gensim实现python对word2vec的训练和计算
词向量(word2vec)原始的代码是C写的,python也有对应的版本,被集成在一个非常牛逼的框架gensim中。
我在自己的开源语义网络项目graph-mind(其实是我自己写的小玩具)中使用了这些功能,大家可以直接用我在上面做的进一步的封装傻瓜式地完成一些操作,下面分享调用方法和一些code上的心得。
1.一些类成员变量:
def __init__(self, modelPath, _size=100, _window=5, _minCount=1, _workers=multiprocessing.cpu_count()):
self.modelPath = modelPath
self._size = _size
self._window = _window
self._minCount = _minCount
self._workers = _workers2.初始化并首次训练word2vec模型
完成这个功能的核心函数是initTrainWord2VecModel,传入两个参数:corpusFilePath和safe_model,分别代表训练语料的路径和是否选择“安全模式”进行初次训练。关于这个“安全模式”后面会讲,先看代码:
def initTrainWord2VecModel(self, corpusFilePath, safe_model=False):
'''
init and train a new w2v model
(corpusFilePath can be a path of corpus file or directory or a file directly, in some time it can be sentences directly
about soft_model:
if safe_model is true, the process of training uses update way to refresh model,
and this can keep the usage of os's memory safe but slowly.
and if safe_model is false, the process of training uses the way that load all
corpus lines into a sentences list and train them one time.)
'''
extraSegOpt().reLoadEncoding()
fileType = localFileOptUnit.checkFileState(corpusFilePath)
if fileType == u'error':
warnings.warn('load file error!')
return None
else:
model = None
if fileType == u'opened':
print('training model from singleFile!')
model = Word2Vec(LineSentence(corpusFilePath), size=self._size, window=self._window, min_count=self._minCount, workers=self._workers)
elif fileType == u'file':
corpusFile = open(corpusFilePath, u'r')
print('training model from singleFile!')
model = Word2Vec(LineSentence(corpusFile), size=self._size, window=self._window, min_count=self._minCount, workers=self._workers)
elif fileType == u'directory':
corpusFiles = localFileOptUnit.listAllFileInDirectory(corpusFilePath)
print('training model from listFiles of directory!')
if safe_model == True:
model = Word2Vec(LineSentence(corpusFiles[0]), size=self._size, window=self._window, min_count=self._minCount, workers=self._workers)
for file in corpusFiles[1:len(corpusFiles)]:
model = self.updateW2VModelUnit(model, file)
else:
sentences = self.loadSetencesFromFiles(corpusFiles)
model = Word2Vec(sentences, size=self._size, window=self._window, min_count=self._minCount, workers=self._workers)
elif fileType == u'other':
# TODO add sentences list directly
pass
model.save(self.modelPath)
model.init_sims()
print('producing word2vec model ... ok!')
return model首先是一些杂七杂八的,判断一下输入文件路径下访问结果的类型,根据不同的类型做出不同的文件处理反应,这个大家应该能看懂,以corpusFilePath为一个已经打开的file对象为例,创建word2vec model的代码为:
model = Word2Vec(LineSentence(corpusFilePath), size=self._size, window=self._window, min_count=self._minCount, workers=self._workers)其实就是这么简单,但是为了代码健壮一些,就变成了上面那么长。问题是在面对一个路径下的许多训练文档且数目巨大的时候,一次性载入内存可能不太靠谱了(没有细研究gensim在Word2Vec构造方法中有没有考虑这个问题,只是一种习惯性的警惕),于是我设定了一个参数safe_model用于判断初始训练是否开启“安全模式”,所谓安全模式,就是最初只载入一篇语料的内容,后面的初始训练文档通过增量式学习的方式,更新到原先的model中。
上面的代码里,corpusFilePath可以传入一个已经打开的file对象,或是一个单个文件的地址,或一个文件夹的路径,通过函数checkFileState已经做了类型的判断。另外一个函数是updateW2VModelUnit,用于增量式训练更新w2v的model,下面会具体介绍。loadSetencesFromFiles函数用于载入一个文件夹中全部语料的所有句子,这个在源代码里有,很简单,哥就不多说了。
3.增量式训练更新word2vec模型
增量式训练w2v模型,上面提到了一个这么做的原因:避免把全部的训练语料一次性载入到内存中。另一个原因是为了应对语料随时增加的情况。gensim当然给出了这样的solution,调用如下:
def updateW2VModelUnit(self, model, corpusSingleFilePath):
'''
(only can be a singleFile)
'''
fileType = localFileOptUnit.checkFileState(corpusSingleFilePath)
if fileType == u'directory':
warnings.warn('can not deal a directory!')
