腾讯手Q webview技术owner厉心刚:JavaScript引擎分析
声明:本文来自腾讯增值产品部官方公众号小时光茶社,为CSDN原创投稿,未经许可,禁止任何形式的转载。
作者:厉心刚,SNG 增值产品部终端开发,高级工程师;参与多个项目开发(QQ情侣,手Q,阅读,电竞等项目),有丰富的终端开发及性能优化经验;担任过手Q webview技术owner,目前负责直播推流SDK 技术owner。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件[email protected],另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qshuguang2008申请入群,备注姓名+公司+职位。
一、JavaScript简介
JavaScript是一种动态类型的脚本语言;在1995年时,由Netscape公司的Brendan Eich,在网景导航者浏览器上首次设计实现而成。因为Netscape与Sun合作,Netscape管理层希望它外观看起来像Java,因此取名为JavaScript。
JavaScript脚本语言具有以下特点:
(1) 脚本语言。JavaScript是一种解释型的脚本语言,是在程序的运行过程中逐行进行解释执行,不需要预编译。而Java、C++等语言需要先编译后执行;
(2) 动态性。JavaScript能够动态修改对象的属性,没有办法在编译的时候知道变量的类型,只有在运行的时候才能确定。而Java、C++等都是静态类型语言,他们在编译的时候就能够知道每个变量的类型;
(3) 跨平台性。JavaScript脚本语言不依赖于操作系统,仅需要浏览器的支持。可以在多种平台下运行(如Windows、Linux、Mac、Android、IOS等)。
二、JavaScript与Java语言区别
从上面介绍的JavaScript语言特点会发现JavaScript的效率会比Java、C++低很多;看以下这个实例:

当JavaScript引擎分析到该段代码时,根本不知道a和b是什么类型,唯一的办法就是运行的时候根据实际传过来的对象再来计算,这显然会导致严重的性能问题。

当编译上面Java代码的时候,根据右边类型Class1的定义,获取对象a的属性x的时候,其实就是对象a的地址,大小是一个整形。同时获取对象b的属性y的时候,其实就是对象b的地址加上4个字节,这些都是在生成本地代码时确定的,无需在运行本地代码的时候再决定他们的地址和类型是什么,这显然能够节省时间。
再看一下两者分别是怎样存储对象a和b的:
对于传统的JavaScript解释器来说,因为不知道a和b的具体类型,就用属性名-属性值对来保存,之后访问对象的属性值时就需要通过属性名匹配来获取对应的值;对象b也是同样的结果来保存相同的属性。随着对象的增多,这显然带来了巨大的空间浪费。

而上面的Java代码在编译时就确定了类Class1的成员类型,访问x就是对象a的地址,y就是a的地址加上4个字节;所以字符“x”和“y”运行时都不再需要,因为不再需要额外查找这些属性地址的工作。

从上面实例可以看到JavaScript和Java语言的区别包括以下几个部分:
编译确定位置: Java有编译和执行两个阶段,位置的偏移信息都是在编译器编译的时候决定的,当Java生成本地代码之后,对象的属性和偏移信息都计算完成。而JavaScript没有类型,只有在对象执行创建的时候才确定这些信息,而且JavaScript语言能够在执行时修改对象的属性。
偏移信息共享: Java有类型定义,所有的对象都是共享偏移信息的,访问他们只需要按照编译时确定的偏移量即可。JavaScript则不同,每个对象都有自我描述,属性和位置偏移信息都包含在自身的结构中。
偏移信息查找: Java查找偏移地址很简单,都是在编译代码时,对使用到的类型成员变量直接设置偏移量。而JavaScript则需要通过属性名匹配才能查找到对应的值。
Java语言有明显的两个阶段:编译和运行,如下图所示:

Java代码经过编译器编译之后生成的是字节码,字节码是跨平台的一种中间表示,不同于本地代码。该字节码与平台无关,能够在不同的操作系统上运行。在运行字节码阶段,Java的运行环境是Java虚拟机加载字节码。Java虚拟机一般都引入JIT技术来将字节码转变成本地代码来提高执行效率。第一阶段对时间要求不严格,第二阶段对每个步骤所花费的时间非常敏感,时间越短越好。
JavaScript语言的编译和执行都是在运行阶段执行的,如下图所示:

