目标检测--Fast RCNN详解-多细节
Girshick, Ross. “Fast r-cnn.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
继2014年的RCNN之后,Ross Girshick在15年推出Fast RCNN,构思精巧,流程更为紧凑,大幅提升了目标检测的速度。在Github上提供了源码。
同样使用最大规模的网络,Fast RCNN和RCNN相比,训练时间从84小时减少为9.5小时,测试时间从47秒减少为0.32秒。在PASCAL VOC 2007上的准确率相差无几,约在66%-67%之间.
1.思想
1.1基础:RCNN
简单来说,RCNN使用以下四步实现目标检测:
a. 在图像中确定约1000-2000个候选框
b. 对于每个候选框内图像块,使用深度网络提取特征
c. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
d. 对于属于某一特征的候选框,用回归器进一步调整其位置
更多细节可以参看这篇博客。
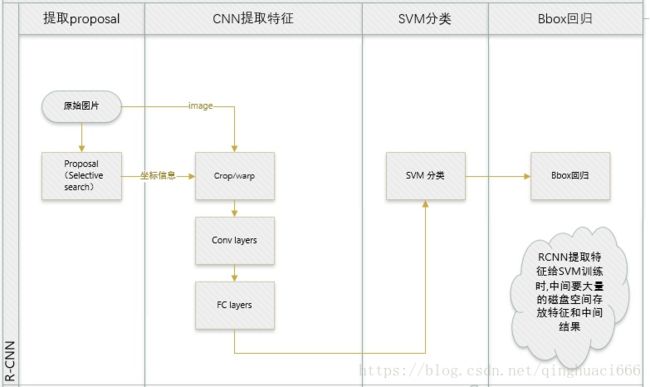
RCNN中存在的问题:
-
R-CNN网络训练、测试速度都很慢:R-CNN网络中,一张图经由selective search算法提取约2k个建议框【这2k个建议框大量重叠】,而所有建议框变形后都要输入AlexNet CNN网络提取特征【即约2k次特征提取】,会出现上述重叠区域多次重复提取特征,提取特征操作冗余;
-
R-CNN网络训练、测试繁琐:R-CNN网络训练过程分为ILSVRC 2012样本下有监督预训练、PASCAL VOC 2007该特定样本下的微调、20类即20个SVM分类器训练、20类即20个Bounding-box 回归器训练,该训练流程繁琐复杂;同理测试过程也包括提取建议框、提取CNN特征、SVM分类和Bounding-box 回归等步骤,过于繁琐;
-
R-CNN网络训练需要大量存储空间:20类即20个SVM分类器和20类即20个Bounding-box 回归器在训练过程中需要大量特征作为训练样本,这部分从CNN提取的特征会占用大量存储空间;
