大数据环境安装汇总
1.安装centos6.4到vmware 用户名为hadoop
2.添加hadooop到sudo用户组
su - 切换到root中
visudo
添加 hadoop ALL=(ALL) ALL

3.修改主机名:
sudo vim /etc/sysconfig/network

sudo vim /etc/hosts
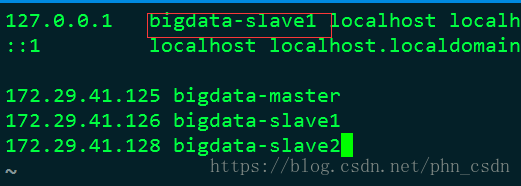
sudo hostname your_user_name
4.关闭防火墙
service iptables stop
chkconfig iptables off
5.安装jdk
解压:tar -zxvf jdk-8u111-linux-x64.tar.gz -C ~/app/
配置环境变量:
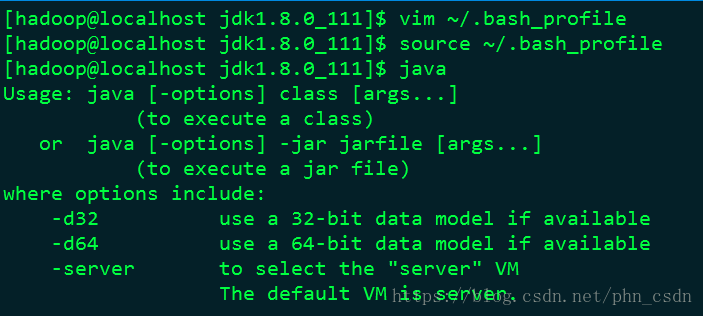
vi ~/.bash_profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_111
export PATH=$JAVA_HOME/bin:$PATH 生效:source ~/.bash_profile
6.安装Flume
解压:tar -zxvf flume-ng-1.6.0-cdh5.7.0.tar.gz -C ~/app/
配置环境变量:
export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH生效:source ~/.bash_profile
复制conf下的配置文件:cp flume-env.sh.template flume-env.sh
加入java环境变量:
vi flume-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_111

7.安装Zookeeper
解压:tar -zxvf zookeeper-3.4.5-cdh5.7.0.tar.gz -C ~/app/
配置环境变量:
export ZK_HOME=/home/hadoop/app/zookeeper-3.4.5-cdh5.7.0
export PATH=$ZK_HOME/bin:$PATH生效:source ~/.bash_profile
配置zookeeper conf/zoo.cfg dataDir

在zoo.cfg上配置集群机器:

在/home/hadoop/app/tmp/zookeeper下 新建myid文件
在不同机器递增写入1、2、3
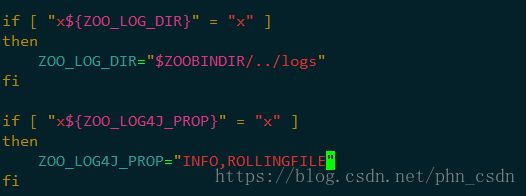
修改conf/log4j.properties

修改 bin/zkEnv.sh:
启动:./zkServer.sh start
8.安装Kafka
解压:tar -zxvf kafka_2.11-0.9.0.0.tgz -C ~/app/
配置环境变量:
export KAFKA_HOME=/home/hadoop/app/kafka_2.11-0.9.0.0
export PATH=$KAFKA_HOME/bin:$PATH生效:source ~/.bash_profile
修改 config/server.properties
broker.id=0
listerers=
host.name=
log.dirs=
zookeeper.connect=
启动:../bin/kafka-server-start.sh ./server.properties
创建topic : bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test
查看topic:bin/kafka-topics.sh –list –zookeeper localhost:2181
生产消息:bin/kafka-console-producer.sh –zookeeper localhost:9092 –topic test
消费消息:bin/kafka-console-consumer.sh –zookeeper localhost:9092 –topic test –from-beginning
9.安装scala
解压:tar -zxvf scala-2.11.8.tgz -C ../app/
配置环境变量:
export SCALA_HOME=/home/hadoop/app/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH生效:source ~/.bash_profile
查看版本:scala –version

