor中单独的线程处理queuedRequests队列中的请求。
· 标记nextPending。若从queuedRequests中取出的是事务请求,则需要在集群中进行投票处理,同时将nextPending标记位当前请求。
· 等待Proposal投票。在进行Commit流程的同时,Leader会生成Proposal并广播给所有Follower服务器,此时,Commit流程等待,直到投票结束。
· 投票通过。若提议获得过半机器认可,则进入请求提交阶段,该请求会被放入commitedRequests队列中,同时唤醒Commit流程。
· 提交请求。若commitedRequests队列中存在可以提交的请求,那么Commit流程则开始提交请求,将请求放入toProcess队列中,然后交付下一个请求处理器:FinalRequestProcessor。
6.8.1.5 事务应用
(17) 交付给FinalRequestProcessor处理器。FinalRequestProcessor处理器检查outstandingChanges队列中请求的有效性,若发现这些请求已经落后于当前正在处理的请求,那么直接从outstandingChanges队列中移除。
(18) 事务应用。之前的请求处理仅仅将事务请求记录到了事务日志中,而内存数据库中的状态尚未改变,因此,需要将事务变更应用到内存数据库。
(19) 将事务请求放入队列commitProposal。完成事务应用后,则将该请求放入commitProposal队列中,commitProposal用来保存最近被提交的事务请求,以便集群间机器进行数据的快速同步。
6.8.1.6 会话响应
(20) 统计处理。Zookeeper计算请求在服务端处理所花费的时间,统计客户端连接的基本信息,如lastZxid(最新的ZXID)、lastOp(最后一次和服务端的操作)、lastLatency(最后一次请求处理所花费的时间)等。
(21) 创建响应ConnectResponse。会话创建成功后的响应,包含了当前客户端和服务端之间的通信协议版本号、会话超时时间、sessionID和会话密码。
(22) 序列化ConnectResponse。
(23) I/O层发送响应给客户端。
6.8.2 SetData请求
6.8.3 事务请求转发
6.8.4 GetData请求
6.9 数据与存储
6.9.1 内存数据
Zookeeper的数据模型是树结构,在内存数据库中,存储了整棵树的内容,包括所有的节点路径、节点数据、ACL信息,Zookeeper会定时将这个数据存储到磁盘上。
1. DataTree
DataTree是内存数据存储的核心,是一个树结构,代表了内存中一份完整的数据。DataTree不包含任何与网络、客户端连接及请求处理相关的业务逻辑,是一个独立的组件。
2. DataNode
DataNode是数据存储的最小单元,其内部除了保存了结点的数据内容、ACL列表、节点状态之外,还记录了父节点的引用和子节点列表两个属性,其也提供了对子节点列表进行操作的接口。
3. ZKDatabase
Zookeeper的内存数据库,管理Zookeeper的所有会话、DataTree存储和事务日志。ZKDatabase会定时向磁盘dump快照数据,同时在Zookeeper启动时,会通过磁盘的事务日志和快照文件恢复成一个完整的内存数据库。
6.9.2 事务日志
6.9.2.1 文件存储
在配置Zookeeper集群时需要配置dataDir目录,其用来存储事务日志文件。也可以为事务日志单独分配一个文件存储目录:dataLogDir。若配置dataLogDir为/home/admin/zkData/zk_log,那么Zookeeper在运行过程中会在该目录下建立一个名字为version-2的子目录,该目录确定了当前Zookeeper使用的事务日志格式版本号,当下次某个Zookeeper版本对事务日志格式进行变更时,此目录也会变更,即在version-2子目录下会生成一系列文件大小一致(64MB)的文件。
6.9.2.2 日志格式
在配置好日志文件目录,启动Zookeeper后,完成如下操作
(1) 创建/test_log节点,初始值为v1。
(2) 更新/test_log节点的数据为v2。