-
R-CNN网络需要对建议框进行形变操作后【形变为227×227 size】再输入CNN网络提取特征,其实像AlexNet CNN等网络在提取特征过程中对图像的大小并无要求,只是在提取完特征进行全连接操作的时候才需要固定特征尺寸【R-CNN中将输入图像形变为227×227可正好满足AlexNet CNN网络最后的特征尺寸要求】,然后才使用SVM分类器分类,R-CNN需要进行形变操作的问题在Fast R-CNN已经不存在,具体见下。
1.2改进:Fast RCNN
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
本文将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
Fast-RCNN的优点概述:
1. 比R-CNN、SPP-net有更高的检测质量(mAP);
2. 把多个任务的损失函数写到一起,实现单级的训练过程;
3. 在训练时可更新所有的层;
4. 不需要在磁盘中存储特征。
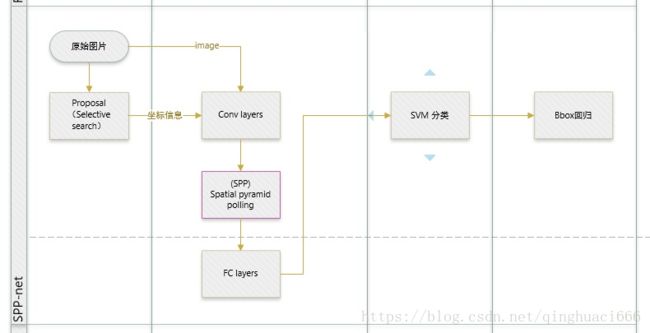
Fast RCNN 的改进可以用下面两幅图概括。其中,左图是原 RCNN 的做法,而右图则是 Fast RCNN 的做法。

有个很形象直观的对比图: R-CNN和SPP-net
FastRCNN改进之后:
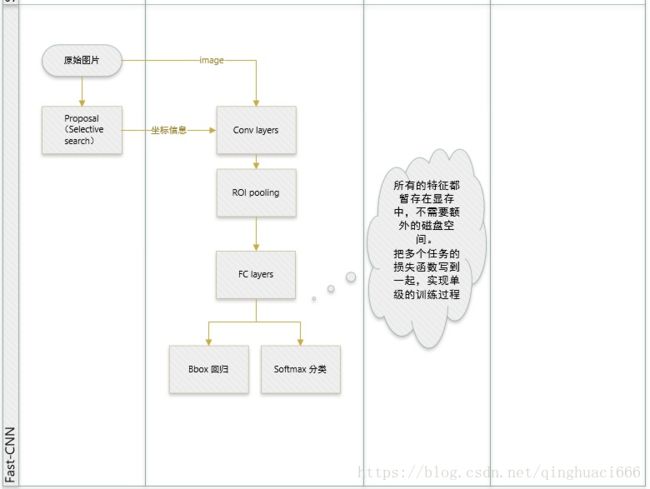
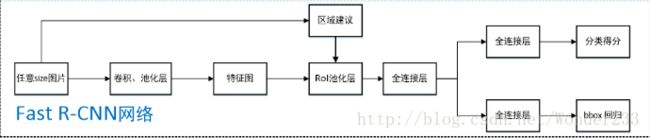
2.系统结构
整体框架大致如上述所示,几句话总结:
1.用selective search在一张图片中生成约2000个object proposal,即RoI。
2.把图像输入到卷积网络中,并输入候选框,在最后一个卷积层上对每个ROI求映射关系,并用一个RoI pooling layer来统一到相同的大小,得到 (fc)feature vector,即一个固定维度的特征表示。
