平台搭建---大数据框架---大数据组件的安装及部署
大数据组件图解
- 所有组件的安装最好都在自己操作的用户下,以免影响root用户下的文件,因为安装如果出错,可能无法还原这些文件,而且存在安全隐患;但有些组件如mysql必须用root用户来安装,因为涉及到修改root用户权限的问题,root用户安装可以避免因一些权限问题导致中间的安装不完全,root用户安装的软件其他用户可读可执行但无法修改。
如果安装的软件涉及到写文件,比如第一次开机,会在配置的某个目录里自动生成一些文件,此时应该给该用户设置读写该目录的权限,或者将文件的拥有都更改为自己的操作用户(需要root用户来更改),否则软件可能运行不成功。
如果不是root用户,会拥有哪些权限?对任意一个目录,可以使用ls -l查看对其的权限。会看到(d|-)rwxrwxrwx这样的权限说明,其中d代表这是一个目录,-则表示是文件,rwx分别对应读写和执行。一般的目录都有r和x权限,正常情况下非root用户只对 主目录和/tmp创建的目录有写的权限。当然/tmp指明了其属性,里面都应该只能放临时性的东西,重要的东西都不应该放里面,说不定什么时候就被清走了,或者系统一重启就清除了。综上所述:用户可以执行很多目录下的程序,但是其工作目录(一般程序都有输出)应该只限于用户的home目录。
再回过头来看为什么安装软件一般都需要root权限。软件默认的安装路径是 /usr/bin,普通用户对这个目录是没有写权限的。安装的时候需要将文件copy到该目录下,所以会提示无权限而操作失败。如果不使用root权限,只能而且应该将软件安装在自己的目录下。为了方便,可以将执行程序所在目录加入到path环境变量里。如果不更新path变量,则运行程序的时候需要指明路径。
- 因为各组件都运行在集群环境,涉及到不同节点的通信、数据传输问题。所以需要确保集群之间的任意主机都能实现免密码登陆其他主机(为了省事就不区分哪些需要登陆哪些不需要),具体网络配置方法可参考ubuntu16.04下hadoop-2.7.4搭建。
- 为了方便部署,可以在一个节点先将环境和各组件安装配置,然后重新将这些文件打包,发送到其他节点。这样其他节点就只剩下修改与节点名称有关或类似相关的部分了。
- 因为在过渡时期可能需要在软件的不同版本间切换,那么我们会同时装几个版本,这时可以通过软链接的方式临时将软件指向某个特定的版本。如
ln -s hadoop-2.6.5 hadoop
HDFS的安装与配置
具体参考另一篇文章。这里做一些补充说明。
core-site.xml 核心内容
namenode一个是在core-site.xml里有指明,另一个是在哪个节点启动bin/dfs.sh start 则该节点为namenode,后者的效力大于前者。
secondaryNameNode一是通过masters文件指明,另一个则是hdfs-site.xml里指明
dfs.namenode.secondary.http-address
bigdata-client:50090
设置SecondaryNameNode
master文件
bigdata-client
**slaves文件 **
这样系统知道哪个节点是slave节点,扮演datanode角色
slave1
slave2
slave3
slave4
slave5
hdfs-site.xml 核心内容
mapred-site.xml 核心内容
核心是设置historyServer,另一个mapreduce角色是client,在哪个节点提交任务哪个节点就是client。但一般建议在连接外网和集群的机器上提交任务。
mapreduce.jobhistory.address
bigdata-master:10020
设置 bigdata-master为mapreduce HistoryServer
yarn-site.xml 核心内容
下面的配置指明了resourceManager,而nodeManager则会与slaves文件的配置的一致。
yarn.resourcemanager.hostname
master
让hadoop知道Java路径
把hadoop-env.sh、mapred-env.sh、yarn-env.sh中的JAVA_HOME改为我们自己安装的JAVA_HOME
source /data/bigdata/soft/env/bigdata
启动hadoop最好使用start-dfs.sh和start-yarn.sh分别启动;第一次启动hadoop前要前格式式namenode
否则namenode启动后又会自动死掉,而且通过50070网页端也访问不了。查看namenode的日志文件会有如下提示。
org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Encountered exception loading fsimage
java.io.IOException: NameNode is not formatted.
