正文之前
这篇文章可有点叼了。。。废话不多说,看图!
引用如下:Amit N, Wei M. The design and implementation of hyperupcalls[C]//2018 {USENIX} Annual Technical Conference ({USENIX}{ATC} 18). 2018: 97-112.
然后照样是长篇的翻译。。当然,主力是谷歌,我负责人工审核一波。。PPT我也有,如果有需要的可以不去麻烦作者了,(作者如果没人提醒估计是不会回你的。。我还是找了他学生才拿到的,不过貌似有个网站,他把PPT都丢了上去,不过我忘了)

正文
摘要
虚拟机抽象提供了各种各样的好处,无可否认地支持了云计算。 然而,虚拟机是双重的 一把双刃剑,因为他们运行于其上的Hypervisor必须将他们视为黑盒,这限制了他们之间能够交换的信息。 在本文中,我们介绍了一种新机制hyperupcalls的设计和实现,它使Hypervisor能够安全地执行Guest虚拟机提供的验证代码,以便传输信息。 Hyperupcalls是用C语言编写的,可以完全访问Guest数据结构,例如页表。 我们提供了一个完整的框架,可以从hyperupcall中轻松访问熟悉的内核函数。 与最先进的半虚拟化技术和虚拟机内省相比,Hyperupcalls更灵活,更少侵入。 我们证明,hyperupcalls不仅可以用于将某些操作的Guest性能提高多达2倍,而且hyperupcalls也可以用作强大的调试和安全工具。
1 简介
硬件虚拟化引入了虚拟机(VM)的抽象,使得称为Hypervisor的主机能够同时运行称为Guest机的多个操作系统(OS),每个操作系统都假设它们在自己的物理机器上运行。 这是通过暴露模拟真实物理硬件的硬件接口来实现的。 这种简单抽象的引入导致了现代数据中心和云的兴起,正如我们今天所知道的那样。 不幸的是,虚拟化并非没有缺点。 虽然虚拟化的目标是为VM和Hypervisor彼此分开,这种分离使得双方无法理解在另一侧做出的决定,被称为语义间隙问题 。
【The semantic gap characterizes the difference between two descriptions of an object by different linguistic representations, for instance languages or symbols. According to Hein, the semantic gap can be defined as "the difference in meaning between constructs formed within different representation systems".
语义间隙通过不同的语言表示(例如语言或符号)来表征对象的两个描述之间的差异。 根据Hein的说法,语义差距可以定义为“在不同表示系统中形成的构造之间的意义差异”。】
解决语义差距对性能至关重要。 如果没有关于Guest决策的信息,Hypervisor可能会次优地分配资源。 例如,Hypervisor无法在不了解其内部操作系统状态的情况下知道guest虚拟机中的哪些内存空闲,从而破坏了VM抽象。 如今,最先进的Hypervisor通常通过半虚拟化[11,58]弥合语义鸿沟,这使得Guest了解Hypervisor。 半虚拟化使Guest免受物理硬件接口的限制,并允许与Hypervisor直接信息交换,通过使Hypervisor能够做出更好的资源分配决策来提高整体性能。
然而,半虚拟化涉及在Hypervisor和Guest机的上下文中执行代码。 Hypercalls要求Guest发出一个在Hypervisor中执行的请求,就像系统调用一样,并且upcalls要求Hypervisor发出请求在Guest中执行。 这种设计带来了许多缺点。 首先,半虚拟机制在Hypervisor和Guest机之间引入了上下文切换,如果需要Guest机和Hypervisor之间的频繁交互,这可能是实质性的[7]。 其次,半虚拟机制的请求者必须等待它在另一个可能正忙的上下文中服务,或者如果它是空闲的则唤醒该Guest。 最后,半虚拟机制将Hypervisor和Guest机的设计结合起来:需要为每个Guest机和Hypervisor实现半虚拟机制,从而增加复杂性[46]并妨碍可维护性[77]。 添加准虚拟功能需要使用新接口更新guest虚拟机和Hypervisor[69],并且有可能引入错误和攻击面[47,75]。
【每一段程序都有很多外部变量。只有像Add这种简单的函数才是没有外部变量的。一旦你的一段程序有了外部变量,这段程序就不完整,不能独立运行。你为了使他们运行,就要给所有的外部变量一个一个写一些值进去。这些值的集合就叫上下文。譬如说在C++的lambda表达是里面,[写在这里的就是上下文](int a, int b){ ... }。】
一种不同的技术,VM内省(VMI)[25]和反向,Hypervisor内省(HVI)[72]旨在通过内省其他上下文来解决半虚拟化的一些缺点,实现无需上下文切换或先前协调的通信传输。 然而,这些技术是脆弱的:数据结构,行为甚至安全加强的微小变化[31]可能会打破内省机制,或者更糟糕的是,引入安全漏洞。 因此,内省通常被归入入侵检测系统(IDS)领域,该系统可检测恶意软件或行为不当的应用程序。
【VMI tools may be located inside or outside the virtual machine and act by tracking the events (interrupts, memory writes, and so on) or sending the requests to the virtual machine. Virtual machine monitor usually provides low-level information like raw bytes of the memory. Converting this low-level view into something meaningful for the user is known as the semantic gap problem. Solving this problem requires analysis and understanding of the systems being monitored.
