XGBoost 论文翻译+个人注释
最近研究机器学习理论,学习了一下陈天奇博士的论文,做了一点简单的翻译和批注,在这里记录一下。
本文将按照论文的顺序来介绍xgb,其中穿插我自己的理解和我对于论文原文的中文翻译,以及一些公式的截图。原文翻译将使用红色来标注,其余的皆为我自己理解的内容,涉及参数调整的我会加粗。
===================================================
论文题目是
XGBoost: A Scalable Tree Boosting System
从题目中就可以看出来,这篇文章重点讲的是一个system,而不是algorithm,本文的重点大篇幅地介绍了xgb整个系统是如何搭建,如何实现的,在模型算法的公式改进上只做了一点微小的工作。
摘要
树的提升是一种非常有效且被广泛使用的机器学习方法。 在本文中,我们描述了一个名为XGBoost的有延展性的端到端的树提升系统,数据科学家们广泛使用该系统来实现许多机器学习挑战的最新成果。我们提出了一种新颖的稀疏数据感知算法用于稀疏数据,一种带权值的分位数略图(weighted quantile sketch) 来近似实现树的学习。更重要的是,我们提供有关缓存访问模式,数据压缩和分片的见解,以构建有延展性的提升树系统。通过结合这些见解,XGBoost可用比现系统少得多的资源来处理数十亿规模的数据。
关键词:大规模机器学习
摘要这段没什么好说的,后面都会详细介绍,这段内容不多,我就翻译了一下。
第一章 绪论
机器学习和数据驱动的方法在许多领域变得非常重要。智能垃圾邮件分类器通过从大量的垃圾邮件数据和用户反馈中学习来保护我们的邮箱;广告系统学习将正确的广告与正确的背景相匹配;欺诈检测系统保护银行免受恶意攻击;异常事件检测系统帮助实验物理学家发现新的物理现象。有两个重要因素可以推动这些成功的应用:使用能捕获复杂数据依赖性的有效的(统计)模型,以及能从大型数据集里学习出模型的可扩展的学习系统。
在实际应用的机器学习方法里,GradientTree Boosting (GBDT)是一个在很多应用里都很出彩的技术。提升树方法在很多有标准分类基准的情况下表现很出色。LambdaMART这个提升树的变种,用来排序的,也表现出了不错的结果,它除了被用于单独的预测器,还在实际生产中被用于广告点击率预测。它是很多集成方法里的实际选择,此外还用于Netflix这样的比赛。
本文描述的可扩展的提升树机器学习系统已经开源了,它的影响力已经被许多机器学习和数据挖掘的比赛所广泛认可。拿机器学习大赛Kaggle举例:2015年发布的29个获胜方法里有17个用了XGBoost。在这些方案里,有8个仅用了XGBoost,另外的大多数用它结合了神经网络。对比来看,第二流行的方法,深度神经网络,只被用了11次。这个系统的成功性也被KDDCup2015所见证了,前十的队伍都用了XGBoost。此外,据胜出的队伍说,很少有别的集成学习方法效果能超过调好参的XGBoost。
这一段的描述属实,万能的xgb时代
这些结果说明我们的系统能在很广泛的问题里获得很好的结果。这些成功案例包括:网页文本分类、顾客行为预测、情感挖掘、广告点击率预测、恶意软件分类、物品分类、风险评估、大规模在线课程退学率预测。虽然这些问题依赖于特定领域的数据分析和特征工程,但选择XGBoost是这些人的共识,这体现出了我们的系统的影响力和重要性。
XGBoost成功背后的最重要因素是其在所有情况下的可扩展性。该系统在单台机器上的运行速度比现有流行解决方案快十倍以上,并可在分布式或内存有限的环境中扩展到数十亿个示例。XGBoost的可扩展性是由于几个重要的系统和算法优化。这些创新包括:一种新颖的树学习算法,用于处理稀疏数据;理论上合理的加权分位数略图程序能够在近似树学习中处理实例权重。并行和分布式计算使得学习速度更快,从而加快了模型的探索。更重要的是,XGBoost利用外核计算,使数据科学家能够在桌面上处理数百万个示例。最后,将这些技术结合起来,使用最少的集群资源扩展到更大的数据的端到端系统更为令人兴奋。本文主要贡献如下:
这四个方面就是论文的主要创新点了
•我们设计和构建高度可扩展的端到端提升树系统。
•我们提出了一个理论上合理的加权分位数略图。 这个东西就是推荐分割点的时候用,能不用遍历所有的点,只用部分点就行,近似地表示,省时间。
•我们引入了一种新颖的稀疏感知算法用于并行树学习。 令缺失值有默认方向。
•我们提出了一个有效的用于核外树形学习的缓存感知块结构。 用缓存加速寻找排序后被打乱的索引的列数据的过程。
虽然在并行树推广方面有一些已有的工作,但诸如核外计算,缓存感知和稀疏感知学习等方向尚未被探索。更重要的是,结合所有这些方面的端到端系统为实际使用情况提供了一种新颖的解决方案。这使得数据科学家和研究人员能够构建提升树算法的强大变种。除了这些主要的贡献之外,我们还提出了一个改进正则化学习的方法。
在本文的其余部分安排如下。我们将在第二章节首先回顾一下提升树,并介绍一个正则化的目标。然后,我们在第三部分介绍拆分查找方法,第四部分是系统设计,包括相关的实验结果,为我们提到的每个优化方法提供量化支持。相关工作在第五节讨论。详细的端到端评估在第六部分。最后,我们在第七部分总结这篇论文。
Introduction 也没啥好说的,我就简单翻译了一下,后面的就不大篇幅翻译了,只讲思想,因为有的细节我也扣不清楚。
第二章 简言提升树
这一章就是提升方法的公式了,以及正则项的公式。基本思想和GBDT是一样的,都是按照损失函数的负梯度方向提升,其实就是gbdt,只是进行了泰勒二次展开,加了一些正则项。xgb的损失函数如下所示
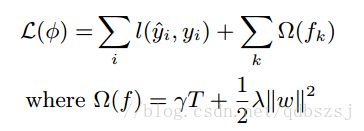
把经验误差二阶泰勒展开
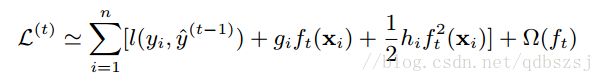
去掉常数项:
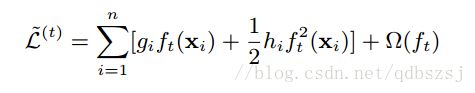
最后展开正则项,我们得到了