spark的安装与配置
spark-env.sh文件核心内容配置环境变量
source /data/bigdata/soft/env/bigdata
如果spark-submit时只是在yarn模型下,则不需要进行其他配置,在哪个节点启动spark哪个节点就扮演historyServer角色,在哪个节点提交程序哪个节点就失控client角色。
如果是在独立模式,则还需要配置slaves文件。
配置spark与hive的连接
如果需要通过spark操作hive则需要配置该文件,只需将该文件简单的指向hive安装目录同名的配置文件,这样spark就能与hive同步了。
hive-site.xml文件核心内容
zookeeper 分布式集群的安装与配置
来源
也可参考官网的安装配置方法
概述
Zookeeper 集群是分布式集群的协调者,也就是任意的分布式集群都能配置Zookeeper集群作为管理者、协调者,Zookeeper 集群在配置时一般采用的是奇数个节点配置的策略。
环境准备
在配置Zookeeper集群时,请确保集群之间的任意主机都能实现免密码登陆其他主机(整个大数据组件基本上都是这个要求)。
免密码登录的实现:
- 第一,你要确定是谁要登陆谁,比如A要实现免密码登陆B
- 第二,将A的id_rsa.pub加入到B的authorized_keys文件中
下载并解压安装包至目标路径
在官网上下载Zookeeper,下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 下载其中的stable版本,稳定版一般不会出现问题。
下载完成之后在一个节点上解压。我将Zookeeper安装在/usr/local路径下。
配置Zookeeper分布式集群
- 1、进入Zookeeper的配置文件夹conf(整个大数据开源组件的配置文件都在对应软件的conf目录下),做以下的操作:
$ cp ./zoo_sample.cfg zoo.cfg #复制模板文件,并修改
$ vim zoo.cfg #打开文件,并修改写入下面的内容
以下是独立模式一个配置样例
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/bigdata/data/zookeeper
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
上面的配置中最重要的是指定dataDir。
其他的都不需要操作,zookeeper运行时会在dataDir指定的目录下生成version-2文件夹和 zookeeper_server.pid
以下是集群模式一个配置样例
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/bigdata/data/zookeeper
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=master:2888:3888
server.2=slave4:2888:3888
server.3=slave5:2888:3888
上面配置的重点也是dataDir和server.n(如server.1=master:2888:3888,server.1表示zookeeper服务器第1服务,master为对应节点主机名称)。同样会在dataDir生成 version-2文件夹和 zookeeper_server.pid。同时注意在对应节点中dataDir目录新建文件myid,内部内容和数字与server.n相对应(第2点中会具体讲解)。
完成之后将整个Zookeeper分发到其他的Zookeeper节点,分发采用scp命令。
- 2、 修改各个节点的id值,需要注意,每个节点都是需要做下面操作的
$ cd /data/bigdata/data/zookeeper
$ vim myid
分别在各个节点上写入对应的id,从1开始,每个节点只写一个数字,比如在Master上写1,在Slave1上写2,以此类推。与zoo.cfg中的配置相应一致。其实对于使用zookeeper的应用来说,它们看zookeeper各节点的功能是一样的,只不过zookeeper自己会有一个zookeeper_server.pid
- 3、在各个节点上配置环境变量(我更喜欢在/etc/profile中添加)
$ vim ~/.bash_profile #修改环境变量
在其中写入下面的内容
$ export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.8
$ PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
$ source ~/.bash_profile
由于各组件都涉及增加环境变量,为了管理和配置的方便,可以将这些环境变量统一配置
比如新建一个文件/env/bigdata
if [ "${BIGDATA_ENV}" != "1" ]; then
export BIGDATA_ENV=1
export JAVA_HOME=/data/bigdata/soft/java
export HADOOP_HOME=/data/bigdata/soft/hadoop