VMI工具可以位于虚拟机内部或外部,并通过跟踪事件(中断,内存写入等)或将请求发送到虚拟机来执行操作。虚拟机监视器通常提供低级信息,如内存的原始字节。将此低级视图转换为对用户有意义的内容称为语义缺口问题。解决这个问题需要分析和理解被监控的系统。
VMI:即Virtual Machine Introspection,VMI是一种用于在外部监测系统级虚拟机运行状态的技术。监测器可置于另一个虚拟机,在VMM内部或在虚拟化架构的任何其他部分。在VMI过程中,VM的运行状态可被广义地定义为包括处理器寄存器、内存、磁盘、网络及任何硬件级事件。】
在本文中,我们描述了hyperupcalls 1的设计和实现,这种技术使Hypervisor能够与Guest进行通信,如upcalls,但没有这样的上下文切换,像VMI。 这是通过使用经过验证的代码实现的,该代码使Guest能够以灵活的方式与Hypervisor进行通信,同时确保Guest不能提供行为不当或恶意代码。 一旦Guest注册了一个hyperupcall,Hypervisor就可以执行它来执行诸如定位空闲Guest页面或运行Guest中断处理程序而不切换到Guest的操作。
Hyperupcalls易于构建:它们是用C语言等高级语言编写的,我们提供了一个框架,允许hyperupcalls共享相同的代码库并构建系统,因为Linux内核可以推广到其他操作系统。 编译内核时,工具链会将hyperupcall转换为可验证的字节码。 这样可以轻松维护hyperupcalls。 在引导时,guest虚拟机向hypervisor注册hyperupcalls,Hypervisor验证字节码并将其编译回本机代码以获得性能。 一旦重新编译,Hypervisor可以随时调用hyperupcall。
我们表明,使用hyperupcalls可以通过允许Hypervisor主动分配资源来显着提高性能,而不是等待guest虚拟机通过现有机制做出反应。 我们构建用于内存回收和处理内部处理器中断(IPI)的hyperupcalls,并显示高达2 x的性能提升。除了提高性能之外,hyperupcall还可以增强虚拟环境中系统的安全性和可调试性。 我们开发了一个hyperupcall,使Guest能够在不使用专用硬件的情况下对内存页面进行写保护,另一个使ftrace [57]能够在统一的跟踪中捕获Guest和Hypervisor事件,从而使我们能够在虚拟化环境中获得新的性能视野。
【write-protect写保护是硬件设备或软件程序阻止写入新信息或更改旧信息的能力。 通常,这意味着您可以读取数据,但不能写入。 图中是SD卡上的写保护开关示例,用于打开和关闭该卡上的写保护。
Ftrace是一个直接内置于Linux内核的跟踪实用程序。 许多发行版在其最新版本中已经启用了各种Ftrace配置。 Ftrace为Linux带来的好处之一是能够查看内核中发生的事情。】
本文做出以下贡献:
我们建立了一种机制分类,用于弥合Hypervisor和Guest之间的语义鸿沟,并在该分类中放置Hyperupcalls
-
我们用以下内容描述和实现hyperupcalls(§3):
- 编写hyperupcalls的环境和使用Guest代码的框架(§3.1)
- 用于hyperupcalls的编译器(§3.2)和验证器(§3.4),它解决了验证代码的复杂性和局限性。
- Hyperupcalls的注册(§3.3)和执行(§3.5)机制。
我们对hyperupcalls进行原型设计和评估,并表明hyperupcalls可以提高性能(§4.3,§4.2),安全性(§4.5)和可调试性(§4.4)。
2 沟通机制
现在人们普遍认为,为了从虚拟化中提取最大的性能和实用性,Hypervisor及其Guest需要彼此了解。 为此,存在许多促进Hypervisor和Guest之间通信的机制。 表1总结了这些机制,这些机制可以由请求者,执行者以及机制是否要求Hypervisor和Guest提前协调来广泛地表征。

在下一节中,我们将讨论这些机制并描述hyperupcall如何满足通信机制的需求,其中Hypervisor在没有上下文切换的情况下制作并执行其自己的请求。 我们首先介绍当今使用的最先进的半虚拟机制。
2.1半虚拟化
超级呼叫和上行呼叫。 如今,大多数Hypervisor都利用半虚拟化来跨语义鸿沟进行通信。 目前广泛使用的两种机制是超级调用,它允许Guest调用Hypervisor提供的服务和upcalls,这使得Hypervisor可以向Guest发出请求。 半虚拟化意味着这些机制的接口在Hypervisor和Guest之间提前协调[11]。
上行呼叫和超级呼叫的主要缺点之一是它们需要上下文切换,因为两种机制都在请求的相反侧执行。 因此,必须小心调用这些机制。 过于频繁地调用hypercall或upcalls会导致高延迟和计算资源浪费[3]。
upcalls的另一个缺点,特别是请求由可能是忙于处理其他任务的Guest处理。 如果Guest忙碌或Guest闲置,则会因为等待Guest机有空闲或者唤醒而产生而外的惩罚。 这可能需要无限的时间,并且Hypervisor可能不得不依赖惩罚系统来确保Guest在合理的时间内做出响应。
最后,通过增加Hypervisor与其Guest之间的耦合,半虚拟机制可能难以维持。 每个Hypervisor都有自己的半虚拟接口,每个guest虚拟机必须实现每个Hypervisor的接口。 半虚拟接口并不薄:微软的半虚拟接口规范长达300页[46]。 Linux提供了各种准虚拟钩子,Hypervisor可以使用它们与VM进行通信[78]。尽管努力使半虚拟化接口标准化 ,但它们彼此不兼容,并随着时间的推移而发展,添加功能甚至删除一些功能(例如,MicrosoftHypervisor事件跟踪)。 因此,大多数Hypervisor并不完全支持标准化接口的工作,而专业操作系统则寻找替代解决方案[45,54]。