3.继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的FC层,得到两个输出向量:第一个是分类,使用softmax,第二个是每一类的bounding box回归。
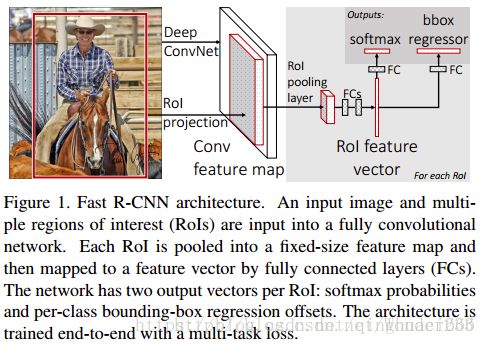
具体来讲,训练过程如下:
1、网络首先用几个卷积层(conv)和最大池化层处理整个图像(224*224)以产生conv特征图。
2、然后,对于每个对象建议框(object proposals ,~2000个),感兴趣区域(region of interest——RoI)池层从特征图提取固定长度的特征向量。
3、每个特征向量被输送到分支成两个同级输出层的全连接(fc)层序列中:
其中一层进行分类,对 目标关于K个对象类(包括全部“背景background”类)产生softmax概率估计,即输出每一个RoI的概率分布;
另一层进行bbox regression,输出K个对象类中每一个类的四个实数值。每4个值编码K个类中的每个类的精确边界盒(bounding-box)位置,即输出每一个种类的的边界盒回归偏差。整个结构是使用多任务损失的端到端训练(trained end-to-end with a multi-task loss)。
另外还有一个关于测试过程的总结也写得不错:Fast R-CNN论文详解
- 任意size图片输入CNN网络,经过若干卷积层与池化层,得到特征图;
- 在任意size图片上采用selective search算法提取约2k个建议框;
- 根据原图中建议框到特征图映射关系,在特征图中找到每个建议框对应的特征框【深度和特征图一致】,并在RoI池化层中将每个特征框池化到H×W【VGG-16网络是7×7】的size;
- 固定H×W【VGG-16网络是7×7】大小的特征框经过全连接层得到固定大小的特征向量;
- 第4步所得特征向量经由各自的全连接层【由SVD分解实现】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;
- 利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