export HIVE_HOME=/data/bigdata/soft/hive
export SPARK_HOME=/data/bigdata/soft/spark
export HBASE_HOME=/data/bigdata/soft/hbase
export KAFKA_HOME=/data/bigdata/soft/kafka
export ZOOKEEPER_HOME=/data/bigdata/soft/zookeeper
export FLUME_HOME=/data/bigdata/soft/flume
PATH=${JAVA_HOME}/bin:${PATH}
PATH=${HADOOP_HOME}/bin:${PATH}
PATH=${HIVE_HOME}/bin:${PATH}
PATH=${SPARK_HOME}/bin:${PATH}
PATH=${HBASE_HOME}/bin:${PATH}
PATH=${KAFKA_HOME}/bin:${PATH}
PATH=${ZOOKEEPER_HOME}/bin:${PATH}
PATH=${FLUME_HOME}/bin:${PATH}
export PATH
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_USER_CLASSPATH_FIRST=true
export HADOOP_HEAPSIZE=1024
export YARN_HEAPSIZE=1024
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
export YARN_LOG_DIR=${HADOOP_HOME}/logs
export HADOOP_PID_DIR=${HADOOP_HOME}/pids
export HBASE_MANAGES_ZK=false
fi
然后在/etc/profile文件中添加以下命令
source /data/bigdata/soft/env/bigdata
启动zookeeper服务器
要注意,按照上述配置的顺序依次启动,并且在各个节点上都要启动Zookeeper,在shell中输入
$ zkServer.sh start #启动Zookeeper服务,正确启动只有,使用jps命令会看到QuorumPeerMain,如果该进程启动说明Zookeeper服务成功的启动
$ zkServer.sh status #查看Zookeeper服务的状态,你会看到哪个节点是Leader节点,哪个节点是Follower节点,并且只有一个Zookeeper节点
$ zkServer.sh stop #停止Zookeeper服务,每个节点都要停止
Kafka分布式集群的安装与配置
来源1、来源2
也可参考官网文档
概述
Kafka是一种高吞吐量的分布式发布订阅的消息队列系统,原本开发自LinkedIn,用作LinkedIn的活动流(ActivityStream)和运营数据处理管道(Pipeline)的基础。现在它已被多家不同类型的公司作为多种类型的数据管道和消息系统使用。
环境准备
同上
下载并解压安装包至目标路径
在官网上下载Kafka,下载地址:http://kafka.apache.org/downloads。
下载完成之后在一个节点上解压。我将kafka安装在/usr/local路径下。
配置kafka分布式集群
Kafka目录介绍
- /bin 操作kafka的可执行脚本,还包含windows下脚本
- /config 配置文件所在目录
- /libs 依赖库目录
- /logs 日志数据目录,目录kafka把server端日志分为5种类型,分为:server,request,state,log-cleaner,controller
进入kafka的配置文件夹conf(整个大数据开源组件的配置文件都在对应软件的conf目录下),做以下的操作:
- 配置zookeeper
kafka有内置的zookeeper,但一般我们会使用自己安装的,提高可用性和可靠性。安装配置参考zookeeper相关内容。 - 进入kafka安装工程根目录编辑config/server.properties
kafka最为重要三个配置依次为:broker.id、log.dir、zookeeper.connect
下面是kafka只有一个broker时的配置样例
...
broker.id=0
log.dirs=/tmp/kafka-logs
zookeeper.connect=localhost:2181
...
下面是kafka有两个broker时的配置样例
#slave4的配置文件
...
broker.id=1
listeners=PLAINTEXT://slave4:9092
log.dirs=/data/bigdata/data/kafka
zookeeper.connect=master:2181,slave4:2181,slave5:2181
...
#slave5的配置文件
...
broker.id=2
listeners=PLAINTEXT://slave5:9092
log.dirs=/data/bigdata/data/kafka
zookeeper.connect=master:2181,slave4:2181,slave5:2181
...