预虚拟化。 预虚拟化[42]是Guest从Hypervisor请求服务的另一种机制,但请求是在Guest自身的上下文中提供的。 这是通过代码注入实现的:Guest端留下存根,Hypervisor用Hypervisor代码填充。 预虚拟化提供了对hypercalls的改进,因为它们在Guest和Hypervisor之间提供了更灵活的接口。 可以说,预虚拟化存在一个基本限制:在guest虚拟机中运行的代码是剥离的,无法执行敏感操作,例如,访问共享I/O设备。 因此,在预虚拟化中,在Guest端中运行的超级代码仍然需要使用hypercalls与特权Hypervisor代码进行通信。
2.2内省
当Hypervisor或Guest尝试从其他上下文中推断信息而不直接与其进行通信时,就会发生自省。 通过内省,无需任何接口或协调。 例如,Hypervisor可能仅仅通过其存储器访问模式来尝试推断完全未知的Guest的状态。 内省和半虚拟化之间的另一个区别是没有发生上下文切换:执行内省的所有代码都在请求者中执行。
虚拟机内省(VMI)。 当Hypervisor对Guest进行内省时,它被称为VMI [25]。 首次引入VMI是为了通过从特权主机提供入侵检测(IDS)和内核完整性检查来增强VM安全性[10,24,25]。 VMI还应用于检查点和重复数据删除VM状态[1],以及监控和实施Hypervisor策略[55]。 这些机制的范围从简单地观察VM的内存和I/O访问模式[36]到访问VM OS数据结构[16],并且在最末端它们可以修改VM状态甚至直接将进程注入其中[26,19]。 VMI的主要好处是Hypervisor可以在没有上下文切换的情况下直接调用VMI,并且guest虚拟机无需“意识到”检查VMI是否正常运行。 但是,VMI很脆弱:VM OS中的一个无害的变化,例如为数据结构添加额外字段的修补程序可能会导致VMI无法正常工作[8]。 因此,VMI往往是一种“尽力而为”的机制。
HVI。 在较小程度上,Guest可能会反省它正在运行于其上的Hypervisor,称为Hypervisor内省(HVI)[72,61]。 HVI通常用于保护VM免受不受信任的Hypervisor[62]或恶意软件以绕过Hypervisor安全[59,48]。
2.3可扩展的操作系统
虽然Hypervisor提供了固定的界面,但OS研究表明,多年来灵活的操作系统界面可以在不牺牲安全性的情况下提高性能。 Exokernel提供了低级原语,并允许应用程序实现高级抽象,例如内存管理[22]。 SPIN允许扩展内核功能以提供特定于应用程序的服务,例如专门的进程间通信[13]。 使这些扩展能够在不影响安全性的情况下运行良好的关键特性是使用简单的字节代码来表达应用程序需求,并在与内核相同的保护环上运行此代码。 我们的工作受到这些研究的启发,我们的目标是在Hypervisor和Guest之间设计一个灵活的界面,以弥合语义鸿沟。
2.4 Hyperupcalls
本文介绍了hyperupcalls,它满足了Hypervisor与guest虚拟机通信的机制的需求,该机制是协调的(与VMI不同),由Hypervisor本身执行(与upcalls不同)并且不需要上下文切换(与hypercalls不同)。通过hyperupcalls,VM通过注册可验证代码与Hypervisor进行协调。 然后,Hypervisor响应于事件(例如内存压力或VM进入/退出)执行该代码。 在某种程度上,hyperupcalls可以被认为是由Hypervisor执行的upcalls。
与VMI相比,访问VM状态的代码由guest提供,因此hyperupcalls完全了解guest虚拟机内部数据结构 - 实际上,hyperupcalls是使用guest虚拟机操作系统代码库构建的,并共享相同的代码,从而简化了维护,同时提供了操作系统具有表达机制来向底层Hypervisor描述其状态。
与Hypervisor向guest虚拟机发出异步请求的upcalls相比,Hypervisor可以随时执行hyperupcall,即使guest虚拟机未运行也是如此。 通过upcalls,Hypervisor受到Guest的支配,这可能会延迟upcalls[6]。 此外,由于upcalls的操作类似于远程请求,因此upcalls可能会被迫以不同的方式实现OS功能。 例如,当刷新用于识别空闲Guest内存的规范技术时的ballooning中的远程页面[71]时,Guest使用虚拟进程来释放内存压力以释放页面。 通过hyperupcall,Hypervisor可以像Guest内核线程一样,直接扫描Guest的空闲页面。
【Blooning 在虚拟机上安装的VMtools就包括了ballooningdriver。它告诉Hypervisor哪些不活动的内存页面可以被收回。这对虚拟机上应用的性能是没有任何影响的。】
Hyperupcalls类似于预虚拟化,因为代码是跨语义间隙传输的。 传输代码不仅可以实现更具表现力的通信,还可以将请求的执行移至间隙的另一端,从而增强性能和功能。 与预虚拟化不同,Hypervisor不能信任虚拟机提供的代码,并且Hypervisor必须确保高调用的执行环境在调用之间保持一致。
3 架构
Hyperupcalls是由guest虚拟机提供给Hypervisor的简短可验证程序,用于提高性能或提供其他功能。 guest虚拟机通过启动时的注册过程向Hypervisor提供hyperupcall,允许Hypervisor访问guest虚拟机操作系统状态,并在验证后通过执行它们来提供服务。 Hypervisor运行hyperupcalls以响应事件或何时需要查询guest状态。 hyperupcalls的体系结构和我们为利用它们而构建的系统如图1所示。
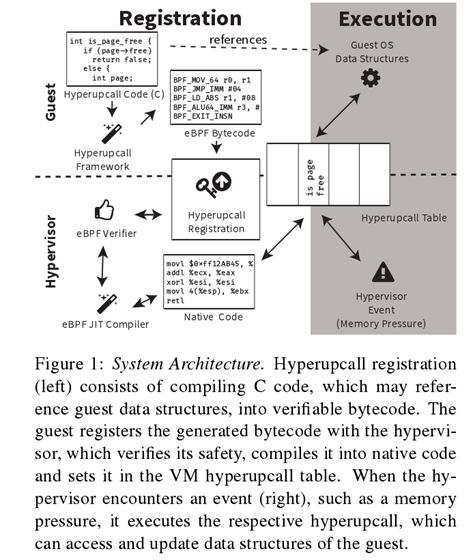
我们的目标是使hyperupcalls尽可能简单地构建。 为此,我们提供了一个完整的框架,允许程序员使用Guest操作系统代码库编写hyperupcalls。 这极大地简化了hyperupcalls的开发和维护。 该框架将此代码编译为可验证的代码,Guest向Hypervisor注册。 在下一节中,我们将描述OS开发人员如何使用我们的框架编写hyperupcall。