整体框架大致如上述所示了,对比SPP-Net,可以看出FRCN大致就是一个joint training版本的SPP-Net,改进如下:
- SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层。
- SPP-Net后面的需要将第二层FC的特征放到硬盘上训练SVM,之后再额外训练bbox regressor。
3.特征提取网络
3.1基本结构
Fast RCNN对图像额输入尺寸没有严格限制,ROI Pooling层的的存在确保全连接层的输入是固定尺寸。
前五阶段是基础的conv+relu+pooling形式,在第五阶段结尾,输入P个候选区域(图像序号×1+几何位置×4,序号用于训练)。 
注:文中给出了大中小三种网络,此处示出最大的一种。三种网络基本结构相似,仅conv+relu层数有差别,或者增删了norm层。
3.2 ROI Pooling Layer
为了让全联接层能够接收 Conv-Pooling 后的特征,有两种方法:
- 要么是重新调整 pooling 后的特征维度,使它适应全联接层
- 要么是改变全联接层的结构,使它可以接收任意维度的特征
后者一个有效的解决方案是 FCN(全卷积网络),不过 Fast RCNN 出来之时还没有 FCN,因此它采用的是前一种思路。
那要如何调整 pooling 后的特征呢?论文提出了一种 ROI Pooling Layer 的方法(ROI 指的是 Region of Interest)。事实上,这种方法并不是 Fast RCNN 的原创,而是借鉴了 SPPNet 的思路。关于 SPPNet,网上资料很多,就不再赘述了,所以我开门见山讲一下 ROI Pooling Layer 是怎么处理的。假设首个全联接层接收的特征维度是 H∗W∗D,例如 VGG16 的第一个 FC 层的输入是 7 * 7 * 512,其中 512 表示 feature map 的层数。那么,ROI Pooling Layer 的目标,就是让 feature map 上的 ROI 区域,在经过 pooling 操作后,其特征输出维度满足 H∗W。