以上就是配置文件关键要修改或添加的部分,其中zookeeper.connect即zookeeper中配置的zookeeper服务器,共3个。
完成之后将整个kafka 分发到其他的kafka 节点,分发采用scp命令。
- 在各个节点上配置环境变量
kafka server端config/server.properties参数说明和解释如下:
server.properties配置属性说明:
| 参数 | 说明(解释) |
|---|---|
| broker.id =0 | 每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况 |
| log.dirs=/data/kafka-logs | kafka数据的存放地址,多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能 /data/kafka-logs-1,/data/kafka-logs-2 |
| port =9092 | broker server服务端口 |
| message.max.bytes =6525000 | 表示消息体的最大大小,单位是字节 |
| num.network.threads =4 | broker处理消息的最大线程数,一般情况下数量为cpu核数 |
| num.io.threads =8 | broker处理磁盘IO的线程数,数值为cpu核数2倍 |
| background.threads =4 | 一些后台任务处理的线程数,例如过期消息文件的删除等,一般情况下不需要去做修改 |
| queued.max.requests =500 | 等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,应该是一种自我保护机制。 |
| host.name | broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置 |
| socket.send.buffer.bytes=100*1024 | socket的发送缓冲区,socket的调优参数SO_SNDBUFF |
| socket.receive.buffer.bytes =100*1024 | socket的接受缓冲区,socket的调优参数SO_RCVBUFF |
| socket.request.max.bytes =10010241024 | socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖 |
| log.segment.bytes =102410241024 | topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖 |
| log.roll.hours =24*7 | 这个参数会在日志segment没有达到log.segment.bytes设置的大小,也会强制新建一个segment会被 topic创建时的指定参数覆盖 |
| log.cleanup.policy = delete | 日志清理策略选择有:delete和compact主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖 |
| log.retention.minutes=300或log.retention.hours=24 | 数据文件保留多长时间, 存储的最大时间超过这个时间会根据log.cleanup.policy设置数据清除策略 log.retention.bytes和log.retention.minutes或log.retention.hours任意一个达到要求,都会执行删除 有2删除数据文件方式: 按照文件大小删除:log.retention.bytes 按照2中不同时间粒度删除:分别为分钟,小时 |
| log.retention.bytes=-1 | topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes。-1没有大小限log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖 |
| log.retention.check.interval.ms=5minutes | 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略 |
| log.cleaner.enable=false | 是否开启日志清理 |
| log.cleaner.threads = 2 | 日志清理运行的线程数 |
| log.cleaner.io.max.bytes.per.second=None | 日志清理时候处理的最大大小 |
| log.cleaner.dedupe.buffer.size=50010241024 | 日志清理去重时候的缓存空间,在空间允许的情况下,越大越好 |
| log.cleaner.io.buffer.size=512*1024 | 日志清理时候用到的IO块大小一般不需要修改 |
| log.cleaner.io.buffer.load.factor =0.9 | 日志清理中hash表的扩大因子一般不需要修改 |
| log.cleaner.backoff.ms =15000 | 检查是否处罚日志清理的间隔 |
| log.cleaner.min.cleanable.ratio=0.5 | 日志清理的频率控制,越大意味着更高效的清理,同时会存在一些空间上的浪费,会被topic创建时的指定参数覆盖 |
| log.cleaner.delete.retention.ms =1day | 对于压缩的日志保留的最长时间,也是客户端消费消息的最长时间,同log.retention.minutes的区别在于一个控制未压缩数据,一个控制压缩后的数据。会被topic创建时的指定参数覆盖 |
| log.index.size.max.bytes =1010241024 | 对于segment日志的索引文件大小限制,会被topic创建时的指定参数覆盖 |
| log.index.interval.bytes =4096 | 当执行一个fetch操作后,需要一定的空间来扫描最近的offset大小,设置越大,代表扫描速度越快,但是也更好内存,一般情况下不需要搭理这个参数 |
| log.flush.interval.messages=None 例如log.flush.interval.messages=1000 表示每当消息记录数达到1000时flush一次数据到磁盘 |
log文件”sync”到磁盘之前累积的消息条数,因为磁盘IO操作是一个慢操作,但又是一个”数据可靠性"的必要手段,所以此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡.如果此值过大,将会导致每次"fsync"的时间较长(IO阻塞),如果此值过小,将会导致"fsync"的次数较多,这也意味着整体的client请求有一定的延迟.物理server故障,将会导致没有fsync的消息丢失. |