3.1构建Hyperupcalls
Guest操作系统开发人员为他们希望处理的每个Hypervisor事件编写hyperupcall。 Hypervisor和Guest同意这些事件,例如VM进入/退出,页面映射或虚拟CPU(VCPU)抢占。 每个hyperupcall都由预定义的标识符标识,非常类似于UNIX系统调用接口[56]。 表2给出了hyperupcall可以处理的事件的示例。

3.1.1提供安全代码
hyperupcalls的一个关键属性是必须保证代码不会破坏Hypervisor。 为了使hyperupcall安全,它必须只能访问由Hypervisor指示的受限内存区域,运行一段有限的时间而不会阻塞,休眠或锁定,并且只能使用明确允许的Hypervisor服务。
由于Guest不受信任,Hypervisor必须建立一个保证这些安全属性的安全机制。 我们可以选择许多解决方案:软件故障隔离(SFI)[70],携带证据的代码[51]或安全语言,如Rust。 为了实现hyperupcalls,我们选择了增强型Berkeley Packet Filter(eBPF)VM。
我们选择eBPF有几个原因。 首先,eBPF相对成熟:BPF是在20多年前引入的,并且在整个Linux内核中广泛使用,最初用于包过滤,但扩展到支持其他用例,如沙盒系统调用(seccomp)和内核事件跟踪[34] 。 eBPF受到广泛采用,并得到各种运行时的支持[14,19]。 其次,可以证明eBPF具有我们所需的安全属性,并且Linux附带验证器和JIT,用于验证和有效执行eBPF代码[74]。 最后,eBPF有一个LLVM编译器后端,它使用编译器前端(Clang)从高级语言生成eBPF字节码。 由于操作系统通常用C语言编写,因此eBPF LLVM后端为我们提供了一种简单的机制,可将不安全的Guest操作系统源代码转换为可验证的安全eBPF字节码。
3.1.2从C到eBPF 一 框架
不幸的是,写一个hyperupcall并不像在eBPF字节码中重新编译OS代码那么简单。 但是,我们的框架旨在使编写hyperupcalls的过程尽可能简单和可维护。 该框架提供了三个关键功能,简化了hyperupcalls的编写。 首先,框架负责处理Guest地址转换问题,因此guest OS符号可用于hyperupcall。 其次,该框架解决了eBPF对C代码施加了很大的限制的局限性。 最后,框架定义了一个简单的接口,它为 hyperupcall 提供了数据,因此可以高效,安全地执行。
Guest操作系统符号和内存。 即使hyperupcalls可以访问guest虚拟机的整个物理内存,访问guest虚拟机操作系统数据结构也需要知道它们驻留的位置。 操作系统通常使用内核地址空间布局随机化(KASLR)来随机化OS符号的虚拟偏移,使其在编译期间未知。 我们的框架通过使用地址空间属性关联指针并注入代码来调整指针,从而在运行时解析OS符号偏移。 当注册hyperupcall时,guest虚拟机提供实际的符号偏移,使hyperupcall开发人员能够在C代码中引用OS符号(变量和数据结构),就像它们被内核线程访问一样。
全局/本地Hyperupcalls。 并非所有的hyperupcall都需要及时执行。 例如,通知Guest机Hypervisor事件(例如VM进入/退出或中断注入)的通知仅影响Guest机而不影响Hypervisor。 我们指的是只影响将其注册为guest虚拟机的本地的hyperupcalls,以及影响整个Hypervisor作为全局的hyperupcalls。 如果将超级调用注册为本地,我们放宽时序要求并允许超级调用阻塞和休眠。 本地hyperupcalls在Guest的VCPU时间中与捕获类似,因此行为不端的超级调用会对自己进行惩罚。
但是,全局超级调用必须及时完成执行。 我们确保对于Guest操作系统,全局hyperupcalls请求的页面在超级调用期间被固定,并将可访问的内存限制为Guest总物理内存的2%(可配置)。 由于本地hyperupcalls可能会阻塞,因此他们使用的内存不需要固定,允许本地hyperupcalls来解决所有·Guest内存。
解决eBPF限制。虽然eBPF具有表现力,但eBPF字节码的安全保证意味着它不是图灵完备且有限的,因此只有一部分C代码可以编译成eBPF。 eBPF的主要限制是它不支持循环,ISA不包含原子,不能使用自修改代码,函数指针,静态变量,本机汇编代码,并且不能太长且复杂而无法验证。
这些限制的后果之一是hyperupcall开发人员必须意识到hyperupcall的代码复杂性,因为复杂的代码将使验证者失败。 虽然这似乎是一个不直观的限制,但其他使用BPF的Linux开发人员面临同样的限制,我们在框架中提供了一个辅助函数来降低复杂性,例如memset和memcpy,以及执行本机原子操作的函数,如CMPXCHG。 表3中显示了这些辅助函数的选择。此外,我们的框架掩盖了内存访问( 第 3.4 章 ),这大大降低了验证的复杂性。 在实践中,只要我们小心地展开循环,我们在使用 4096指令的设置和1024的堆栈深度 开发( 第 4 章 )中 的用例时没有遇到验证者问题 。

Hyperupcall接口。 当Hypervisor调用hyperupcall时,它会填充一个上下文数据结构,如表4所示. hyperupupall接收一个事件数据结构,它指示调用回调的原因,以及一个指向guest虚拟机的指针(在Hypervisor的地址空间中,正在执行hyperupcall)。 当hyperupcall完成时,它可以返回一个值,该值可以由Hypervisor使用。