(3) 创建/test_log/c节点,初始值为v1。
(4) 删除/test_log/c节点。
经过四步操作后,会在/log/version-2/目录下生成一个日志文件,笔者下是log.cec。
将Zookeeper下的zookeeper-3.4.6.jar和slf4j-api-1.6.1.jar复制到/log/version-2目录下,使用如下命令打开log.cec文件。
java -classpath ./zookeeper-3.4.6.jar:./slf4j-api-1.6.1.jar org.apache.zookeeper.server.LogFormatter log.cec
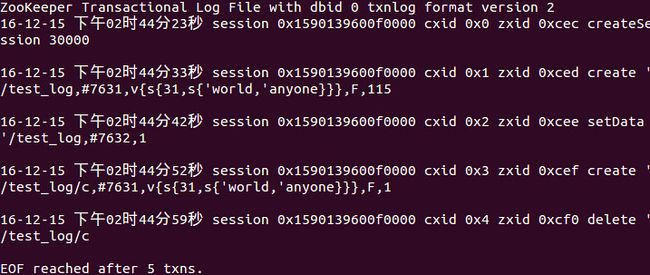
ZooKeeper Transactional Log File with dbid 0 txnlog format version 2 。是文件头信息,主要是事务日志的DBID和日志格式版本号。
…session 0x159…0xcec createSession 30000。表示客户端会话创建操作。
…session 0x159…0xced create '/test_log,… 。表示创建/test_log节点,数据内容为#7631(v1)。
…session 0x159…0xcee setData ‘/test_log,…。表示设置了/test_log节点数据,内容为#7632(v2)。
…session 0x159…0xcef create ’/test_log/c,…。表示创建节点/test_log/c。
…session 0x159…0xcf0 delete '/test_log/c。表示删除节点/test_log/c。
6.9.2.3 日志写入
FileTxnLog负责维护事务日志对外的接口,包括事务日志的写入和读取等。Zookeeper的事务日志写入过程大体可以分为如下6个步骤。
(1) 确定是否有事务日志可写。当Zookeeper服务器启动完成需要进行第一次事务日志的写入,或是上一次事务日志写满时,都会处于与事务日志文件断开的状态,即Zookeeper服务器没有和任意一个日志文件相关联。因此在进行事务日志写入前,Zookeeper首先会判断FileTxnLog组件是否已经关联上一个可写的事务日志文件。若没有,则会使用该事务操作关联的ZXID作为后缀创建一个事务日志文件,同时构建事务日志的文件头信息,并立即写入这个事务日志文件中去,同时将该文件的文件流放入streamToFlush集合,该集合用来记录当前需要强制进行数据落盘的文件流。
(2) 确定事务日志文件是否需要扩容(预分配)。Zookeeper会采用磁盘空间预分配策略。当检测到当前事务日志文件剩余空间不足4096字节时,就会开始进行文件空间扩容,即在现有文件大小上,将文件增加65536KB(64MB),然后使用"0"填充被扩容的文件空间。
(3) 事务序列化。对事务头和事务体的序列化,其中事务体又可分为会话创建事务、节点创建事务、节点删除事务、节点数据更新事务等。
(4) 生成Checksum。为保证日志文件的完整性和数据的准确性,Zookeeper在将事务日志写入文件前,会计算生成Checksum。
(5) 写入事务日志文件流。将序列化后的事务头、事务体和Checksum写入文件流中,此时并为写入到磁盘上。
(6) 事务日志刷入磁盘。由于步骤5中的缓存原因,无法实时地写入磁盘文件中,因此需要将缓存数据强制刷入磁盘。
6.9.2.4 日志截断
在Zookeeper运行过程中,可能出现非Leader记录的事务ID比Leader上大,这是非法运行状态。此时,需要保证所有机器必须与该Leader的数据保持同步,即Leader会发送TRUNC命令给该机器,要求进行日志截断,Learner收到该命令后,就会删除所有包含或大于该事务ID的事务日志文件。
6.9.3 snapshot——数据快照
数据快照是Zookeeper数据存储中非常核心的运行机制,数据快照用来记录Zookeeper服务器上某一时刻的全量内存数据内容,并将其写入指定的磁盘文件中。
6.9.3.1 文件存储