正则项里的T是叶子节点的个数,gamma是这一项的系数,lambda是所有叶子节点的权值的l2正则之和的系数。当正则项系数为0时,整体的目标就退化为了GBDT。陈天奇在他的slide里还提到这个诡异的目标函数了,他说:这个目标函数有一个很明显的特点,那就是只依赖于每个数据点的在目标函数上的一阶和二阶导数,有人可能会问,这个材料似乎比我们之前学过的决策树学习难懂。为什么要花这么多力气来做推导呢?因为这样做使得我们可以很清楚地理解整个目标是什么,并且一步一步推导出如何进行树的学习。这一个抽象的形式对于实现机器学习工具也是非常有帮助的。传统的GBDT可能大家可以理解如优化平法残差,但是这样一个形式包含可所有可以求导的目标函数。也就是说有了这个形式,我们写出来的代码可以用来求解包括回归,分类和排序的各种问题,正式的推导可以使得机器学习的工具更加一般。
啊为什么要泰勒展开?据说能使工具的学习更加一般?这里传统的GBDT用一阶导就已经令工具就有一般化了,这里又求了一个二阶导,好吧,我也不懂为什么要这样。这里并不明白为何要用二阶泰勒展开作为损失函数,anyway,如果有人能理解还希望指点一二。
第二章里还提到了shrinkage 和 column subsampling,就是相当于学习速率和对于列的采样骚操作。调低eta能减少个体的影响,给后续的模型更多学习空间。对于列的重采样,根据一些使用者反馈,列的subsampling比行的subsampling效果好,列的subsampling也加速了并行化的特征筛选。这里就跟RF差不多吧,不过论文没说具体怎么column subsampling,API里有个参数能控制subsampe的比例。
第三章 寻找分割点算法
这一章算是这篇文章的核心章节,也是xgb之所以能跑的这么快的原因之一(最重要的原因在第四章),我觉得比第二章的公式都要重要。
传统算法就是暴力地遍历所有可能的分割点,xgb也支持这种做法:

当数据量过大,传统算法就不好用了,因为要遍历每个分割点,甚至内存都放不下,所以,xgb提出了额外一种近似算法能加快运行时间:

这个算法根据特征的分布情况,然后做个proposal,然后这一列的分割点就从这几个proposed candidate points里选,能大大提高效率。这里有两种proposal的方式,一种是global的,一种是local的,global的是在建树之前就做proposal然后之后每次分割都要更新一下proposal,local的方法是在每次split之后更新proposal。通常发现local的方法需要更少的candidate,而global的方法在有足够的candidate的时候效果跟local差不多。我们的系统能充分支持exact greedy跑在单台机器或多台机器上,也支持这个proposal的近似算法,并且都能设定global还是local的proposal方式(这个算法的参数我没有在一般的API里看到,可能做超大型数据的时候才会用这个吧,因为前者虽然费时间但是更准确,通常我们跑的小数据用exact greedy就行)
这里算法在研究特征分布然后做proposal的时候,用到了加权分位数略图(weighted quantile sketch),原文说不加权的分位数略图有不少了,但是支持加权的以前没人做,我对这个东西不太了解,百度了一下相关的关键词:
构造略图(sketching)是指使用随机映射(Random projections)将数据流投射在一个小的存储空间内作为整个数据流的概要,这个小空间存储的概要数据称为略图,可用于近似回答特定的查询。不同的略图可用于对数据流的不同Lp范数的估算,进而这些Lp范数可用于回答其它类型的查询。如L0范数可用于估算数据流的不同值(distinct count);L1范数可用于计算分位数(quantile)和频繁项(frequent items);L2范数可用于估算自连接的长度等等。
另外,在分割的时候,这个系统还能感知稀疏值,我们给每个树的结点都加了一个默认方向,当一个值是缺失值时,我们就把他分类到默认方向,每个分支有两个选择,具体应该选哪个?这里提出一个算法,枚举向左和向右的情况,哪个gain大选哪个:

第四章 系统设计
这是本文的重中之重,也是最核心的部分,终于开始介绍整个系统了。这一章原文太多,我提炼出来的都是要点
这里XGB将所有的列数据都预先排了序。
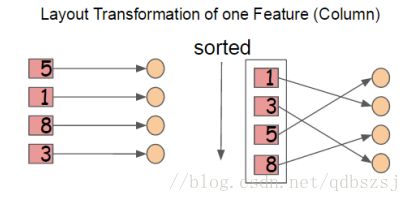
以压缩形式分别存到block里,不同的block可以分布式存储,甚至存到硬盘里。在特征选择的时候,可以并行的处理这些列数据,XGB就是在这实现的并行化,用多线程来实现加速。同时这里陈博士还用cache加了一个底层优化:

当数据排序后,索引值是乱序的,可能指向了不同的内存地址,找的时候数据是不连续的,这里加了个缓存,让以后找的时候能找到小批量的连续地址,以实现加速!这里是在每个线程里申请了一个internal buffer来实现的!这个优化在小数据下看不出来,数据越多越明显。
第五章 相关工作
这一章把前面的东西又总结了一遍,这里不写了。
第六章 端到端的评估
这一章都是一些实验数据,就是各种图表来证明xgb比别的优秀,这里也没必要展开讲了,我就讲几个我关注的点。
实验数据里提到column subsampling表现不太稳定,有时候sub比不sub要好,有时候sub要好,什么时候该用subsampling呢?当没有重要的特征要选,每个特征值的重要性都很平均的时候,对列的subsampling效果就比较差了。
这里他们还做了分布式的实验,在Amazon的云服务平台上用了32台m3.2xlarge搭建了一个YARN集群,数据没有放在HDFS里,放在了Amazon的S3 storage上(这是为了公平起见,不让访问本地数据),每台机器的配置是8核30G内存,160G的ssd,然后跑出来的实验结果,xgb虐了spark MLLib。
然后我手贱去查了一下这个instance多少钱,额400$/month,一下子开32台,一个月就是一万多美刀啊。