编写hyperupcall。 借助我们的框架,操作系统开发人员编写C代码,可以访问操作系统变量和数据结构,并辅以框架的辅助功能。 典型的hyperupcall将读取事件字段,读取或更新OS数据结构并可能将数据返回到Hypervisor。 由于hyperupcall是操作系统的一部分,开发人员可以引用操作系统本身使用的相同数据结构 - 例如,通过头文件。 这大大增加了hyperupcalls的可维护性,因为数据布局更改在OS源和hyperupcall源之间同步。
值得注意的是,hyperupcall不能直接调用guest虚拟机操作系统函数,因为该代码尚未受到框架的保护。 但是,OS功能可以编译为hyperupcalls并集成在经过验证的代码中。
3.2编译
一旦写入了Hyperupcall,就需要将其编译成eBPF字节码,然后Guest才能将其注册到Hypervisor。 我们的框架通过Clang和eBPF LLUM后端运行hyperupcall C代码,生成此字节码作为Guest操作系统构建过程的一部分,并进行一些修改以协助地址转换和验证:
Guest内存访问。 为了访问Guest内存,我们使用eBPF的直接数据包访问(DPA)功能,该功能旨在允许程序在不使用辅助功能的情况下安全有效地访问网络数据包。 我们不是传递网络数据包,而是将Guest端视为“数据包”。 以这种方式使用DPA需要对eBPF LLUM后端进行错误修复[2],因为它是在假设数据包大小为G64KB的情况下编写的。
地址翻译。 Hyperupcalls允许Hypervisor无缝地使用Guest虚拟地址(GVA),这使得它看起来好像是在guest虚拟机中运行了hyperupcall。 但是,代码实际上是由Hypervisor执行的,其中使用了主机虚拟地址(HVAs),使得Guest机指针无效。 为了允许在主机上下文中透明地使用Guest指针,因此需要将这些指针从GVA转换为HVAs。 我们使用编译器进行这些翻译。
为简化此转换,Hypervisor将GVA范围连续映射到HVA空间,因此可以通过调整基址轻松完成地址转换。 由于guest虚拟机可能需要hyperupcall来访问多个连续的GVA范围 - 例如,一个用于guest 1:1直接映射和OS文本部分[37] - 所以框架使用其各自的“地址空间”属性来注释每个指针。 我们扩展LLUM编译器以使用此信息来注入eBPF代码,该代码通过简单的减法操作将每个指针从GVA转换为HVA。 应当注意,生成的代码安全性不是由Hypervisor承担的,并且在注册Hyperupcall时被验证。
绑定检查。 验证者拒绝直接内存访问的代码,除非它可以确保内存访问在“数据包”(在我们的例子中是Guest内存)边界内。 我们不能指望hyperupcall程序员执行所需的检查,因为添加它们的负担很大。 因此,我们增强编译器以自动添加在每次 内存访问 之前执行绑定检查的代码 ,从而允许验证通过。 正如我们在3.4节中所述,边界检查是使用屏蔽完成的,而不是分支以简化验证。
上下文缓存。 我们的编译器扩展引入了内在函数来获取指向上下文的指针或读取其数据。 在回调中经常需要上下文来调用辅助函数和转换GVA。将上下文作为函数参数需要进行侵入式更改,并且可以防止guest虚拟机与其Hyperupcall之间共享代码。 相反,我们使用编译器将上下文指针缓存在其中一个寄存器中,并在需要时检索它。
3.3注册
将hyperupcall编译成eBPF字节码后,就可以注册了。 guest可以随时注册hyperupcalls,但大多数hyperupcalls都是在Guest引导时注册的。 guest提供hyperupcall事件ID,hyperupcall字节码和hyperupcall将使用的虚拟内存。 每个参数如下所述:
- Hyperupcall事件ID。 要处理的事件的ID。
- 内存注册。 guest虚拟机注册hyperupcall使用的虚拟连续内存区域。 对于全局hyperupcalls,此内存最多限制为guest虚拟机总物理内存的2%(可由Hypervisor配置和实施)。
- Hyperupcall字节码。 guest提供了一个指向hyperupcall字节码及其大小的指针。
3.4验证
Hypervisor验证每个hyperupcall在注册时是否安全。 我们的验证程序基于Linux eBPF验证程序,并检查hyperupcall的三个属性:内存访问,运行时指令数和使用的辅助函数。
理想情况下,验证是合理的,确保只有安全的代码才能通过验证,并且能够完整、成功验证任何安全程序。 虽然健全性不会因为可能危及系统安全而受到损害,但许多验证系统(包括eBPF)都会牺牲完整性来保证验证者的简单性。 在实践中,验证者要求以某种方式编写程序以通过验证 [66] ,即使这样,验证也可能由于路径爆炸而失败。 这些限制与我们使hyperupcalls易于构建的目标不一致。
我们将讨论下面的验证程序检查的属性,以及我们如何简化这些检查以使验证尽可能简单。
有界运行时指令。 对于全局hyperupcalls,eBPF验证程序确保hyperupcall的任何可能执行都包含有限数量的指令,这些指令由Hypervisor设置(默认为4096)。 这可以确保Hypervisor可以及时执行hyperupcall,并且没有无限循环可以导致hyperupcall不退出。
内存访问验证。 验证器确保存储器访问仅发生在由“分组”限定的区域中,该分组在超级调用中是在注册期间提供的虚拟存储器区域。 如前所述,我们增强编译器以自动添加代码,证明每个内存访问都是安全的验证者。
但是,天真地添加这样的代码会导致频繁的验证失败。 当前的Linux eBPF验证程序在验证内存访问安全性方面的能力非常有限,因为它要求它们之前会有比较和分支指令,以防止出现绑定访问。 验证者探索可能的执行路径并确保其安全性。 虽然验证者采用各种优化来修剪分支并避免走在每个可能的分支上,但验证通常耗尽可用资源并且因为我们和其他人经历过而失败[65]。
因此,我们的增强编译器不是使用compare和branch来确保内存访问安全,而是添加了掩盖每个范围内的内存访问偏移的代码,从而防止了越界内存访问。 我们增强验证程序以将此屏蔽识别为安全。 应用此增强功能后,我们编写的所有程序都通过了验证。