因为都是在代码运行过程中来处理这些步骤,所以每个阶段的时间越短越好,而且每引入一个阶段都是额外的时间开销,所以一个JavaScript引擎主要包含以下几个部分:
- 编译器:主要工作是将源代码编译成抽象语法树;
- 解释器:主要是接受字节码,解释执行这个字节码;
- JIT工具:将字节码或抽象语法树转换成本地代码;
- 垃圾回收期和分析工具(Profiler):负责垃圾回收和收集引擎中的信息,帮助改善引擎的性能。
三、V8引擎介绍
V8是一个JavaScript引擎实现的开源项目,最开始由一些语言学家设计出来,后被Google收购,成为了JavaScript引擎和众多相关技术的引领者。V8支持众多的操作系统,包括Windows、Linux、Android、Mac OS X等。同时它也能够支持众多的硬件架构,如IA32、X64、ARM、MIPS等,将主流软硬件平台一网打尽。由于它是一个开源项目,开发者可以自由使用它的强大能力,目前炙手可热的NodeJs项目就是基于V8项目研发的。
1. 调用V8编程接口的例子和对应的内存管理方式
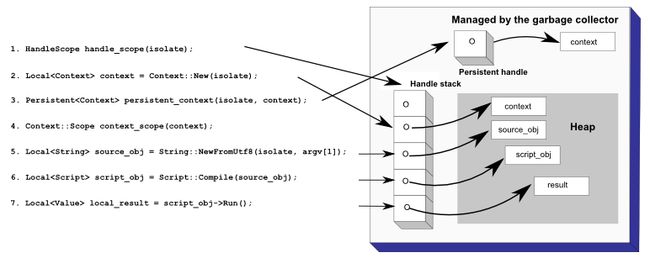
第一条语句:表示建立一个域,用于包含一组Handle对象,便于管理和释放它们;
第二条语句:根据Isolate对象来获取一个Context对象,使用Handle来管理。Handle对象本身存放在栈上,而实际的Context对象保存在堆中;
第三条语句:根据两个对象Isolate和Context来创建一个函数间使用的对象,使用Persistent类来管理;
第四条语句:表示为Context对象创建一个基于栈的域,下面的执行步骤都是在该域中对应的上下文中来进行的;
第五条语句:读入一段JavaScript代码;
第六条语句:将代码字符串编译成V8的内部表示,并保存成一个Script对象;
第七条语句:执行编译后的内部表示,获得生成的结果。
2. V8的编译
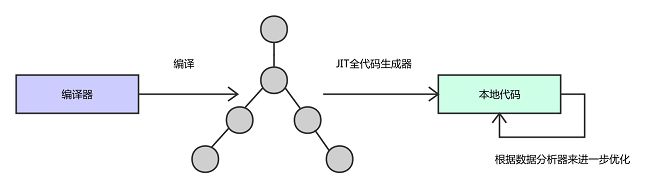
首先通过编译器将源代码编译成抽象语法树:

不同于JavaScriptCore引擎,V8引擎并不将抽象语法树转变成字节码,而是通过JIT编译器的全代码生成器从抽象语法树直接生成本地代码。

其过程中的主要类图如下:
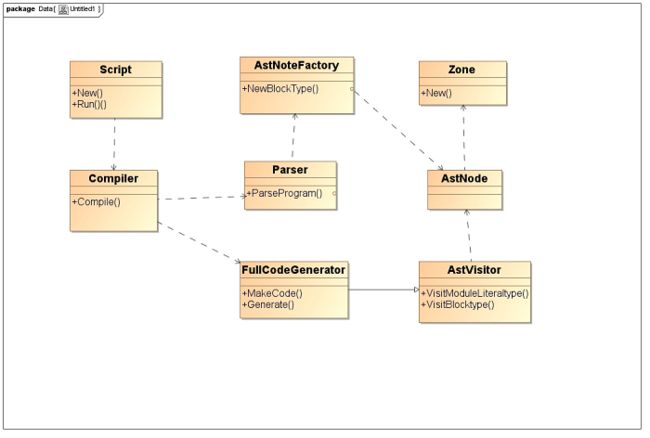
Script:表示的是JavaScript代码,既包含源代码,又包含编译之后生成的本地代码,所以它既是编译入口,又是运行入口;
Compiter:编译器类,辅助Script类来编译生成代码,它主要起一个协调者的作用,会调用解析器(Parse)来生成抽象语法树和全代码生成器,来为抽象语法树生成本地代码;
Parse:将源代码解析并构建成抽象语法树,使用AstNodeFactory类来创建他们,并使用Zone类来分配内存;
AstNode:抽象语法树节点类,是其他所有节点的基类;
AstVisitor:抽象语法树的访问者类,主要用来遍历抽象语法树;
FullCodeGenerator:AstVisitor类的子类,通过遍历抽象语法树来为JavaScript生成本地可执行的代码。
3. V8运行
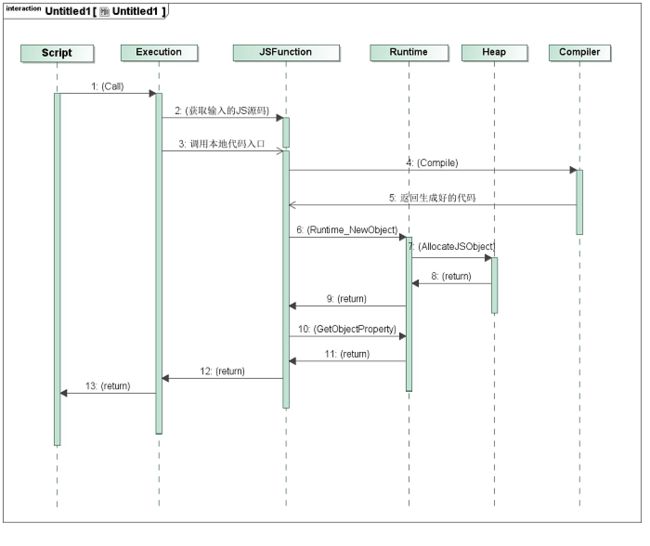
V8运行阶段的主要类图如下:

Script:前面介绍过,包含编译之后生成的本地代码,运行代码的入口;
Execution:运行代码的辅助类,包含一些重要的函数“call”,它辅助进入和执行Script中的本地代码;
JSFunction:需要执行的JavaScript函数表示类;
Runtime:运行本地代码的辅助类,主要提供运行时各种辅助函数;
Heap:运行本地代码需要使用的内存堆;
MarkCompactCollector:垃圾回收机制的主要实现类,用来标记,清除和整理等基本的垃圾回收过程;
SweeperThread:负责垃圾回收的线程。
V8中代码的执行过程如下图:
四、V8引擎所做优化
1. 优化回滚
Crankshaft编译器主要针对热点函数进行优化,它是基于JS源码分析的,而不是本地代码。为了性能考虑Crankshaft编译器会进行一些乐观的预测,认为这些代码比较稳定,变量类型不会发生变化,所以能够生成高效的本地代码。然而进行优化之后,V8发现并不是最优的,会执行优化回滚操作。
2. 隐藏类
将对象划分成不同的组,相同的组内对象拥有相同的属性名和属性值,组内的所有对象贡献该信息:
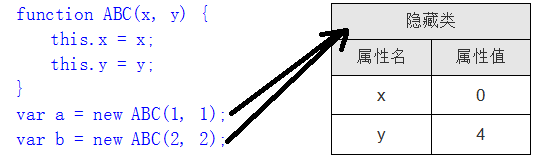
实例中对象a和b包含相同的属性名,V8就会将其归为同一个组,也就是隐藏类。这些属性在隐藏类中有相同的偏移值,这样,对象a和b可以共享这个类型信息,当访问这些对象属性的时候,根据隐藏类的偏移值就可以知道它们的位置并进行访问。
3. 内存管理
V8使用堆来管理JavaScript使用的数据,以及生成的代码、哈希表等;为了更方便地实现垃圾回收,同很多虚拟机一样,V8将堆分成三个部分,第一个是年轻分代,第二个是年老分代,第三个是大对象保留的空间;如下图:

4. 快照(Snapshot)
V8引擎开始启动的时候,需要加载很多内置的全局对象,同时也要建立内置的函数,比如Array、String、Math等。为了让引擎更加整洁,加载对象与建立函数等任务都是使用JS文件来实现的,V8引擎负责在编译和执行输入的JavaScript代码之前,先加载他们。
快照机制就是将一些内置的对象和函数加载之后的内存保存并序列化。序列化之后的结果很容易被反序列化,经过快照机制的启动时间,可以缩短启动时间。快照机制也能够将开发者认为需要的JS文件序列化,减少以后处理的时间。
5. 绑定和扩展
V8提供两种机制来扩展引擎的能力,第一是Extension机制,就是通过V8提供的基类Extension来达到扩展JavaScript能力的目的。第二是绑定,使用IDL文件或者接口文件来生成绑定文件,然后将这些文件同V8引擎代码一起编译。
五、实践——写JavaScript需要注意地方
1. 不要破坏隐藏类