与事务文件类似,Zookeeper快照文件也可以指定特定磁盘目录,通过dataDir属性来配置。若指定dataDir为/home/admin/zkData/zk_data,则在运行过程中会在该目录下创建version-2的目录,该目录确定了当前Zookeeper使用的快照数据格式版本号。在Zookeeper运行时,会生成一系列文件。
6.9.3.2 数据快照
FileSnap负责维护快照数据对外的接口,包括快照数据的写入和读取等,将内存数据库写入快照数据文件其实是一个序列化过程。针对客户端的每一次事务操作,Zookeeper都会将他们记录到事务日志中,同时也会将数据变更应用到内存数据库中,Zookeeper在进行若干次事务日志记录后,将内存数据库的全量数据Dump到本地文件中,这就是数据快照。其步骤如下
(1) 确定是否需要进行数据快照。每进行一次事务日志记录之后,Zookeeper都会检测当前是否需要进行数据快照,考虑到数据快照对于Zookeeper机器的影响,需要尽量避免Zookeeper集群中的所有机器在同一时刻进行数据快照。采用过半随机策略进行数据快照操作。
(2) 切换事务日志文件。表示当前的事务日志已经写满,需要重新创建一个新的事务日志。
(3) 创建数据快照异步线程。创建单独的异步线程来进行数据快照以避免影响Zookeeper主流程。
(4) 获取全量数据和会话信息。从ZKDatabase中获取到DataTree和会话信息。
(5) 生成快照数据文件名。Zookeeper根据当前已经提交的最大ZXID来生成数据快照文件名。
(6) 数据序列化。首先序列化文件头信息,然后再对会话信息和DataTree分别进行序列化,同时生成一个Checksum,一并写入快照数据文件中去。
6.9.4 初始化
在Zookeeper服务器启动期间,首先会进行数据初始化工作,用于将存储在磁盘上的数据文件加载到Zookeeper服务器内存中。
6.9.4.1 初始化流程
Zookeeper的初始化过程如下图所示
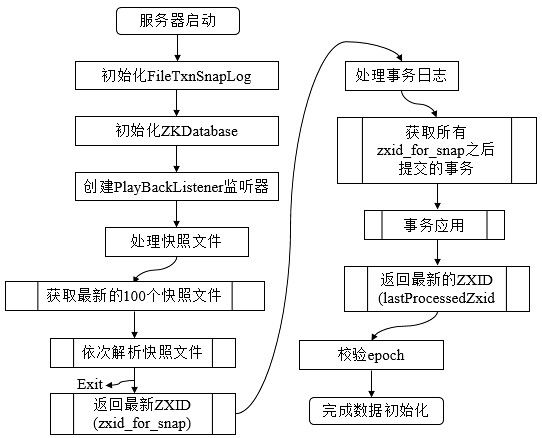
数据的初始化工作是从磁盘上加载数据的过程,主要包括了从快照文件中加载快照数据和根据实物日志进行数据修正两个过程。
(1) 初始化FileTxnSnapLog。FileTxnSnapLog是Zookeeper事务日志和快照数据访问层,用于衔接上层业务和底层数据存储,底层数据包含了事务日志和快照数据两部分。FileTxnSnapLog中对应FileTxnLog和FileSnap。
(2) 初始化ZKDatabase。首先构建DataTree,同时将FileTxnSnapLog交付ZKDatabase,以便内存数据库能够对事务日志和快照数据进行访问。在ZKDatabase初始化时,DataTree也会进行相应的初始化工作,如创建一些默认结点,如/、/zookeeper、/zookeeper/quota三个节点。
(3) 创建PlayBackListener。其主要用来接收事务应用过程中的回调,在Zookeeper数据恢复后期,会有事务修正过程,此过程会回调PlayBackListener来进行对应的数据修正。
(4) 处理快照文件。此时可以从磁盘中恢复数据了,首先从快照文件开始加载。
(5) 获取最新的100个快照文件。更新时间最晚的快照文件包含了最新的全量数据。
(6) 解析快照文件。逐个解析快照文件,此时需要进行反序列化,生成DataTree和sessionsWithTimeouts,同时还会校验Checksum及快照文件的正确性。对于100个快找文件,如果正确性校验通过时,通常只会解析最新的那个快照文件。只有最新快照文件不可用时,才会逐个进行解析,直至100个快照文件全部解析完。若将100个快照文件解析完后还是无法成功恢复一个完整的DataTree和sessionWithTimeouts,此时服务器启动失败。
(7) 获取最新的ZXID。此时根据快照文件的文件名即可解析出最新的ZXID:zxid_for_snap。该ZXID代表了Zookeeper开始进行数据快照的时刻。
(8) 处理事务日志。此时服务器内存中已经有了一份近似全量的数据,现在开始通过事务日志来更新增量数据。