辅助功能安全。 Hyperupcalls可以调用辅助函数来提高性能并帮助限制运行时指令的数量。 辅助函数是标准的eBPF特性,验证者强制执行可以调用的辅助函数,这些函数可能因事件而异,具体取决于Hypervisor策略。 例如,Hypervisor可能在内存回收期间不允许使用flush_tlb_vcpu,因为它可能会阻塞系统一段延长的时间。
验证程序检查以确保辅助函数的输入是安全的,确保辅助函数仅访问允许访问的内存。 虽然可以在辅助函数中完成这些检查,但新的eBPF扩展允许验证程序静态验证辅助函数输入。 此外,Hypervisor还可以基于每个事件设置输入策略(例如,全局超级调用的内存大小)。
辅助函数的数量和复杂性也应该受到限制,因为它们成为可信计算基础的一部分。因此,我们仅介绍简单的辅助函数,这些函数主要依赖于guest虚拟机可以直接或间接触发的代码,例如中断注入。
eBPF安全性。最近发现的“幽灵”硬件漏洞[38,30]的两个概念验证漏洞攻击目标是eBPF,这可能会引发对eBPF和高呼叫安全性的担忧。如果攻击者可以在特权上下文中运行非特权代码,那么利用这些漏洞就更容易了,就像hyperupcalls那样,可以防止发现的攻击[63]。实际上,这些安全漏洞可能会使hyperupcall更具吸引力,因为当使用传统的半虚拟机制(如upcalls和hypercalls)进行上下文切换时,它们的缓解技术(例如,返回堆栈缓冲区填充[33])会产生额外的开销。
3.5执行
已验证的hyperupcalls安装在每个guest虚拟机hyperupcall表中。一旦注册并验证了超级调用,Hypervisor就会响应事件执行hyperupcall。
Hyperupcall补丁。为了避免测试hyperupcall是否已注册的开销,Hypervisor使用代码修补技术,在Linux中称为“静态密钥”[12]:只有当hyperupcalls是已注册的状态时,才会在每个Hypervisor上的Hyperupcall调用代码上设置一个无操作指令。
访问远程VCPU状态。一些hyperupcalls读取或修改远程VCPU的状态。这些VCPU可能没有运行,或者它们的状态可能被Hypervisor的不同线程访问。即使远程VCPU被抢占,Hypervisor也可能已经读取了一些寄存器,并且在VCPU恢复执行之前不会期望它们发生变化。如果hyperupcall写入远程VCPU寄存器,它可能会破坏Hypervisor的常量甚至引入安全问题。
【vCPU代表虚拟中央处理单元。 将一个或多个vCPU分配给云环境中的每个虚拟机(VM)。 VM的操作系统将每个vCPU视为单个物理CPU核心。 如果主机具有多个CPU核心,那么vCPU实际上由所有可用核心上的多个时隙组成,从而允许多个VM托管在较少数量的物理核心上。】
此外,读取远程VCPU寄存器会导致高开销,因为VCPU状态的一部分可能被缓存在另一个CPU中,并且如果要读取VCPU状态,则必须首先将其写回存储器。更重要的是,在Intel CPU中,VCPU状态不能通过公共指令访问,并且必须首先“加载”VCPU,然后才能使用特殊指令(VMREAD和VMWRITE)访问其状态。切换加载的VCPU会产生很大的开销,我们的系统大约需要1800个周期。
为了提高性能,我们定义了通常抢占Hypervisor的同步点,并且已知访问VCPU状态是安全的。在这些点上,我们从VMCS“解密”VCPU寄存器并将它们写入存储器,以便hyperupcall可以读取它们。超级调用写入远程VCPU寄存器并更新已分解的值以标记Hypervisor,以在恢复该VCPU之前将寄存器值重新加载到VMCS中。访问远程VCPU的Hyperupcalls以尽力而为的方式执行,仅在VCPU处于同步点时运行。在hyperupcall运行时,防止远程VCPU恢复执行。
使用Guest操作系统锁。一些OS数据结构受锁保护。需要一致的Guest操作系统数据结构视图的Hyperupcalls应遵守Guest操作系统规定的同步方案。然而,Hyperupcall只能机会性地获取锁,因为VCPU可能在持有锁时被抢占。可能需要调整锁实现以支持外部实体的锁定,而不是任何VCPU。释放锁可能需要相对较大的代码来处理慢速路径,这可能会阻止及时验证超级调用。
虽然可能会提出各种临时解决方案,但似乎完整的解决方案要求Guest操作系统锁定具有高上报功能。它还需要支持从eBPF代码调用eBPF函数,以避免可能导致验证失败的代码大小膨胀。由于最近添加了此支持,我们的实现不包括锁支持。
4 用例和评估
我们的评估 由以下问题指导:
- 使用经过验证的代码(eBPF)与本机代码的开销是多少?(章节4.1)
- hyperupcalls 和其他半虚拟化机制的对比(章节4.3,4.2,4.5)?
- hyperupcalls如何不仅可以提高性能(章4.3,4.2),而且安全性(章节4.5)和可调试(章4.4 虚拟化环境的)?
测试平台。我们的测试平台包括一个带有Intel ES-2670 CPU的48核双插槽Dell PowerEdge 8630服务器,一个希捷ST1200磁盘,它运行带有Linux内核v4.8的Ubuntu 17.04。基准测试适用于具有16个VCPU和8GB RAM的guest虚拟机。每次测量进行5次,并报告平均结果。
Hyperupcall原型。我们在Linux v4.8和KVM上实现了一个用于hyperupcall支持的原型,这是一个集成在Linux中的Hypervisor。 Hyperupcalls通过修补的LLVM 4进行编译,并通过Linux内核eBPF验证程序使用我们在第3章中描述的补丁进行验证。我们启用Linux eBPF“JIT”引擎, 它在验证后将eBPF代码编译为本机机器代码。已经研究了BPF JIT引擎的正确性并且可以验证[74]。
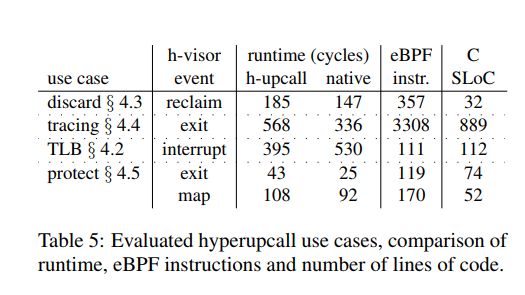
用例。我们评估了表5中列出的四个hyperupcall用例。每个用例演示了在不同的hypervisor事件中使用hyperupcalls,并使用不同复杂度的hyperupcalls。