10.安装hadoop
ssh免密登录:
cd ~/.ssh/
ssh-keygent -t rsa

ssh-copy-id bigdata-master
ssh-copy-id bigdata-slave1
ssh-copy-id bigdata-slave2

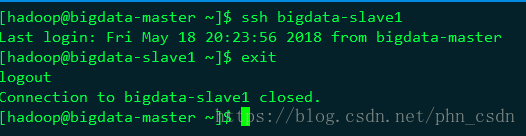
测试免登录情况:ssh bigdata-slave1
解压文件:
tar -zxvf hadoop-2.6.0-cdh5.7.0.tar.gz -C ../app/
配置环境变量:
vim ~/.bash_profile
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
export PATH= HADOOPHOME/bin: H A D O O P H O M E / b i n : PATH
生效:
source ~/.bash_profile
修改/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hadoop-env.sh:
加入java环境变量:export JAVA_HOME=/home/hadoop/app/jdk1.8.0_111

修改/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://bigdata-master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/tmpvalue>
property>
configuration>修改/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/hdfs-site.xml:
<property>
<name>dfs.namenode.http-addressname>
<value>bigdata-master:50070value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>bigdata-slave1:50090value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/namevalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/datavalue>
property>修改/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/mapred-site.xml:
cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration> 修改/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>bigdata-mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>修改/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/masters
新建masters文件,写入bigdata-slave1(写入Secondry NameNode的名字)
修改/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop/slaves
写入bigdata-slave1 、bigdata-slave2
创建各种文件夹:
cd /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/
mkdir tmp name data
格式化namenode:
./bin/hdfs namenode -format

启动hdfs
./sbin/start-dfs.sh
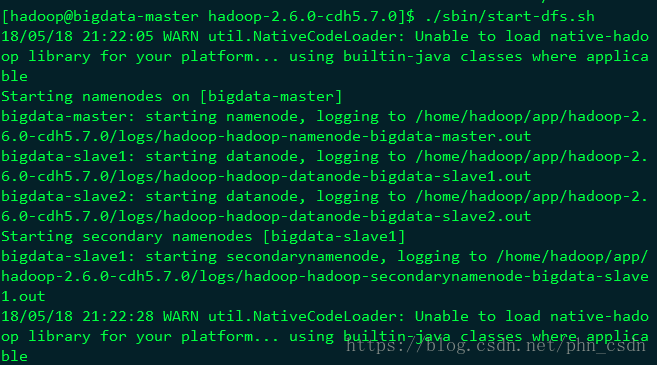
启动yarn
./sbin/start-yarn.sh
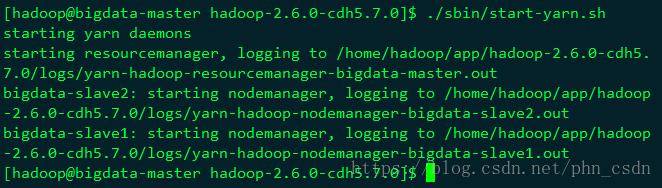
浏览器查看:bigdata-master:50070

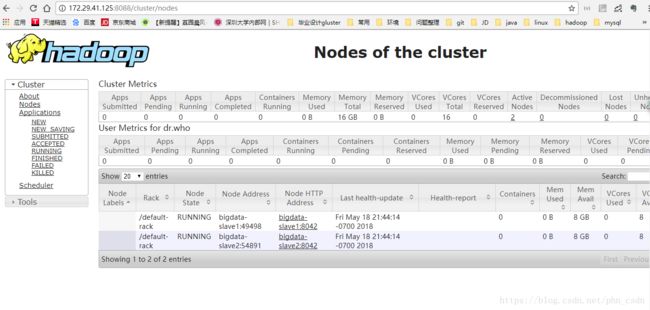
11.安装HBASE:
解压文件:
tar -zxvf hbase-1.2.0-cdh5.7.0.tar.gz -C ../app/
配置环境变量:
vim ~/.bash_profile
export HBASE_HOME=/home/hadoop/app/hbase-1.2.0-cdh5.7.0
export PATH=$HBASE_HOME/bin:$PATH生效:
source ~/.bash_profile
拷贝/etc/hadoop下的core-site.xml和hdfs-site.xml到$HBASE_HOME/conf
cp $HADOOP_HOME/etc/hadoop/core-site.xml $HBASE_HOME/conf/
cp $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HBASE_HOME/conf/修改 conf/hbase_env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_111
export HBASE_MANAGES_ZK=false
export HBASE_LOG_DIR=${HBASE_HOME}/logs