| log.flush.scheduler.interval.ms =3000 | 检查是否需要固化到硬盘的时间间隔 |
| log.flush.interval.ms = None 例如:log.flush.interval.ms=1000 表示每间隔1000毫秒flush一次数据到磁盘 |
仅仅通过interval来控制消息的磁盘写入时机,是不足的.此参数用于控制"fsync"的时间间隔,如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔达到阀值,也将触发. |
| log.delete.delay.ms =60000 | 文件在索引中清除后保留的时间一般不需要去修改 |
| log.flush.offset.checkpoint.interval.ms =60000 | 控制上次固化硬盘的时间点,以便于数据恢复一般不需要去修改 |
| auto.create.topics.enable =true | 是否允许自动创建topic,若是false,就需要通过命令创建topic |
| default.replication.factor =1 | 是否允许自动创建topic,若是false,就需要通过命令创建topic |
| num.partitions =1 | 每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖 |
| 以下是kafka中Leader,replicas配置参数 | |
| controller.socket.timeout.ms =30000 | partition leader与replicas之间通讯时,socket的超时时间 |
| controller.message.queue.size=10 | partition leader与replicas数据同步时,消息的队列尺寸 |
| replica.lag.time.max.ms =10000 | replicas响应partition leader的最长等待时间,若是超过这个时间,就将replicas列入ISR(in-sync replicas),并认为它是死的,不会再加入管理中 |
| replica.lag.max.messages =4000 | 如果follower落后与leader太多,将会认为此follower[或者说partition relicas]已经失效 ##通常,在follower与leader通讯时,因为网络延迟或者链接断开,总会导致replicas中消息同步滞后 ##如果消息之后太多,leader将认为此follower网络延迟较大或者消息吞吐能力有限,将会把此replicas迁移 ##到其他follower中. ##在broker数量较少,或者网络不足的环境中,建议提高此值. |
| replica.socket.timeout.ms=30*1000 | follower与leader之间的socket超时时间 |
| replica.socket.receive.buffer.bytes=64*1024 | leader复制时候的socket缓存大小 |
| replica.fetch.max.bytes =1024*1024 | replicas每次获取数据的最大大小 |
| replica.fetch.wait.max.ms =500 | replicas同leader之间通信的最大等待时间,失败了会重试 |
| replica.fetch.min.bytes =1 | fetch的最小数据尺寸,如果leader中尚未同步的数据不足此值,将会阻塞,直到满足条件 |
| num.replica.fetchers=1 | leader进行复制的线程数,增大这个数值会增加follower的IO |
| replica.high.watermark.checkpoint.interval.ms =5000 | 每个replica检查是否将最高水位进行固化的频率 |
| controlled.shutdown.enable =false | 是否允许控制器关闭broker ,若是设置为true,会关闭所有在这个broker上的leader,并转移到其他broker |
| controlled.shutdown.max.retries =3 | 控制器关闭的尝试次数 |
| controlled.shutdown.retry.backoff.ms =5000 | 每次关闭尝试的时间间隔 |
| leader.imbalance.per.broker.percentage =10 | leader的不平衡比例,若是超过这个数值,会对分区进行重新的平衡 |
| leader.imbalance.check.interval.seconds =300 | 检查leader是否不平衡的时间间隔 |
| offset.metadata.max.bytes | 客户端保留offset信息的最大空间大小 |
| kafka中zookeeper参数配置 | |
| zookeeper.connect = localhost:2181 | zookeeper集群的地址,可以是多个,多个之间用逗号分割 hostname1:port1,hostname2:port2,hostname3:port3 |
| zookeeper.session.timeout.ms=6000 | ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大 |
| zookeeper.connection.timeout.ms =6000 | ZooKeeper的连接超时时间 |
| zookeeper.sync.time.ms =2000 | ZooKeeper集群中leader和follower之间的同步实际那 |
启动Kafka服务器
启动kafka之前先启动zookeeper,启动kafka如下:
启动: bin/kafka-server-start.sh config/server.properties,生产环境最好以守护程序启动:nohup &
结束: bin/kafka-server-stop.sh
启动后可以进行一些测试,具体可参考官网的使用说明。
**单机连通性测试 **
运行producer:
Shell代码 收藏代码
bin/kafka-console-producer.sh --broker-list master:9092 --topic test
运行consumer:
bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test --from-beginning
在producer端输入字符串并回车,查看consumer端是否显示。
分布式连通性测试
Zookeeper Server, Kafka Server, Producer都放在服务器server1上,ip地址为192.168.1.10