(9) 获取所有zxid_for_snap之后提交的事务。此时,已经可以获取快照数据的最新ZXID。只需要从事务日志中获取所有ZXID比步骤7得到的ZXID大的事务操作。
(10) 事务应用。获取大于zxid_for_snap的事务后,将其逐个应用到之前基于快照数据文件恢复出来的DataTree和sessionsWithTimeouts。每当有一个事务被应用到内存数据库中后,Zookeeper同时会回调PlayBackListener,将这事务操作记录转换成Proposal,并保存到ZKDatabase的committedLog中,以便Follower进行快速同步。
(11) 获取最新的ZXID。待所有的事务都被完整地应用到内存数据库中后,也就基本上完成了数据的初始化过程,此时再次获取ZXID,用来标识上次服务器正常运行时提交的最大事务ID。
(12) 校验epoch。epoch标识了当前Leader周期,集群机器相互通信时,会带上这个epoch以确保彼此在同一个Leader周期中。完成数据加载后,Zookeeper会从步骤11中确定ZXID中解析出事务处理的Leader周期:epochOfZxid。同时也会从磁盘的currentEpoch和acceptedEpoch文件中读取上次记录的最新的epoch值,进行校验。
6.9.5 数据同步
整个集群完成Leader选举后,Learner会向Leader进行注册,当Learner向Leader完成注册后,就进入数据同步环节,同步过程就是Leader将那些没有在Learner服务器上提交过的事务请求同步给Learner服务器,大体过程如下

(1) 获取Learner状态。在注册Learner的最后阶段,Learner服务器会发送给Leader服务器一个ACKEPOCH数据包,Leader会从这个数据包中解析出该Learner的currentEpoch和lastZxid。
(2) 数据同步初始化。首先从Zookeeper内存数据库中提取出事务请求对应的提议缓存队列proposals,同时完成peerLastZxid(该Learner最后处理的ZXID)、minCommittedLog(Leader提议缓存队列commitedLog中最小的ZXID)、maxCommittedLog(Leader提议缓存队列commitedLog中的最大ZXID)三个ZXID值的初始化。
对于集群数据同步而言,通常分为四类,直接差异化同步(DIFF同步)、先回滚再差异化同步(TRUNC+DIFF同步)、仅回滚同步(TRUNC同步)、全量同步(SNAP同步),在初始化阶段,Leader会优先以全量同步方式来同步数据。同时,会根据Leader和Learner之间的数据差异情况来决定最终的数据同步方式。
· 直接差异化同步(DIFF同步,peerLastZxid介于minCommittedLog和maxCommittedLog之间)。Leader首先向这个Learner发送一个DIFF指令,用于通知Learner进入差异化数据同步阶段,Leader即将把一些Proposal同步给自己,针对每个Proposal,Leader都会通过发送PROPOSAL内容数据包和COMMIT指令数据包来完成,
· 先回滚再差异化同步(TRUNC+DIFF同步,Leader已经将事务记录到本地事务日志中,但是没有成功发起Proposal流程)。当Leader发现某个Learner包含了一条自己没有的事务记录,那么就需要该Learner进行事务回滚,回滚到Leader服务器上存在的,同时也是最接近于peerLastZxid的ZXID。
· 仅回滚同步(TRUNC同步,peerLastZxid大于maxCommittedLog)。Leader要求Learner回滚到ZXID值为maxCommittedLog对应的事务操作。
· 全量同步(SNAP同步,peerLastZxid小于minCommittedLog或peerLastZxid不等于lastProcessedZxid)。Leader无法直接使用提议缓存队列和Learner进行同步,因此只能进行全量同步。Leader将本机的全量内存数据同步给Learner。Leader首先向Learner发送一个SNAP指令,通知Learner即将进行全量同步,随后,Leader会从内存数据库中获取到全量的数据节点和会话超时时间记录器,将他们序列化后传输给Learner。Learner接收到该全量数据后,会对其反序列化后载入到内存数据库中。
