linux整理-9-Linux用户和组整理
Linux用户和组整理
目录:
1、用户和组的概念
Linux用户类型
Linux用户组类型
2、用户操作
3、组操作
4、为用户配置sudoer权限
5、切换用户
1、用户和组的概念
在最开始介绍Linux系统的时候有介绍过说Linux是一个多任务多用户的操作系统,当我们在使用ls -l命令的时候我们看到如下信息:
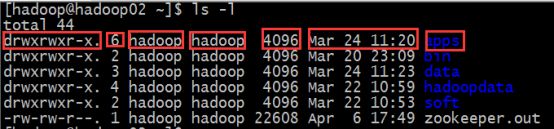
上面七个红框的信息分别是:
| 拆分字段 | 含义 |
|---|---|
| apps: | 表示文件或者目录,具体的文件类型是由该行最前面的那个符号表示 |
| drwxrwxr-x: | 该文件的类型和权限信息 |
| 6: | 链接数,如果是文件则是1, 如果是文件夹则表示该文件夹下的子文件夹个数 |
| 第一个hadoop: | 文件或者目录的所属者 |
| 第二个hadoop: | 所属用户组 |
| 4096: | 文件或者目录的大小,是目录的话一般都是4096 |
| Mar 24 11:20: | 文件的最后编辑时间 |
通过以上信息得知,每个文件都设计到用户和组的权限问题
在Linux中,用户是能够获取系统资源的权限的集合,组是权限的容器
Linux用户类型
| 用户类型 | 描述 |
|---|---|
| 管理员root | 具有使用系统所有权限的用户,其UID 为0 |
| 系统用户 | 保障系统运行的用户,一般不提供密码登录系统,其UID为1-499 |
| 普通用户 | 即一般用户,其使用系统的权限受限,其UID为500-60000之间. |
与Linux用户信息相关的文件有两个:分别是/etc/passwd和 /etc/shadow
查看文件/etc/passwd文件的内容,选取第一行:
root:x:0:0:root:/root:/bin/bash
| 拆分字段 | 含义 |
|---|---|
| root: | 用户名 |
| x: | 密码占位符,密码保存在shadow文件内 |
| 0: | 用户id,UID |
| 0: | 组id,GID |
| root: | 注释信息 |
| /root: | 用户家目录 |
| /bin/bash: | 用户默认使用shell |
登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
Linux用户组类型
| 用户组类型 | 描述 |
|---|---|
| 系统组 | 一般加入一些系统用户 |
| 普通用户组 | 可以加入多个用户 |
| 私有组/基本组 | 当创建用户时,如果没有为其指明所属组,则就为其定义一个私有的用户组,起名称与用户名同名,当把其他用户加入到该组中,则其就变成了普通组 |
与Linux用户组信息相关的文件有两个:分别是/etc/group和 /etc/gshadow
查看文件/etc/group文件内容,选取一个普通组行:
hadoop: x:500:
| 拆分字段 | 描述 |
|---|---|
| hadoop: | 组名 |
| x: | 组密码占位符 |
| 500: | 组id |
2、用户操作
Linux中的用户管理主要涉及到用户账号的添加、删除和修改。所有操作都影响/etc/passwd中的文件内容
1、添加用户
useradd spark
usermod -G bigdata spark ## 设置组
usermod -c “mylove spark” spark ## 添加备注信息
一步完成:useradd -G bigdata -c “mylove” spark
2、设置密码
passwd spark
根据提示设置密码即可
3、修改用户
修改spark登录名:usermod -l storm spark
将spark添加到bigdata和root组:usermod -G root,bigdata spark
查看spark的组信息:groups spark
4、删除用户
userdel -r spark
加一个-r就表示把用户及用户的主目录都删除
3、组操作
前面我们知道,组是权限的集合。在linux系统中,每个用户都有一个用户组,没有指定时都默认为私有组,私有组名同用户名一致,建立用户组的好处是系统能对一个用户组中的所有用户的操作权限进行集中管理。组管理涉及组的添加、删除和修改。组的增加、删除和修改实际上就对/etc/group文件的更新
1、添加一个叫bigdata的组
groupadd bigdata
2、查看系统当前有那些组
cat /etc/group
3、将hadoop用户添加到bigdata组中
usermod -G bigdata spark
或者
gpasswd -a spark bigdata
这两个命令的区分记忆技巧:
命令是什么,就证明对什么做操作,所以最后的参数就是命令的操作对象,中间的可选项表示要干嘛
4、将spark用户从bigdata组删除
gpasswd -d spark bigdata
5、将bigdata组名修改为bigspark
groupmod -n bigspark bigdata
6、删除组
groupdel bigdata
4、为用户配置sudoer权限
普通情况下,使用普通用户进行一些简单的操作就OK,但是普通用户和root用户的区别就在于root用户能对系统做任何事,但是普通用户就不行。处处受限。那么假如在某些情况下,普通用户想拥有更大的权限做更多的事情,虽然有权限限制,但也不是不可以。部分操作还是可以赋予更高的权限让普通用户做一次。这就需要给普通用户配置root权限了。意思就是让普通用户使用root权限去做一些操作,这当然是需要配置的。
用root编辑 vi /etc/sudoers
在文件的如下位置,为hadoop添加一行即可
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
spark ALL=(ALL) ALL
然后,hadoop用户和spark用户就可以用sudo来执行系统级别的指令
[hadoop@hadoop01 ~]$ sudo useradd huangxiaoming
5、切换用户
在linux的系统使用过程当中,免不了会有多个用户来回切换使用。所以在此提供切换用户的使用操作:
切换用户使用的命令是 su(switch user)
从普通用户切换到root用户:
[hadoop@hadoop01 root]$ su root
##或者
[hadoop@hadoop01 root]$ su
##然后根据提示输入密码即可
从root用户切换到普通用户:
[hadoop@hadoop01 root]$ su hadoop
##不用输入密码
退出登录:
[hadoop@hadoop01 root]$ exit