return model
if fileType == u'opened':
trainedWordCount = model.train(LineSentence(corpusSingleFilePath))
print('update model, update words num is: ' + trainedWordCount)
elif fileType == u'file':
corpusSingleFile = open(corpusSingleFilePath, u'r')
trainedWordCount = model.train(LineSentence(corpusSingleFile))
print('update model, update words num is: ' + trainedWordCount)
else:
# TODO add sentences list directly (same as last function)
pass
return model4.各种基础查询
当你确定model已经训练完成,不会再更新的时候,可以对model进行锁定,并且据说是预载了相似度矩阵能够提高后面的查询速度,但是你的model从此以后就read only了。
def finishTrainModel(self, modelFilePath=None):
'''
warning: after this, the model is read-only (can't be update)
'''
if modelFilePath == None:
modelFilePath = self.modelPath
model = self.loadModelfromFile(modelFilePath)
model.init_sims(replace=True)然后是一些word2vec模型的查询方法:
def getWordVec(self, model, wordStr):
'''
get the word's vector as arrayList type from w2v model
'''
return model[wordStr]def queryMostSimilarWordVec(self, model, wordStr, topN=20):
'''
MSimilar words basic query function
return 2-dim List [0] is word [1] is double-prob
'''
similarPairList = model.most_similar(wordStr.decode('utf-8'), topn=topN)
return similarPairListdef culSimBtwWordVecs(self, model, wordStr1, wordStr2):
'''
two words similar basic query function
return double-prob
'''
similarValue = model.similarity(wordStr1.decode('utf-8'), wordStr2.decode('utf-8'))
return similarValue5.Word2Vec词向量的计算
研究过w2v理论的童鞋肯定知道词向量是可以做加减计算的,基于这个性质,gensim给出了相应的方法,调用如下:
def queryMSimilarVecswithPosNeg(self, model, posWordStrList, negWordStrList, topN=20):
'''
pos-neg MSimilar words basic query function
return 2-dim List [0] is word [1] is double-prob
'''
posWordList = []
negWordList = []
for wordStr in posWordStrList:
posWordList.append(wordStr.decode('utf-8'))
for wordStr in negWordStrList:
negWordList.append(wordStr.decode('utf-8'))
pnSimilarPairList = model.most_similar(positive=posWordList, negative=negWordList, topn=topN)
return pnSimilarPairList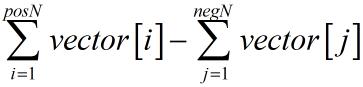
下面一个操作是我自创的,假设我想用上面词向量topN“词-关联度”的形式展现两个词或两组词之间的关联,我是这么做的:
def copeMSimilarVecsbtwWordLists(self, model, wordStrList1, wordStrList2, topN_rev=20, topN=20):
'''
range word vec res for two wordList from source to target
use wordVector to express the relationship between src-wordList and tag-wordList
first, use the tag-wordList as neg-wordList to get the rev-wordList,
then use the scr-wordList and the rev-wordList as the new src-tag-wordList
topN_rev is topN of rev-wordList and topN is the final topN of relationship vec
'''
srcWordList = []
tagWordList = []
srcWordList.extend(wordStr.decode('utf-8') for wordStr in wordStrList1)
tagWordList.extend(wordStr.decode('utf-8') for wordStr in wordStrList2)
revSimilarPairList = self.queryMSimilarVecswithPosNeg(model, [], tagWordList, topN_rev)
revWordList = []
revWordList.extend(pair[0].decode('utf-8') for pair in revSimilarPairList)
stSimilarPairList = self.queryMSimilarVecswithPosNeg(model, srcWordList, revWordList, topN)
return stSimilarPairList更多的细节可以查看我的开源项目graph-mind源代码,不过肯定会有问题,希望大家能多和我交流,直接回复最好,微信:superhy199148,email:[email protected]。
如果有更深入的成果,我会及时Blog。