Consumer放在服务器server2上,ip地址为192.168.1.12。
分别运行server1的producer和server2的consumer,
bin/kafka-console-producer.sh --broker-list master:9092 --topic test
bin/kafka-console-consumer.sh --zookeeper master:2181 --topic test --from-beginning
flume的安装与配置
可参考官网
来源
Flume 各种坑
单节点 Flume 配置、多 agent 汇聚写入 HDFS
安装与简单使用
flume的配置可以将环境变量加入flume-env.sh文件中,但也可以不配置。
更常见的是使用flume的程序中传入相关参数。将与程序相关的agent配置与程序打包在一块,一来这样安装目录比较清洁,安装程序迁移比较方便;另一方面,这种与程序相关的配置是特异性,与程序在一起,如果程序的功能改变,配置文件需要改变的话,改起来就比较方便。
Flume简介
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方用于收集数据,同时Flume提供对数据的简单处理,并将数据处理结果写入各种数据接收方的能力。
Flume作为Cloudera开发的实时日志收集系统,受到了业界的认可与广泛应用。2010年11月Cloudera开源了Flume的第一个可用版本0.9.2,这个系列版本被统称为Flume-OG。随着Flume功能的扩展,Flume-OG代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在Flume-OG的最后一个发行版本 0.94.0中,日志传输不稳定的现象尤为严重。为了解决这些问题,2011年10月Cloudera重构了核心组件、核心配置和代码架构,重构后的版本统称为Flume-NG。改动的另一原因是将 Flume 纳入 Apache 旗下,Cloudera Flume改名为Apache Flume。
Flume工作原理
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。以下是Flume的一些核心概念:
(1)Events:一个数据单元,带有一个可选的消息头,可以是日志记录、avro 对象等。
(2)Agent:JVM中一个独立的Flume进程,包含组件Source、Channel、Sink。
(3)Client:运行于一个独立线程,用于生产数据并将其发送给Agent。
(4)Source:用来消费传递到该组件的Event,从Client收集数据,传递给Channel。
(5)Channel:中转Event的一个临时存储,保存Source组件传递过来的Event,其实就是连接 Source 和 Sink ,有点像一个消息队列。
(6)Sink:从Channel收集数据,运行在一个独立线程。
Flume以Agent为最小的独立运行单位,一个Agent就是一个JVM。单Agent由Source、Sink和Channel三大组件构成,如下图所示:

值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source、Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上;Sink可以把日志写入HDFS、HBase、ES甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说多个Agent可以协同工作,如下图所示:
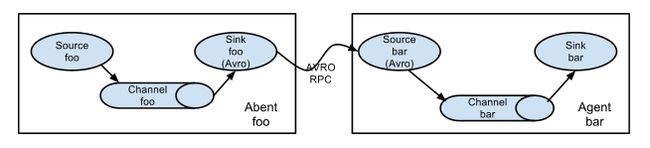
Flume的安装
安装JDK
下载安装包并解压
配置环境变量
配置flume-env.sh文件
$ vim flume-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79
export HADOOP_HOME=/home/hadoop/app/cdh/hadoop-2.6.0-cdh5.7.1
直接source总的配置文件更方便。
配置flume-env.sh文件
Flume部署(以连接kafka为例,来源)
创建配置文件
flume的配置文件在conf/目录下,默认的配置文件是flume-conf.properties,其实名字可随便取(这里取为sink2Kafka.conf),我们可以为不同的任务创建不同的配置文件,然后在启动flume时传递该配置文件即可。
#source
a1.sources = sysSrc
a1.sources.sysSrc.type=avro
a1.sources.sysSrc.bind=master
a1.sources.sysSrc.port=33333
a1.sources.sysSrc.channels=fileChannel
#channel
a1.channels = fileChannel
a1.channels.fileChannel.type =memory
a1.channels.fileChannel.capacity=10000
a1.channels.fileChannel.transactionCapacity = 100
#sink
a1.sinks = kafkaSink
a1.sinks.kafkaSink.channel=fileChannel
a1.sinks.kafkaSink.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafkaSink.brokerList=master:9092
a1.sinks.kafkaSink.custom.partition.key=kafkaPartition
a1.sinks.kafkaSink.topic=my-replicated-topic
a1.sinks.kafkaSink.serializer.class=kafka.serializer.StringEncoder
关于flume配置参数更详细可参考:Flume配置参数说明
启动flume
保证zookeeper正常启动同时kafka也正常启动的情况下启动flume。
bin/flume-ng agent --conf conf --conf-file conf/sink2Kafka.conf --name a1 -Dflume.root.logger=INFO,console
启动kafka消费者现场
bin/kafka-console-consumer.sh --zookeeper h2:2181,h3:2181,h4:2181,h8:2181,h9:2181,h10:2181 --topic my-replicated-topic --from-beginning
利用flume带的avro客户端向flume发送消息