具体做法是,对原本 max pooling 的单位网格进行调整,使得 pooling 的每个网格大小动态调整为 h / H∗w / W(假设 ROI 区域的长宽为 h∗w)。这样,一个 ROI 区域可以得到 H∗W 个网格。然后,每个网格内依然采用 max pooling 操作。如此一来,不管 ROI 区域大小如何,最终得到的特征维度都是 H∗W∗D。
下图显示的,是在一张 feature map 上,对一个 5 * 7 的 ROI 区域进行 ROI Pooling 的结果,最后得到 2 * 2 的特征。
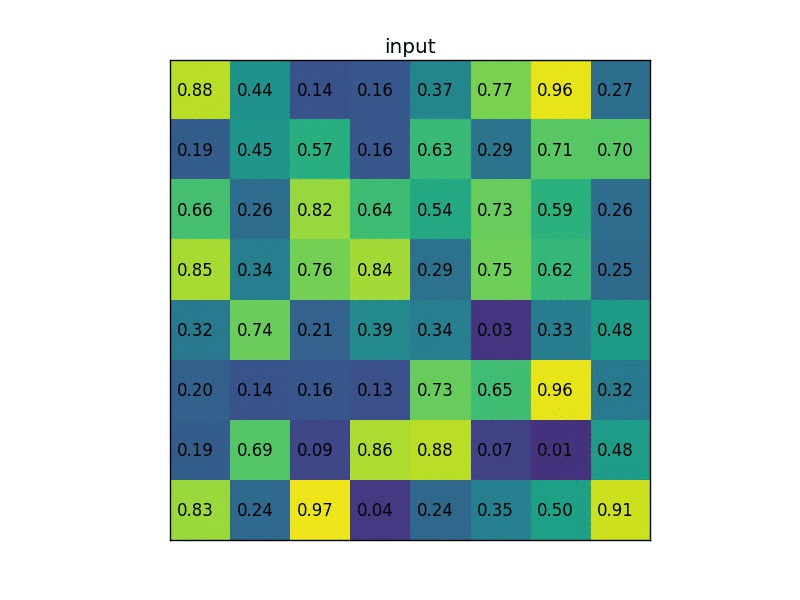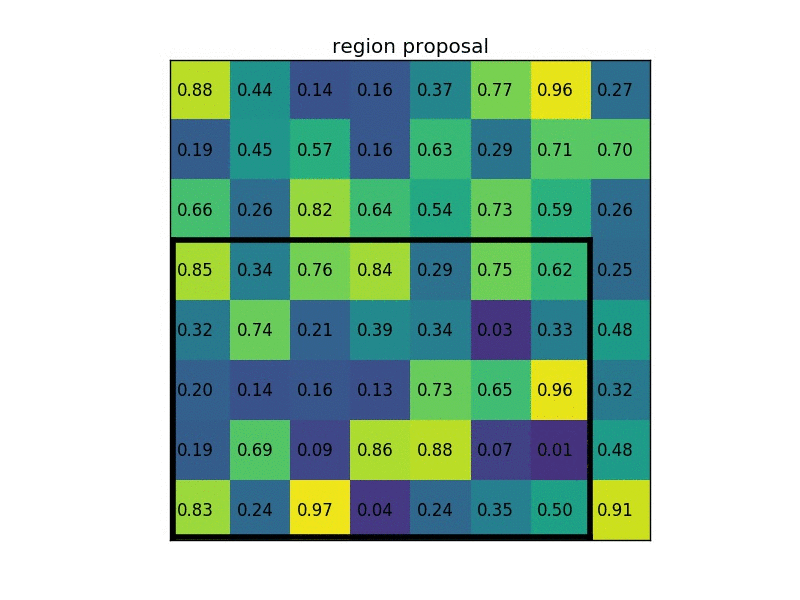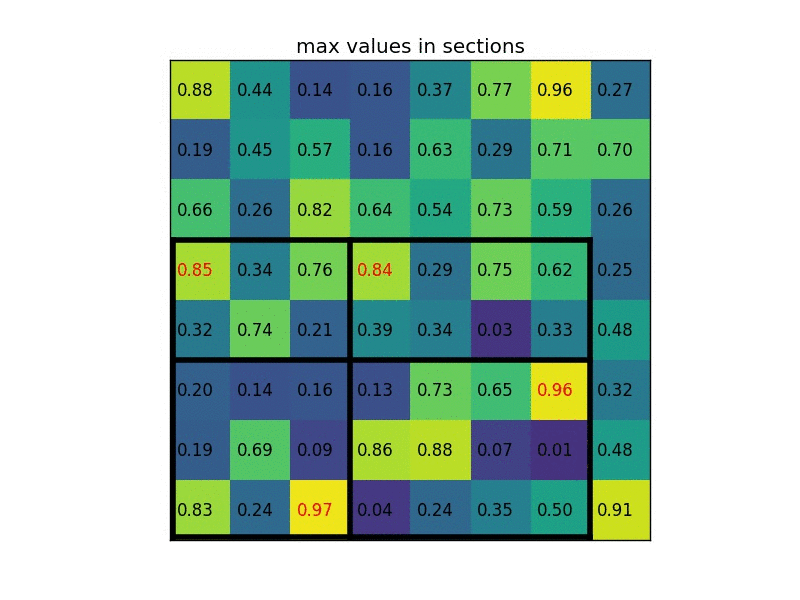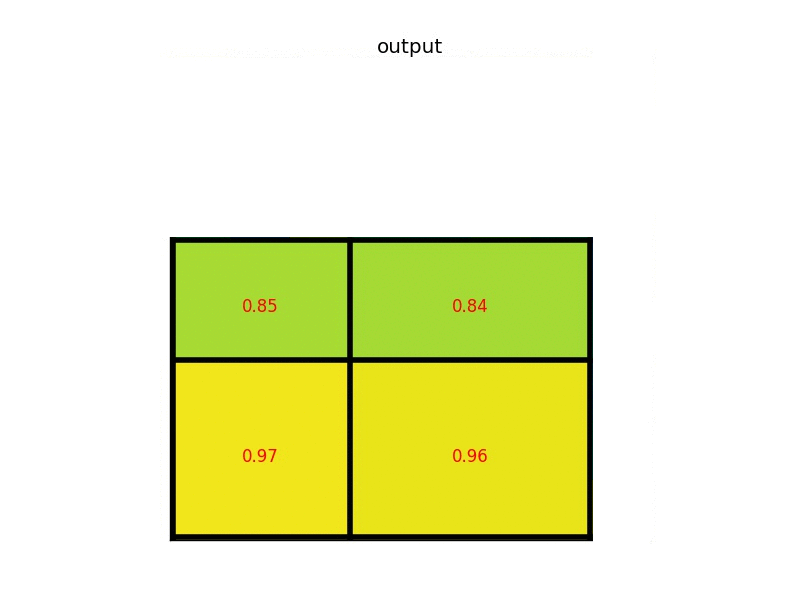
这时,可能有人会问,如果 ROI 区域太小怎么办?比如,拿 VGG16 来说,它要求 Pooling 后的特征为 7 * 7 * 512,如果碰巧 ROI 区域只有 6 * 6 大小怎么办?还是同样的办法,每个网格的大小取 6 / 7∗6 / 7=0.85∗0.85,然后,以宽为例,按照这样的间隔取网格:[0,0.85,1.7,2.55,3.4,4.25,5.1,5.95]
取整后,每个网格对应的起始坐标为:[0,1,2,3,3,4,5]
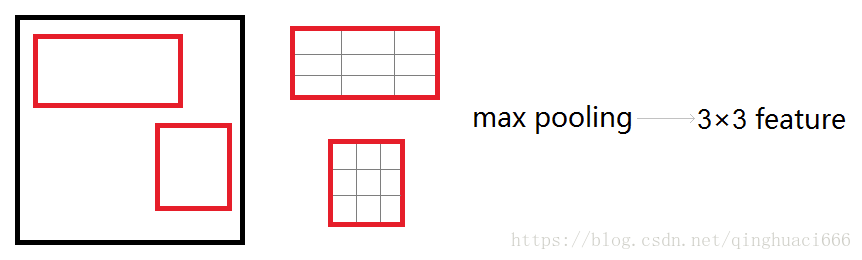
再如将大小不同的区域pooling为3*3:
3.3 Back-propagation through RoI pooling layers. 通过RoI池化层的反向传播。
从这篇借鉴理解RoI池化层:Fast R-CNN论文详解
1.首先看普通max pooling层如何求导
设xi为输入层节点,yi为输出层节点,那么损失函数L对输入层节点xi的梯度为:
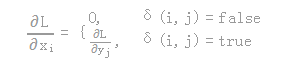
其中判决函数δ(i,j)表示输入i节点是否被输出j节点选为最大值输出。
