深入理解HashMap
1、HashMap 是什么
HashMap是散列表,K-V键值对集合。
2、HashMap 数据结构
- 容量,增长因子,增长阔值, hashSeed 哈希因子
// 容量 * loadFactor 增长因子 默认= 16 * 0.75 = 12 ,容量的增长,主要原因是尽量避免Hash冲突,就是为了将 Map.Entry线性分布在 Map.Entry[] talbe中,也就是尽量做到 table数组中的元素的 next 为 null;
private int threshold;
//增长因子,默认为0.75 ,
private loat loadFactor;
// 在initHashSeedAsNeeded 初始化,并用于 final int hash(Object k) 方法中,算key的哈希值
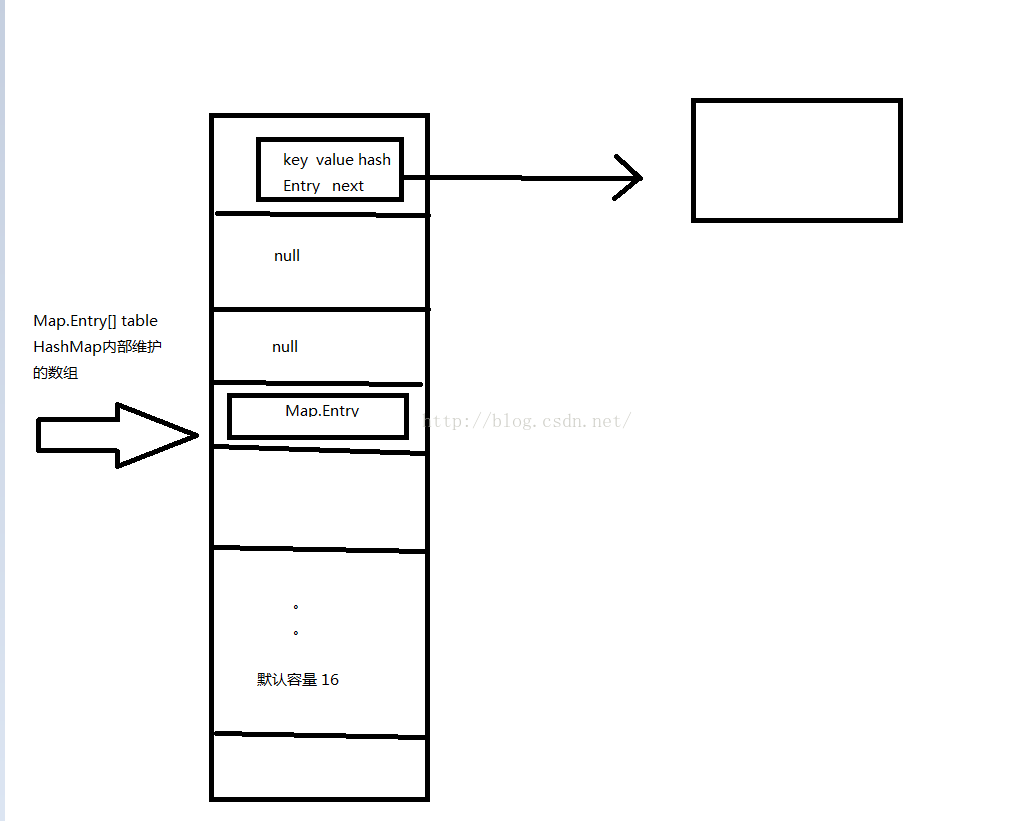
transient int hashSeed = 0; - private transient Map.Entry[] table; 也就是HashMap,内部维护着一个 元素类型为Map.Entry的数组。但这个数组是非连续存放的比如,第1个位置,第4个位置有值,第2个位置,第三个位置为 null。
- Map.Entry
private int hash;
private K key;
private V value;
prinvate Map.Entry next; // 这里是关键中的关键 HashMap 存放图解:
3、核心方法跟踪详解
3.1 put(K key, V value)
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
} 实现思路:首先,table == EMPTY_TABLE,判断是否是空数组,如果是则初始化HashMap table数据结构。inflate 膨胀,扩容的意思。那我们把目光投入到 inflateTable方法中。
/**
* Inflates the table.