七、Zookeeper运维
7.1 配置参数
| 命令 | 解释 |
|---|---|
| dataDir | 用于配置走开服务器的快照文件目录,默认情况下,如果没有配置dataLogDir,那么事务日志也会存储在这个目录中。考虑到事务日志的写性能直接影响zookeeper整体的服务能力,因此建议同时设置dataDir和dataLogDir。 |
| dataLogDir | 存储事务日志文件,zookeeper在返回客户端事务请求响应之前,必须将本次请求对应的事务日志写入到磁盘中,因此,事务日志写入的性能直接确定了zookeeper在处理事务请求时的吞吐。尤其是上文中提到的数据快照操作,会极大的影响事务日志的写性能,因此尽量给事务日志的输出配置一个单独的磁盘或是挂载点,将极大的提升zookeeper的整体性能。 |
| initLimit | 默认为10,用于配置leader服务器等待follower启动,并完成数据同步的时间,follower服务器再启动过程中,会与leader建立连接并完成数据同步,从而确定自己对外提供服务的起始状态。leader服务器允许follower在initLimit时间内完成这个工作。通常情况下,不用修改这个参数,但随着zookeeper集群管理的数据量的增大,follower服务器在启动的时候,从leader上进行同步数据的时间也会相应边长,于是无法在较短的时间完成数据同步,因此,在这种情况下,需要调大这个参数。 |
| syncLimit | 默认值5,用于配置leader服务器和follower之间进行心跳检测的最大延时时间,在zookeeper集群运行过程中,leader服务器会与所有的follower进行心跳检测来确定该服务器是否存活,如果leader服务器在syncLimit时间内无法获取到follower的心跳检测响应,那么leader就会认为该follower已经脱离了和自己的同步。一般使用默认值即可,除非网络环境较差。 |
| snapCount | 默认100000,用于配置相邻两次数据快照之间的事务操作次数,即zookeeper会在snapCount次事务操作后进行一次数据快照。 |
| preAllocSize | 默认值是65535,即64MB。用于设置事务日志文件的预分配磁盘空间,如果我们修改了snapCount的值,那么preAllocSize参数也要随着做出变更。 |
| minSessionTimeout /maxSessionTimeout |
分别默认值是2倍和20倍,这两个参数用于服务端对客户端会话的超时时间进行限制,如果客户端设置的超时时间不在该范围内,那么会被服务器强制设置为最大或最小超时时间。 |
| jute.maxbuffer | 默认值1048575,单位字节,用于配置单个数据节点znode上可以存储的最大数据量大小,通常需要考虑到zookeeper上不适宜存储太多的数据,往往需要将该参数设置的更小,在变更该参数时,需要在zookeeper集群的所有机器以及所有客户端上设置才能生效。 |
| server.id=host:port:port | 配置zookeeper集群机器列表,其中id为serverID,与每台服务器myid文件中的数字对应,同时,在该参数中,会配置两个端口。第一个用于指定follower服务器与leader进行运行时通信和数据同步时所使用的端口,第二个则专门用于leader选举过程中的投票通信。 |
| autopurge.snapRetainCount | 默认值为3,zookeeper增加了对历史事务日志和快照数据自动清理的功能,该参数用于配置zookeeper在自动清理时需要保留的快照数据文件数量和对应的事务日志文件。并不是磁盘上的所有文件都可以被清理,这样将无法恢复数据。因此该参数的最小值是3,如果配置的比3小,则会被自动调整到3。 |
| autopurge.purgeInterval | 默认值为0,用于配置zookeeper进行历史文件自动清理的频率,该值为0表示不需要开启定时清理功能。 |