不被选中【δ(i,j)=false】有两种可能:xi不在yi范围内,或者xi不是最大值。
若选中【δ(i,j)=true 】则由链式规则可知损失函数L相对xi的梯度等于损失函数L相对yi的梯度×(yi对xi的梯度->恒等于1),故可得上述所示公式;
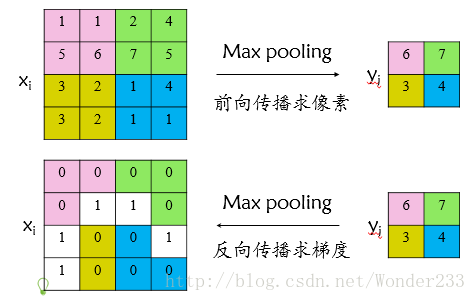
2.RoI max pooling层求导
设xi为输入层的节点,yri 为第r个候选区域的第j个输出节点,一个输入节点可能和多个输出节点相关连,如下图所示,输入节点7和两个候选区域输出节点相关连;
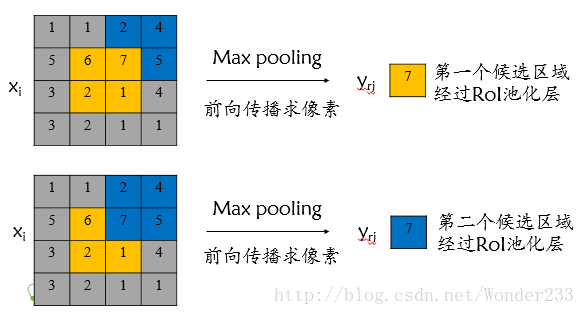
该输入节点7的反向传播如下图所示。
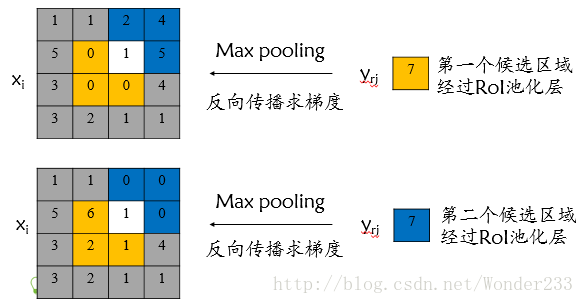
对于不同候选区域,节点7都存在梯度,所以反向传播中损失函数 L 对输入层节点 xi 的梯度为损失函数 L 对各个有可能的候选区域 r 【 xi 被候选区域r的第j个输出节点选为最大值 】输出 yri 梯度的累加,具体如下公式所示:
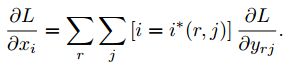
其中:
![]()
判决函数 [i=i∗(r,j)] 表示 i 节点是否被候选区域r 的第j 个输出节点选为最大值输出,若是,则由链式规则可知损失函数L相对 xi 的梯度等于损失函数 L 相对yri 的梯度×( yrj 对xi 的梯度->恒等于1),上图已然解释该输入节点可能会和不同的yrj有关系,故损失函数L相对xi 的梯度为求和形式。
4.网络参数训练
4.1参数初始化
网络除去末尾部分如下图,在ImageNet上训练1000类分类器。结果参数作为相应层的初始化参数。 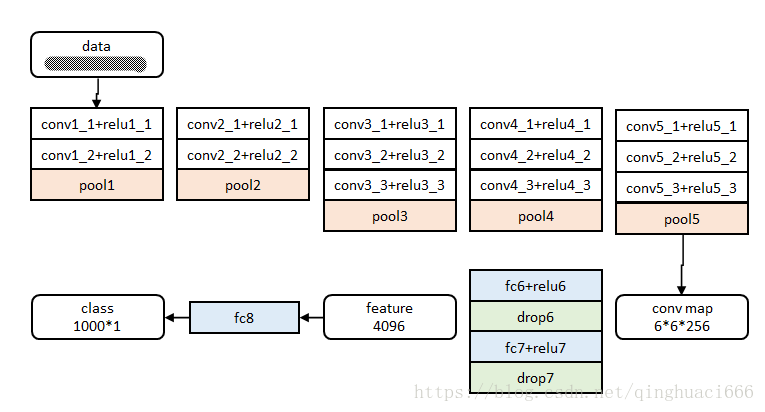
其余参数随机初始化。
4.2分层数据
在调优训练时,每一个mini-batch中首先加入N张完整图片,而后加入从N张图片中选取的R个候选框。这R个候选框可以复用N张图片前5个阶段的网络特征。
实际选择N=2, R=128。
4.3训练数据构成,Mini-batch sampling.