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
// 首先计算容量, toSize 容量为 threshold,在构造方法中,threshold默认等于初始容量,也就是16
int capacity = roundUpToPowerOf2(toSize);
// 然后重新算成 threshold的值,默认为 capacity * loadFactor
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//初始化数组 容量为 capacity
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}对于roundUpToPowerOf2解读如下:
首先与MAXIMUM_CAPACITYB比较,基本上不会大于,故主要看 (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
Integer.highestOneBit((number - 1) << 1) 其运行过程如下:
(16 - 1) << 1 15的二进制为 00000000 00000000 00000000 00001111;然后向左移动一位,变为00000000 00000000 00000000 00011110
Integer.highestOneBit 函数,其作用为保留高位的第一个1,其他全部为0,所以,00000000 00000000 00000000 00010000,等于16。
所以在初始化是,,int capacity = roundUpToPowerOf2(threshold),也就是能确保 HashMap的容量保持在2的幂。
然后计算threshold,增长阔值,也就是当容量达到该值后,需要重新扩充容量。
继续上面的代码,执行完 inflate 容量初始化后,调用put方法。
HashMap#put
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
//初始化HashMap数据接口,主要包括 Map.Entry[] table, int threshold, hasSeed;
inflateTable(threshold);
}
// HashTable 支持key 为null
if (key == null)
return putForNullKey(value);
//计算 key 的hash值
int hash = hash(key);
// 根据hash值,和表当前的长度,得到一个在数组中的 下标。重点关注一下indexFor方法的实现。
// 该算法主要返回一个索引,0 - table.length-1的数组下标。
int i = indexFor(hash, table.length);
//接下来,找到 table[i]处,以及该处的数据链,看是否存在相同的key;判断key想到,首先判断hash值
//是否相等,然后再 判断key的equals方法是否相等
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 添加元素到 HashMap,,然后将目光投入到 addEntry方法。
addEntry(hash, key, value, i);
return null;
}
/**
* Returns index for hash code h.
*/
// 该算法主要返回一个索引,0 - table.length-1的数组下标。
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
} 接下来,重点关注 HashMap 增加一个Entry的实现过程。
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// 是否需要扩容的判断
if ((size >= threshold) && (null != table[bucketIndex])) {
// JDK1.7以后的扩容条件;size大于等于threshold,并且新添加元素所在
// 的索引值不等为空,也就是当size达到或超过threshold,新增加元素,只要不会引起hash冲
// 突,则不扩容;JDK1.7之前,只要超过threshold,就扩容。如果需要扩容,长度增长到原来的两
// 倍。接下来关注一下 resize方法的实现
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
//resize 方法元素的复制,在transfer方法中实现,并重新计算 threshold值。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
* table数组及链表的复制。
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 遍历 table 数组
for (Entry e : table) {
while(null != e) { // 如果e 不等为空
// 先找到该节点的下一个节点
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 重新计算该节点在新数组中的索引
int i = indexFor(e.hash, newCapacity);
// 然后将新位置处的元素,当成新加入元素的下一个节点,再该节点放入到i的位置。
e.next = newTable[i];
newTable[i] = e;
//然后继续遍历 e 节点原先的后继节点。
e = next;
}
}
} 这里会产生一个有趣的现象就是在同一个数组索引处的链表,每经过一次resize后,原先排在链表后面的元素,将会排到前面来。
比如如下hashMap结构
index Map.Entry list
0 null null
1 Entry1 Entyr2 ---> Entry3
2 null null
resize 后
index Map.Entry list
0 Entry3 Entry2 ----> Entry1
1 null null
2 null null
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
//首先获取 索引处的值,把这个值当成新节点的next。
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
3.2 HashMap 的遍历
其重点关注:public Set
//首先关注HashMap中一个属性