4.1 Hyperupcall开销
我们通过将hyperupcall与本机代码的运行时间与相同函数进行比较来评估使用经过验证的代码来管理Hypervisor请求的开销(表5)。总的来说,我们发现验证代码相对于原生的绝对开销很小(<250个循环)。对于处理TLB击落到非活动核心的TLB用例,我们的hyperupcall运行速度比本机代码快,因为TLB刷新被推迟。验证hyperupcall的开销很小。对于最长的hyperupcall(跟踪),验证花了67ms。
4.2 TLB Shootdown
虽然通常可以有效地完成向VCPU的中断传送,但是如果目标VCPU没有运行则会有很大的损失。如果CPU过载,并且调度目标VCPU需要抢占另一个VCPU,则会发生这种情况。对于同步处理器间中断(IPI),发送方仅在接收方指示IPI已交付和已接通后才恢复执行,从而导致过高的开销。
在转换后备缓冲器(TLB)击落的情况下,IPI传递的开销最为显着,这是一种软件协议,OS用于保持虚拟到物理地址映射相关的TLB缓存。由于常见的CPU架构(例如,x86)不能使TLB在硬件中保持一致,因此修改映射的OS线程会将IPI发送到可能缓存映射的其他CPU,然后这些CPU会刷新其TLB。
【TLB(转换后备缓冲区)是从虚拟存储器地址到物理存储器地址的转换缓存。当处理器更改地址的虚拟到物理映射时,它需要告诉其他处理器使其缓存中的映射无效。
这个过程被称为“TLBshootdown】
我们使用hyperupcalls来处理这种情况,方法是注册一个hyperupcall,当中断传递给VCPU时,它会处理TLB击落。Hypervisor在确保其处于静止状态后,使用中断向量和目标VCPU提供超级调用。我们的hyperupcall检查此向量是否是“远程函数调用”向量以及函数指针是否等于OS TLB刷新函数。如果是这样,它运行此函数时只需要很少的修改:(1) 不使用本机指令刷新TLB,而是使用辅助函数执行TLB刷新,将其推迟到下一个VCPU重入; (2)即使禁用VCPU中断也会执行TLB刷新,因为实验上它可以提高性能。
不可否认,还有另一种解决方案:引入一个将TLB刷新委托给Hypervisor的超级调用[52]。虽然这种解决方案可以防止TLB刷新,但它需要不同的代码路径,这可能会引入隐藏的错误[43],使与OS代码的集成变得复杂或引入额外的开销[44]。此解决方案也仅限于TLB刷新,并且无法处理其他中断,例如,重新安排IPI。
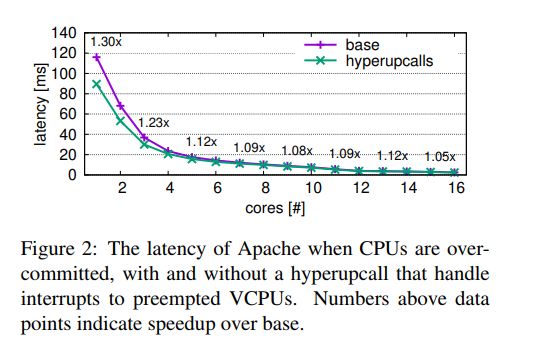
评估。我们使用默认的mpm_event模块在guest虚拟机中运行Apache Web服务器[23],该模块运行多线程工作程序来处理传入的请求。为了衡量性能,我们使用ApacheBench,Apache HTTP服务器基准测试工具,使用16个连接生成10k请求,并测量请求延迟。结果显示在图2中,显示hyperupcalls将延迟减少了1.3 x。即使物理CPU没有超额订阅,性能也会提高,这似乎令人惊讶。但是,由于VCPU在此基准测试中通常暂时处于空闲状态,因此它们也可以触发对Hypervisor的退出。
4.3丢弃可用内存
根据定义,可用内存不包含任何所需数据,可以丢弃。如果Hypervisor知道guest虚拟机中有哪些内存空闲,它可以在内存回收,快照,实时迁移或锁定步骤执行期间丢弃它[20]并避免I/O操作以保存和恢复其内容。然而,关于哪些存储器页面是空闲的信息由Guest持有,并且由于语义上的差异而不可用于Hypervisor。
多年来,已经提出了几种机制来通知Hypervisor哪些存储器页面使用半虚拟化是空闲的。然而,这些解决方案要么将Guest端与Hypervisor耦合[60];由于频繁的超级调用引起的开销[41]或仅限于实时迁移[73]。所有这些机制都受到固有的限制:没有耦合Guest机和Hypervisor,Guest机需要与Hypervisor通信哪些页面是空闲的。
相反,支持hyperupcalls的Hypervisor不需要通知有关空闲页面的信息。相反,guest虚拟机设置了一个hyperupcall,它根据页面元数据(Linux的结构页面)描述页面是否可丢弃,并且基于在Linux中的is_free_buddy_page函数。当Hypervisor执行可以从丢弃空闲Guest存储器页面(例如回收页面)中受益的操作时,Hypervisor调用该超级调用来检查该页面是否是可丢弃的。当页面已经被取消映射时,也会调用hyperupcall,以防止在不再空闲时丢弃它的竞赛。
检查是否可以丢弃页面必须通过全局超级调用来完成,因为必须在有限且短时间内提供答案。结果,guest虚拟机只能注册其部分内存以供hyperupcall使用,因为该内存从不被分页以确保及时执行hyperupcall。我们的Linux guest虚拟机注册了页面元数据的内存 约占Guest物理内存的1.6%。评价。为了评估“内存丢弃”hyperupcall的性能,我们测量其对因内存压力而被回收内存的guest虚拟机的影响。当内存不足时,Hypervisor可以执行“不合作的交换” - 直接回收Guest机内存并将其交换到磁盘。然而,这种方法通常会导致次优的回收决策。或者,Hypervisor可以使用memory ballooning,这是一种半虚拟机制,其中Guest模块被告知主机内存压力并导致Guest直接回收内存[71]。然后Guest可以做出知识渊博的回收决定并丢弃空闲页面。虽然内存膨胀通常表现良好,但是当内存需要突然回收时性能会受到影响[4,6]或当Guest盘设置在网络附加存储[68]上时,因此不在高内存压力下使用[21]。
为了评估内存膨胀,不合作的交换和使用hyperupcalls进行交换,我们运行了一个场景,其中需要突然回收内存和物理CPU,以便容纳新的guest虚拟机。在Guest,我们开始并退出“memhog”,使4GB可用于在Guest回收。接下来,我们让Guest忙运行与低内存占用CPU密集型任务 一 的sysbench的CPU性能测试,它计算使用的所有虚拟处理器[39]素数。
