概率论:基本概念
http://blog.csdn.net/pipisorry/article/details/40709187
本文主要讲解pdf, cdf, 置信区间。
分布函数/累积分布函数CDF
(CDF – Cumulative distribution function 或直接就叫 distribution function)
定义
累积分布函数,又叫分布函数,是概率密度函数的积分,能完整描述一个实随机变量X的概率分布。CDF函数表示随机变量小于或等于其某一个取值x的概率。
对于所有实数x ,累积分布函数定义如下:
X之值落在一区间(a,b]之内的概率为
CDF的性质
- 有界性
- 单调性:
- 右连续性:
X之值落在一区间(a,b]之内的机率为
一随机变数X的CDF与其PDF的关系为
CDF的反函数
若累积分布函数 F 是连续的严格增函数,则存在其反函数。累积分布函数的反函数可以用来生成服从该随机分布的随机变量。设若是概率分布X的累积分布函数,并存在反函数。若a是[0,1)区间上均匀分布的随机变量,则服从X分布。
互补累积分布函数
互补累计分布函数(complementary cumulative distribution function、CCDF),是对连续函数,所有大于a的值,其出现概率的和。
- [ wikipedia累积分布函数]
示例
抛一枚均匀的硬币两次,设随机变量X表示出现正面的次数,那么P(X=0)=P(X=2)=1/4,P(X=1)=1/2,所以这个函数的曲线如下图:

对于这个图,要想清楚清楚如下两个问题:
1)为什么函数始终是右连续的? 因为根据CDF的表达式中的小于等于号,当X=x时,P(X=x)的那部分应该被加到FX上,因此在X=x处有一个值的跃升。如X=1时,P(X=1)已经是1/2了
2)为什么FX(1.4)=0.75? 要注意P(1≤X<2)=1/2(虽然其实X只能取整数值),但是FX是值x之前所有概率的累加,所以FX(1.4)可不是1/2,而是3/4 !!因此F函数始终是非降的,右连续的,且limx→∞F(x)=1
使用累积分布函数进行指标测试
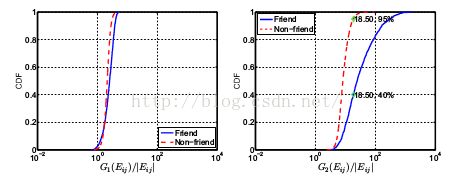
如图右,横轴是某个指标(用于判别是否存在关系的),纵轴是CDF。从图中可知,当这个指标60左右时,基本是只有蓝线Friend了,可区分。
而图左,这个指标并不能很好区分红线和蓝线,就是说这个指标不好。
Note: 某论文中方法,不一定好。
[wiki 累积分布函数]
皮皮blog
概率密度函数/概率分布函数PDF
(PDF – Probability density function)
PDF定义
在数学中,连续型随机变量的概率密度函数(在不至于混淆时可以简称为密度函数)是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。而随机变量的取值落在某个区域之内的概率则为概率密度函数在这个区域上的积分。
对于离散随机变量的PDF为:fX(x)=P(X=x)
最简单的PDF就是比如翻硬币的例子,假如翻正面概率0.4,反面0.6,则这个模型的PDF就是{0.4, 0.6}
对于一维实随机变量X,设它的累积分布函数是。如果存在可测函数 ,满足:
那么X 是一个连续型随机变量,并且是它的概率密度函数。
[概率密度函数是概率分布函数求导吗?]
稍微复杂点的PDF就是univariate Gaussian
概率密度函数某点的值:概率密度的含义
连续分布概率密度函数某个点对应的值表示的是概率密度,也就是分布函数的导数,而不是概率!
lz觉得可以近似将ρ(x)δx δx 看成是随机变量在某个点附近取值的概率。或者可以把这个概率密度看成一个 score ,表示算法对自己得出的这个结果的把握。
ρ(x)δx is the probability of measuring X in [x,x+δx] With ρ(x):= probability density. δx:= interval lenght.
The specific values f(x) of the density function f are the probability densities, and they express "relative probabilities".
The probability density function for a given value of random variable X represents the density of probability (probability per unit random variable) at that particular value of random variable X.
[Difference between Probability and Probability Density]
相对概率"relative probabilities"
Probability distribution describes how much the probabilities are spread across the different outcome. If charted on an x y diagram, this is the shape formed by the function. The probability density on this chart is the Y value. It quantifies the probability of an outcome relative to probabilities of other outcome.
这里解释一下相对概率,或者从使用概率密度的角度解释一下(个人理解):你可以使用概率密度代替实际概率,但是这个使用必须是同其它概率密度相比较而言的。比如你要计算某人在两个不同点的访问概率,就可以使用概率密度近似表达概率(或者你可以认为δx=1了),因为这时是相对的概率,我们没法得到两点各自的真实访问概率(因为是连续分布嘛),但是概率密度表达的效果和概率是近似同等的、成正比的。
[What is the difference between probability distribution and probability density?]
PDF性质
连续型随机变量的概率密度函数有如下性质:
如果概率密度函数在一点 上连续,那么累积分布函数可导,并且它的导数:
由于随机变量X的取值
连续型的随机变量取值在任意一点的概率都是0(但是概率密度不为0,可以为>=0的任意值)。
作为推论,连续型随机变量在区间上取值的概率与这个区间是开区间还是闭区间无关。
要注意的是,概率,但并不是不可能事件,也就是说概率为0的事件不一定是不可能事件。
应用
随机变量X的n阶矩是X的n次方的期望值,即
X的方差为
更广泛的说,设 为一个有界连续函数,那么随机变量的数学期望
特征函数
对机率密度函数作类似傅立叶变换可得特征函数。
特征函数与机率密度函数有一对一的关系。因此,知道一个分布的特征函数就等同于知道一个分布的机率密度函数。
[ wikipedia机率密度函数]其实密度估计density estimation(EM algorithm和Sampling Methods)都是要估计出一个PDF来。
皮皮blog
置信区间
在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计。置信区间展现的是,这个总体参数的真实值有一定概率落在与该测量结果有关的某对应区间。置信区间给出的是,声称总体参数的真实值在测量值的区间所具有的可信程度,即前面所要求的“一定概率”。这个概率被称为置信水平。
举例来说,如果在一次大选中某人的支持率为55%,而置信水平0.95上的置信区间是(50%,60%),那么他的真实支持率落在50%和60%之区间的机率为95%,因此他的真实支持率不足50%的可能性小于2.5%(假设分布是对称的)。
置信水平一般用百分比表示,因此置信水平0.95上的置信区间也可以表达为:95%置信区间。置信区间的两端被称为置信极限。对一个给定情形的估计来说,置信水平越高,所对应的置信区间就会越大,即置信上限和置信下限的差越大。
[wiki 置信区间 ]
from:http://blog.csdn.net/pipisorry/article/details/40709187
ref: 概率论复习 – 基础概率分布