private transient Set> entrySet = null;
public Set> entrySet() {
return entrySet0();
}
private Set> entrySet0() {
Set> es = entrySet;
return es != null ? es : (entrySet = new EntrySet());
}
以代码的关键点在与 new EntrySet();//什么是EntrySet,原来是HashMap中的一静态的内部类,该类继承AbstractSet类,本身就是一个集合。
private final class EntrySet extends AbstractSet> {
public Iterator> iterator() {
return newEntryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry) o;
Entry candidate = getEntry(e.getKey());
return candidate != null && candidate.equals(e);
}
public boolean remove(Object o) {
return removeMapping(o) != null;
}
public int size() {
return size;
}
public void clear() {
HashMap.this.clear();
}
}
private final class EntryIterator extends HashIterator> {
public Map.Entry next() {
return nextEntry();
}
} 重点关注一下 HashIterator 迭代器
private abstract class HashIterator implements Iterator {
// next entry to return
// 下一个元素,因为我们知道,HashMap内部的 Map.Entry[] table内的元素是非连续
// 的。所以访问下一元素,不能简单的用table[++index]这个概念。
Entry next;
// For fast-fail 遍历时,HashMap结构变化的次数,如果在遍历期间modCount发生变化
// 则直接报错,并结束遍历
int expectedModCount;
// current slot 当前位置
int index;
// current entry 当前元素
Entry current;
HashIterator() {
// 设置开始遍历时,记录HashMap结构调整的次数
expectedModCount = modCount;
if (size > 0) {
// advance to first entry
// 在构造方法时,先在table数组中找到第一不为空的元素,存入next属性中。
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
//判断是否有下一个可迭代元素,只需要判断 next是否为空即可。
return next != null;
}
// 遍历的核心算法
final Entry nextEntry() {
//如果在遍历过程,有新增元素,删除元素动作,就直接抛异常。
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Entry e = next;
// 如果下一个元素为空,直接报元素异常
if (e == null)
throw new NoSuchElementException();
// nextEntry,主要实现思路是:将next的值,赋值给当前元素,
// 然后尝试获取下一个非空Map.Entry元素,找到后,赋值给next元素
if ((next = e.next) == null) {
// 这句很关键,作用,先将 要本次返回的元素 next返回【开始遍历链表了】
// 如果该元素的next为空,
// 说明该元素下面没有链表,说明该hash没有冲突,然后再遍历table数组
// 找到下一个非空元素。
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null);
}
current = e;
return e;
}
public void remove() {
// 将迭代器 中current所存储的元素,对应的key,删除,然后将current域设置为空,并重新设置
// expectedModCount的值等于modCount,,而current的赋值操作,发送在 next方法中,故
// 故,如过在遍历过程中,想删除当前元素,it.remove()方法要在it.next()方法之后调用。
if (current == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
Object k = current.key;
current = null;
HashMap.this.removeEntryForKey(k);
expectedModCount = modCount;
}
} 验证在遍历HashMap时,remove方法与next方法的使用:
public static void main(String[] args) {
// TODO Auto-generated method stub
HashMap a = new HashMap();
a.put("a", "a");
a.put("b", "b");
a.put("c", "c");
a.put("d", "d");
a.put("e", "e");
a.put("f", "f");
int i = 0;
for (Iterator> it = a.entrySet().iterator(); it.hasNext();) {
if(i == 2) { // 如果 修改为 i == 0,,则会抛出异常 IllegalStateException 异常。
it.remove();
}
Map.Entry entry = it.next();
System.out.println(entry.getKey() + ":" + entry.getValue());
i ++;
}
System.out.println(a);
}
本文详细介绍了HashMap的数据存储结构,并详细介绍了HashMap的put方法与遍历,重点提到了HashMap的扩容机制。