浅谈隐式马尔可夫模型 - A Brief Note of Hidden Markov Model (HMM)
- Introduction
- Problem Formulation
- Bayes Decision Theory
- Markov Model
- Hidden Markov Model
- HMM Problems and Solutions
- Evaluation
- Forward Algorithm
- Backward Algorithm
- Decoding
- Viterbi Algorithm
- Training
- Baum-Welch Reestimation
- Evaluation
- Reference
Introduction
Problem Formulation
Now we talk about Hidden Markov Model. Well, what is HMM used for? Consider the following problem:
Given an unknown observation: O O , recognize it as one of N N classes with minimum probability of error.
So how to define the error and error probability?
Conditional Error: Given O O , the risk associated with deciding that it is a class i i event:
Expected Error:
How should S(O) S ( O ) be made to achieve minimum error probability? Or P(S(O)|O) P ( S ( O ) | O ) is maximized?
Bayes Decision Theory
If we institute the policy: S(O)=Si=argmaxSjP(Sj|O) S ( O ) = S i = arg max S j P ( S j | O ) then R(S(O)|O)=minSjR(Sj|O) R ( S ( O ) | O ) = min S j R ( S j | O ) . It is the so-called Maximum A Posteriori (MAP) decision. But how do we know P(Sj|O),i=1,2,…,M P ( S j | O ) , i = 1 , 2 , … , M for any O O ?
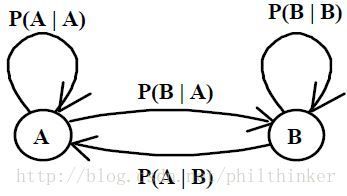
Markov Model
States : S={S0,S1,S2,…,SN} S = { S 0 , S 1 , S 2 , … , S N }
Transition probabilities : P(qt=Si|qt−1=Sj) P ( q t = S i | q t − 1 = S j )
Markov Assumption:
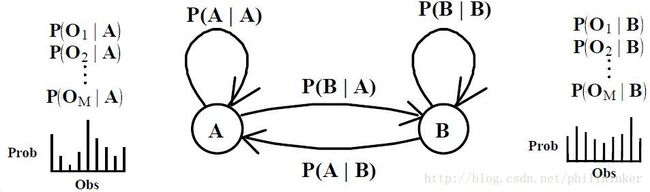
Hidden Markov Model
States: S={S0,S1,S2,…,SN} S = { S 0 , S 1 , S 2 , … , S N }
Transition probabilities : P(qt=Si|qt−1=Sj)=aji P ( q t = S i | q t − 1 = S j ) = a j i
Output probability distributions (at state j j for symbol k k ): P(yt=Ok|qt=Sj)=bj(k,λj) P ( y t = O k | q t = S j ) = b j ( k , λ j ) parameterized by λj λ j .
HMM Problems and Solutions
- Evaluation: Given a model, compute probability of observation sequence.
- Decoding: Find a state sequence which maximizes probability of the observation sequence.
- Training: Adjust model parameters which maximizes probability of observed sequences.
Evaluation
Compute the probability of observation sequence O=o1o2…oT O = o 1 o 2 … o T , given a HMM model parameter λ λ :
This is not practical since the number of paths is O(NT) O ( N T ) . How to deal with it?
Forward Algorithm
Compute α α recursively:
Computation is O(N2T) O ( N 2 T ) .
Backward Algorithm
Compute β β recursively:
Computation is O(N2T) O ( N 2 T ) .
Decoding
Find the state sequence Q Q which maximizes P(O,Q|λ) P ( O , Q | λ ) .
Viterbi Algorithm
Compute VP V P recursively:
Training
For the sake of tuning λ λ to maximize P(O|λ) P ( O | λ ) , there is NO efficient algorithm for global optimum, nonetheless, efficient iterative algorithm capable of finding a local optimum exists.
Baum-Welch Reestimation
Define the probability of transiting from Si S i to Sj S j at time t t given O O as1
Let
Training Algorithm:
- Initialize λ=(A,B) λ = ( A , B ) .
- Compute α,β α , β and ξ ξ .
- Estimate λ¯=(A¯,B¯) λ ¯ = ( A ¯ , B ¯ ) from ξ ξ .
- Replace λ λ with λ¯ λ ¯ .
- If not converge, go to 2.
Reference
More details needed? Refer to :
- “An Introduction to Hidden Markov Models”, by Rabiner and Juang.
- “Hidden Markov Models: Continuous Speech Recognition”, by Kai-Fu Lee.
- Thanks B. H. Juang in Georgia Institute of Technology.
- Thanks Wayne Ward in Carnegie Mellon University.
- Forward-Backward Algorithm
 ↩
↩