现在,在系统繁忙的情况下,我们通过增加内存和CPU过量使用来模拟回收资源以启动新guest虚拟机的需求。我们降低了guest虚拟机可用的物理CPU数量,并将其限制为仅1GB内存。我们根据为guest虚拟机分配的物理CPU数来衡量回收内存所需的时间(图3a)。这模拟了一个新的Guest开始。然后,我们停止增加内存压力,并使用4GB的SysBench文件读取基准测量运行具有大内存占用量的Guest应用程序的时间(图3b)。这模拟了guest虚拟机重用由Hypervisor回收的页面。
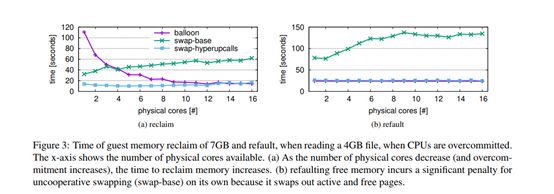
当物理CPU过量使用时,Ballooning会缓慢地回收内存(最多110秒),因为内存回收操作会在CPU时间与CPU密集型任务竞争。不合作的交换(交换基础)可以更快地回收(32秒),但由于它不知道内存页是否是空闲的,它会导致更高的Guest空闲页面的开销。相反,当使用hyperupcalls时,Hypervisor可以促进空闲页面的回收并丢弃它们,从而回收内存的速度比Ballooning快8倍,而内存只有10%的减速。
当然,CPU过量使用并不是Ballooning无响应或无法使用的唯一情况。当内存压力非常高时,Hypervisor会避免膨胀,而变成使用主机级交换[67]。 hyperupcalls可以与Ballooning协同运行:Hypervisor可以正常使用Ballooning,并在资源压力高或Ballooning没有响应时使用hyperupcalls。
4.4 Tracing
事件跟踪是调试正确性和性能问题的重要工具。但是,收集虚拟化工作负载的跟踪有些限制。在guest虚拟机内收集的跟踪不会显示Hypervisor事件,例如强制VM退出时,这会对其产生重大影响 性能。对于在Hypervisor中收集的跟踪信息,他们需要有关Guest操作系统符号的知识[15]。无法在云环境中收集此类跟踪。此外,每个跟踪仅收集部分事件,并不显示guest虚拟机和虚拟机监控程序事件如何交错。
为了解决这个问题,我们在hyperupcall中运行Linux内核跟踪工具ftrace [57]。 Ftrace非常适合在hyperupcall中运行。它简单,无锁,并且可以在多个上下文中启用并发跟踪:不可屏蔽中断(NMI),硬件和软件中断处理程序以及用户进程。因此,它很容易适应与Guest事件同时跟踪Hypervisor事件。使用ftrace hyperupcall,guest虚拟机可以在一个统一日志中跟踪Hypervisor和Guest事件,从而简化调试。由于跟踪所有事件仅使用Guest逻辑,因此新的OS版本可以更改跟踪逻辑,而无需更改Hypervisor。评价。跟踪是有效的,尽管超级调用复杂度(3308 eBPF指令),因为大多数代码处理不常见的事件,处理跟踪页面填满的情况。使用hyperupcalls跟踪比使用本机代码232个周期要慢,这仍然比Hypervisor和Guest端之间的上下文切换时间短得多。
.
跟踪是性能调试的有用工具,可以暴露各种开销[79]。例如,通过在VM-exit事件上注册ftrace,我们看到许多进程(包括短期进程)由于CPUID指令的执行而触发多个VM退出,这些指令枚举CPU功能并且必须由Hypervisor。我们发现大多数Linux应用程序使用的GNU C库使用CPUID来确定支持的CPU功能。通过扩展Linux虚拟动态共享对象(vDSO)以便应用程序查询支持的CPU功能而不触发退出,可以防止这种开销。
4.5内核自我保护
操作系统采用的一种常见安全加固机制是“自我保护”:操作系统代码和不可变数据写保护。但是,这种保护是使用页表完成的,允许恶意软件通过修改页表条目来规避它。为防止此类攻击,建议使用嵌套页表,因为这些表无法从guest虚拟机中访问[50]。
但是,嵌套只能提供有限数量的策略,例如,不能将允许访问受保护内存的Guest代码列入白名单。 Hyperupcalls更具表现力,允许Guest以灵活的方式指定内存保护。
我们使用hyperupcalls来提供Hypervisor级别的Guest内核自我保护,可以轻松修改它以适应复杂的策略。在我们的实现中,guest设置了一个标记受保护页面的位图,并在退出事件上注册hyperupcall,它检查退出原因,是否发生了内存访问以及guest虚拟机是否尝试根据位图写入受保护的内存。如果尝试访问受保护的内存,则会触发VM关闭。 guest虚拟机在“页面映射”事件上设置了另一个超级调用,该事件查询Guest页面帧所需的保护。此超级调用可防止虚拟机监控程序主动预先取消Guest机内存。
评价。这种超级调用代码很简单,但每次退出会产生43个周期的开销。可以说,只有已经经历过大量上下文切换的工作负载才会受到额外开销的影响。现代CPU可以防止这种频繁的切换。
5 结论
弥合语义差距是关键性能,并且Hypervisor可以为Guest提供高级服务。现在使用Hypercalls和upcalls来弥补差距,但它们有几个缺点:Hypercalls不能由Hypervisor启动,upcalls没有有限的运行时,并且都会导致上下文切换的惩罚。内省,避免上下文切换的替代方案可能是不可靠的,因为它依赖于观察而不是显式接口。 Hyperupcalls通过允许guest虚拟机将其逻辑暴露给Hypervisor来克服这些限制,通过使hyperupcall能够直接安全地执行guest虚拟机逻辑来避免上下文切换。
正文之后
老师上课点评的时候,认同了我所理解的第三方公证监视器的思想提取,真是amazing~~!!语义鸿沟问题是虚拟机的一个很经典的问题,他必须存在但是又对性能有极大的影响。那么为什么不像是内省一样在虚拟机里面放一个监视器呢?因为这样会破坏虚拟机的封装性。虚拟机必须要自我欺骗成我是一个完整的机器,而不是别的物理机的一个时隙,所以如果发现自己体内还存在一个监视器,会作何感想?!第三方的话,虚拟机完全可以考虑成是对外的通讯。