作者从对象建议框(object proposal)中选择25%的RoI,这些RoI与ground-truth bbox边界框至少有0.5的部分交叉重叠,也就是正样本,即 u >= 1。其余的RoI选那些IoU重叠区间在[0.1,0.5)的,作为负样本,即 u = 0,大约为75%。之所以选择负样本需要大于0.1的阈值是因为使用启发式的hard example mining(低于0.1的IoU作为难例挖掘的启发式)。在训练期间,图像有0.5的概率水平翻转。R个候选框的构成方式如下:
| 类别 | 比例 | 方式 |
|---|---|---|
| 前景 | 25% | 与某个真值重叠在[0.5,1]的候选框 |
| 背景 | 75% | 与真值重叠的最大值在[0.1,0.5)的候选框 |
5.分类与位置调整
5.1子网络结构
第五阶段的特征输入到两个并行的全连层中(称为multi-task)。

cls_score层用于分类,输出K+1维数组p,表示属于K类和背景的概率。
bbox_prdict层用于调整候选区域位置,输出4*K维数组t,表示分别属于K类时,应该平移缩放的参数。
源码中bbox_loss_weights用于标记每一个bbox是否属于某一个类
5.2 多任务损失函数


作者这样设置的目的是想让loss对于离群点更加鲁棒,控制梯度的量级使得训练时不容易跑飞。 最后在5.1的讨论中,作者说明了Multitask loss是有助于网络的performance的。
smooth L1损失函数曲线如下图所示,相比于L2损失函数,其对离群点、异常值不敏感,可控制梯度的量级使训练时不容易跑飞;
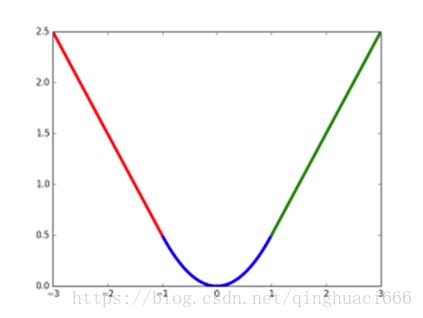
5.3 全连接层提速

在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。 
在github的源码中,这部分似乎没有实现。
6.实验与结论
实验过程不再详述,只记录结论
- 网络末端同步训练的分类和位置调整,提升准确度
- 使用多尺度的图像金字塔,性能几乎没有提高
- 倍增训练数据,能够有2%-3%的准确度提升
- 网络直接输出各类概率(softmax),比SVM分类器性能略好
- 更多候选窗不能提升性能
##部分公式有乱码,直接截图了。
参考资料:
1.tf版本:
https://github.com/zplizzi/tensorflow-fast-rcnn
2.caffe版本,原作者
3.RCNN学习笔记(2):Fast R-CNN
https://blog.csdn.net/wonder233/article/details/53671018
4.RCNN学习笔记(4):fast rcnn
https://blog.csdn.net/u011534057/article/details/51241831
5.【目标检测】Fast RCNN算法详解
https://blog.csdn.net/shenxiaolu1984/article/details/51036677
P:重点参考,详细具体
6.Fast RCNN算法详解
https://blog.csdn.net/u014380165/article/details/72851319
7.论文笔记:Fast(er) RCNN
http://jermmy.xyz/2018/01/15/2018-1-15-paper-notes-fast-er-rcnn/
8.Fast-RCNN
https://blog.csdn.net/zijin0802034/article/details/53055010
9.Fast R-CNN
https://zhuanlan.zhihu.com/p/24780395