Dash-Python-Pandas 随记
1、使用Scatter图时,hoveron 属性的作用是鼠标放在线或者点上是否显示相关内容,points:表示鼠标停在点上会显示点的信息,fills:表示鼠标停在线上显示线的名称,points+fills:表示两者都显示,默认是points;
2、生成图标的 Figure 时,Layout 的 hovermode 属性的作用是当鼠标悬停时以什么为标准去显示内容,x:表示以x轴的刻度显示悬浮内容,y:表示以y轴的刻度显示悬浮内容,closet:表示哪个最近就以哪个为标准。如果我们在使用下面的方式生成一个 Figure时,是不需要设置的,默认就是y:
fig = {
'data': [
go.Scatter(x=[1,2,3], y[2,3,4], name='aaa'),
go.Scatter(x=[1,2,3], y[5,6,7], name='bbb'),
],
'layout': {
'title': '这个模式鼠标悬停在x=1的位置时,会同时把‘aaa’和‘bbb’两个数据都显示出来',
},
}还有另一种形式:
fig = go.Figure()
fig.add_trace(go.Scatter(x=[1,2,3], y[2,3,4], name='aaa'))
fig.add_trace(go.Scatter(x=[1,2,3], y[5,6,7], name='bbb'))
fig.update_layout(
title='这个形式如果鼠标放在x=1的位置,还需要靠近每个线的点才会显示,这就不能对比了',
hovermode='x', # 如果不指定,默认是 closet,需要鼠标靠近线才行,这里我指定了x轴
)3、Figure.Layout 对于xaxis和yaxis属性,里面可以设置 domain ,这是可以设置图表 x 和 y 方向的宽度的,默认是:[0, 1]
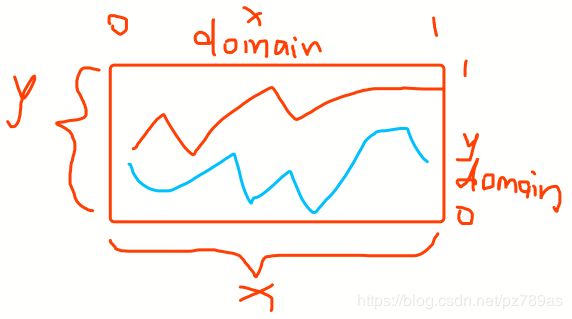
如果在有些情况x轴的名字可能显示不下,那么可以通过调整y轴的高度来展示全x轴名称,比如:[0.3, 1]:
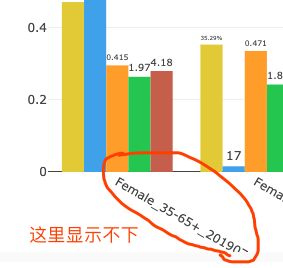 改了之后
改了之后 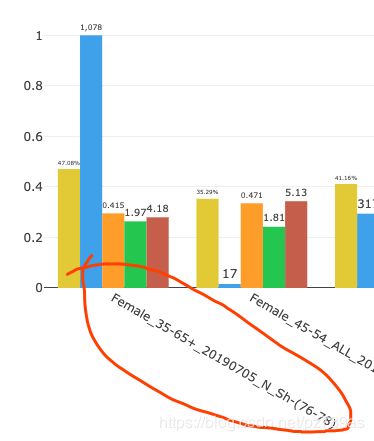
y轴也是同理
4、在使用 Pandas 处理数据时,有一列是时间格式,并且时间带了时分秒,当时我们在做统计的时候,可能需要用到每天下载有多少,所以我们需要把时间的时分秒无视掉。
在根据条件筛选时,还算比较方便:
df = df[df['下载时间'] == date(2019, 1, 1)]如果要使用 groupby 的时候改怎么办呢,那估计有多少条就有多少组了。我们可以先做个处理:
df['download_date'] = df['下载日期'].dt.floor('D') # 先把日期转化一次,让它精确到天
# df['download_date'] = df['下载日期'].apply(lambda x: datetime.fromordinal(pd.Timestamp(x).to_pydatetime().date().toordinal())) # 用来检验是否正确的语句,等效于上面的
df = df.groupby('download_date').agg({'user_id': 'nunique'}) # 然后再用转化的列去做分组即可5、