建议:在构造函数中初始化所有对象成员,不要在以后更改类型;以相同的顺序初始化对象成员。
2. 数据表示
在V8中,数据的表示分成两个部分,第一个部分是数据的实际内容,它们是变长的;第二部分是数据的句柄,句柄的大小是固定的,句柄中包含指向数据的指针。为什么要这样设计呢?主要是因为V8需要进行垃圾回收,并需要移动这些数据内容,如果直接使用指针的话就会出问题或者需要比较大的开销,使用句柄的话就不存在这些问题,只需要将句柄中的指针修改即可。
具体的定义如下:

一个Handler的大小是4字节(32位机器),整数直接从value_中获取值,而无需从堆中分配,然后分配一个指针指向它,这可以减少内存的使用并增加数据的访问速度。
所以,对于数值来说,只要能够使用整数的,尽量不要使用浮点数。
3. 数组初始化

建议:初始化使用数组常量小型固定大小的数组;
不要储存在数字数组非数字值(对象);
不要删除数组中的元素,尤其是数字数组;
不要装入未初始化或删除元素。
4. 内存
对引用不再使用的对象的变量设置为空(a = null),引入delete关键字,删除无用对象。
5. 优化回滚
不要书写出触发优化回滚的代码,否则会大幅降低代码的性能。执行多次之后,不要出现修改对象类型的语句。
编辑推荐:架构技术实践系列文章(部分):
- 厉心刚:JavaScript引擎分析
- 蓝邦珏:来看看机智的前端童鞋怎么防盗
- 陈志兴:让页面滑动流畅得飞起的新特性:Passive Event Listeners
- 唐聪:大规模排行榜系统实践及挑战
- 左明:半小时深刻理解React
- 王照辉:魅族自动化测试架构之路
- 翁宁龙:美团数据库运维自动化系统构建之路
- 何轼:美团外卖订单中心的演进
- 申政:唯品会多线程Redis设计与实现
- 阿刘:千万级用户的Android客户端是如何养成的
- 卜赫:大道至简——React Native在直播应用中的实践
- 陈爱珍:从运维的角度看微服务和容器
- 孙其瑞:VR应用在直播领域上的实践与探索
- 刘丁:bilibili高并发实时弹幕系统的实战之路
- 秦鹏:从应用到平台,云服务架构的演进过程
- 郭炜:从0到N建立高性价比的大数据平台
- 李智慧:宅米网技术变迁——初创互联网公司的技术发展之路
- 陶文质:分布式系统设计的求生之路
- 魏晓军:React Native实践之携程Moles框架
- 学霸君姜波:耳目一新的在线答疑服务背后的核心技术
- 爱乐奇麦凯臻:在线教育的内容研发和技术的迭代创新
- 长虹李玮:老牌消费电子企业如何拥抱Docker
- 徐汉彬:日请求过亿的Web系统PHP7升级实践
- 窦威:AcFun的视频架构演化实践
- 傅鸿城:QQ亿级日活跃业务后台核心技术揭秘
- 宁峰峰:尖峰日96万订单,59校园狂欢节技术架构剖析
- 梁阳鹤:每秒处理10万订单乐视集团支付架构
- 沈辉煌:亿级日PV的魅族云同步的核心协议与架构实践
- 李任:携程Docker最佳实践
- 王海军:游戏研发与运营环境Docker化
- 史海峰:当当网高可用架构之道
- 黄哲铿:应对电商大促峰值的九个方法
- 1号店交易系统架构如何向「高并发高可用」演进
- 京东闫国旗:从C10K到C10M高性能网络的探索与实践
- 李林锋:服务化架构的演进与实践
- 1号店架构师王富平:一号店用户画像系统实践
- 唯品会官华:实现电商平台从业务到架构的治理体系
- 沈剑:58同城数据库架构最佳实践
- 荔枝FM架构师刘耀华:异地多活IDC机房架构
- UPYUN的云CDN技术架构演进之路
- 初页CTO丁乐:分布式以后还能敏捷吗?
- 陈科:河狸家运维系统监控系统的实现方案
- 途牛谭俊青:多数据中心状态同步&两地三中心的理论
- 云运维的启示与架构设计
- 魅族多机房部署方案
- 艺龙十万级服务器监控系统开发的架构和心得
- 京东商品详情页应对“双11”大流量的技术实践
- 架构师于小波:魅族实时消息推送架构