| fsync.warningthresholdms | 默认1000毫秒,用于配置zookeeper进行事务日志fsync操作时消耗时间的报警阈值,一旦进行一个fsync操作消耗的时间大于该参数,就在日志中打印出报警日志。 |
| forceSync | 默认值为yes,用于配置zookeeper是否在事务提交的时候,将日志写入操作强制刷新磁盘,默认是yes,即每次事务日志写入操作都会实时刷入磁盘,如果是no,可以提高zookeeper写性能,但存在类似机器断电这样的安全风险。 |
| globalOutstandingLimit | 默认1000,配置zookeeper服务器最大请求堆积量,在zookeeper运行过程中,客户端会不断的将请求发送到服务端,为了防止服务端资源耗尽,服务端必须限制同时处理的请求数,即最大请求堆积数量。 |
| leaderServes | 默认为yes,配置leader是否有可以接受客户端连接,即是否允许leader向客户端提供服务,默认情况下,leader服务器能够接受并处理客户端读写请求,在zookeeper的设计中,leader服务器主要用于进行对事务更新请求的协调以及集群本身的运行时协调,因此,可以设置让leader服务器不接受客户端的连接,使其专注于进行分布式协调。 |
| skipAcl | 默认为no,配置是否可以跳过acl权限检查,默认情况下,会对每一个客户端请求进行权限检查,如果设置为yes,则能一定程度的提升zookeeper的读写性能,但同时也将向所有客户端开放zookeeper的数据,包括那些之前设置过acl权限的数据节点,也将不再接受权限控制。 |
| cnxTimeout | 默认5000毫秒,配置在leader选举过程中,各服务器之间进行tcp连接创建的超时时间。 |
7.1 2四字命令
先Telnet上服务器:telnet localhost 2181
| 命令 | 解释 |
|---|---|
| conf | 输出zookeeper服务器运行时使用的基本配置信息,包括clientPort、dataDir、tickTime等。 |
| cons | 输出当前这台服务器上所有客户端连接的详细信息,包括每个客户端的客户端ip、会话id和最后一次与服务器交互的操作类型等。 |
| crst | 是一个功能性命令,用于重置所有的客户端连接统计信息。 |
| dump | 用于输出当前集群的所有会话信息,包括这些会话的会话id,以及每个会话创建的临时节点等信息,另外,只有leader服务器会进行所有会话的超时检测,因此,如果在leader上执行该命令,还能够看到每个会话的超时时间。 |
| envi | 输出zookeeper所在服务器运行时的环境信息。 |
| ruok | 输出当前zookeeper服务器是否正在运行,该命令的名字非常有趣,谐音正好是are you ok。执行该命令后,如果当前zookeeper服务器正在运行,那么返回imok,否则没有任何输出。这个命令只能说明2181端口开着,想要更可靠的获取更多zookeeper运行状态信息,可以使用stat命令。 |
| stat | 用于获取zookeeper服务器的运行时状态信息,包括基本的zookeeper版本、打包信息、运行时角色、集群数据节点个数等信息,还会将当前服务器的客户端连接打印出来。还会输出一些服务器的统计信息,包括延迟情况,收到请求数和返回的响应数等。 |
| srst | 是一个功能命令,用于重置所有服务器的统计信息。 |
| wchs | 命令用于输出当前服务器上管理的watcher的概要信息。 |
| wchc | 用于输出当前服务器上管理的watcher的详细信息,以会话为单位进行归组,同时列出被该会话注册了watcher的节点路径。 |
| wchp | 和wahc一样,不同点在于该命令的输出信息以节点路径为单位进行归组。 |
| mntr | 用于输出比stat命令更详尽的服务器统计信息,包括请求处理的延迟情况、服务器内存数据库大小和集群的数据同步情况。 |
reference
【分布式】Zookeeper与Paxos
https://github.com/yhb2010/zookeeper-paxos