修改 conf/regionservers

修改 conf/hbase-site.xml
<property>
<name>hbase.rootdirname>
<value>hdfs://bigdata-master:9000/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>bigdata-master,bigdata-slave1,bigdata-slave2value>
property>
<property>
<name>hbase.mastername>
<value>bigdata-mastervalue>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/home/hadoop/app/tmp/zookeepervalue>
property>
<property>
<name>hbase.zookeeper.property.clientPortname>
<value>2181value>
property>
<property>
<name>hbase.master.info.portname>
<value>16010value>
property>
<property>
<name>hbase.regionserver.info.portname>
<value>16030value>
property>启动hbase:
../bin/start-hbase.sh
master jps查看:
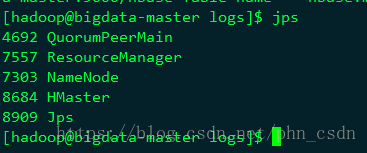
slave:


启动shell:hbase shell
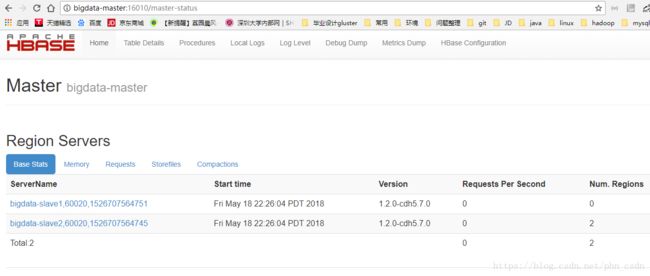
浏览器查看:bigdata-master:16010
12.安装HIVE
安装mysql:
yum -y install mysql-server
启动并进入:
sudo service mysqld start
mysql -uroot
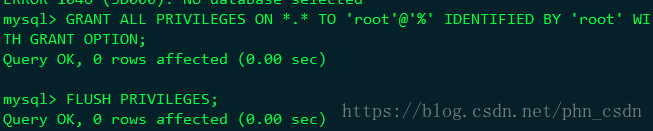
授权外部访问:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
创建hive数据库:
create database hive;
解压文件:
tar -zxvf hive-1.1.0-cdh5.7.0.tar.gz -C ../app/
配置环境变量:
vim ~/.bash_profile
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export PATH=$HIVE_HOME/bin:$PATH生效:
source ~/.bash_profile
进入$HIVE_HOME/conf下复制文件:
cp beeline-log4j.properties.template beeline-log4j.properties
cp hive-exec-log4j.properties.template hive-exec-log4j.properties
cp hive-env.sh.template hive-env.sh
cp hive-log4j.properties.template hive-log4j.properties
cp hive-default.xml.template hive-site.xml
修改conf/hive-env.sh:
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_111
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
export HIVE_CONF_DIR=/home/hadoop/app/hive-1.1.0-cdh5.7.0/conf

修改conf/hive-log4j.properties
mkdir $HIVE_HOME/logs
hive.log.dir=/home/hadoop/app/hive-1.1.0-cdh5.7.0/logs

修改conf/hive-site.xml
<configuration>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>hive.exec.scratchdirname>
<value>/user/hive/tmpvalue>
property>
<property>
<name>hive.querylog.locationname>
<value>/user/hive/logvalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname> <value>jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=truevalue> property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename> <value>com.mysql.jdbc.Drivervalue> property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>mysql登录用户名value>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>mysql登录密码value>
property>在hdfs上创建目录并授权:
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user/hive/warehouse
hdfs dfs -chmod -R 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/log
上传Mysql jar连接包
cp ~/software/mysql-connector-java-5.1.38-bin.jar lib/
进入hive测试:

12.安装Spark
解压文件:
tar -zxvf spark-2.2.0-bin-2.6.0-cdh5.7.0.tgz -C ../app/
配置环境变量:
vim ~/.bash_profile
export SPARK_HOME=/home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0
export PATH=$SPARK_HOME/bin:$PATH生效:
source ~/.bash_profile
修改conf/spark-env.sh:
cp spark-env.sh.template spark-env.sh
export SCALA_HOME=/home/hadoop/app/scala-2.11.8
export SPARK_WOEKER_MEMORY=1g
export SPARK_MASTER_IP=172.29.41.125
export MASTER=spark://172.29.41.125:7077
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_111
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
修改conf/slaves
cp slaves.template slaves

运行:./sbin/start-all.sh

浏览器访问:bigdata-master:8080

spark-shell word-count:
./bin/spark-shell

上传文件到hdfs:

val file=sc.textFile("hdfs://bigdata-master:9000/spark-test")
val count=file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
count.collect()