bin/flume-ng avro-client --conf conf --host master --port 33333 --filename ../mydata/log2.txt
如果出现类似如下错误(下面是hbase中的提示,flume出错的时候类似。)
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/itcast/hbase-0.98.18-hadoop2/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/itcast/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
是hadoop的slf4j 与hbase的slf4j jar包发生了冲突,移除其中一个即可
结果:可以看到kafka主题T20161031正确收到来自flume的avro客户端发送的消息
多节点集群搭建
flume官网
sparkstreaming+flume
Hive的安装与配置
对之前的配置作一些补充。
hive-site.xml核心内容
hive.metastore.uris
thrift://bigdata-master:9083
该段配置元数据操作的服务和接口
javax.jdo.option.ConnectionURL
jdbc:mysql://bigdata-client:3306/hive?createDatabaseIfNotExist=true
该段配置元数据存储的地方,真正的数据则是存储在hdfs上。
hive-env.sh核心内容
source /data/bigdata/soft/env/bigdata
把MySQL的JDBC驱动包复制到Hive的lib目录下。
JDBC驱动包的版本:mysql-connector-java-X.X.XX-bin.jar
出现如下错误
Caused by: MetaException(message:Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: java.net.ConnectException: 拒绝连接 (Connection refused)
at org.apache.thrift.transport.TSocket.open(TSocket.java:187)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:421)
at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.(HiveMetaStoreClient.java:236)
at org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient.(SessionHiveMetaStoreClient.java:74)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1521)
解决办法:
- 先检查mysql 链接jdbc使用到的启动 JAR是否放到 hive/lib 下面;
- 用命令行,mysql服务器能否正常连接;查看数据库用户权限(GRANT ALL PRIVILEGES ON . TO XX@YY);
有问题会有如下提示:
com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Access denied for user 'digger'@'%' to database 'hive'
- 检查配置hive-site.xml
网上建议新手不要配置下面的内容(如果是集群还是要配置的)
hive.metastore.uris
thrift://xxxxxxxx
Thrift uri for the remote metastore. Used by metastore client to connect to remote metastore.
- 更换掉jline-0.9.94.jar
如果出现如下报错:
Terminal initialization failed; falling back to unsupported
java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected
原因是hadoop目录下存在老版本jline:
/hadoop-2.5.2/share/hadoop/yarn/lib:
-rw-r--r-- 1 root root 87325 Mar 10 18:10 jline-0.9.94.jar
解决方法是:
将hive下的新版本jline的JAR包拷贝到hadoop下:
cp /hive/apache-hive-1.1.0-bin/lib/jline-2.12.jar ./
试试将注掉/etc/mysql/my.cnf中 bind_address=127.0.0.1(应该不需要)
启动hive
首先启动metastore: hive --server metastore &>/dev/null &,日志会空设备其实就是丢弃不在屏幕显示,根据自己需要来设置。
运行hive命令即可启动。
HBase的分布式安装与配置
来源1,来源2
zookeeper 配置
HBase配置
hbase-env.sh
source /data/bigdata/soft/env/bigdata
hbase-site.xml
hbase.rootdir
hdfs://master:8020/hbase
hbase.zookeeper.quorum
master,slave4,slave5
hbase.cluster.distributed
true
分别设置Hbase的Master,和zookeeper的服务器。
regionservers文件
slave1
slave2
slave3
设置RegionServer
Phoenix 介绍和基本用法
Redis 的安装使用
http://www.runoob.com/redis/redis-intro.html
对于利用python需要的安装包:redis-4.0.11.tar.gz ,redis-2.10.5-py2.py3-none-any.whl
Storm的安装使用
http://storm.apache.org/releases/current/Setting-up-development-environment.html
安装合适的版本,需要考虑与之结合的其他组件。
- 下载安装包,如梦apache-storm-1.2.2.tar.gz
- 将安装包解压至目标位置
- 修改storm的配置文件conf/storm.yaml
storm本地伪集群配置大致如下(集群模式的配置请查阅相关资料):
storm.zookeeper.servers:
- "127.0.0.1"
#由于我之前已经在其他节点安装了zookeeper,这里只要改成对应的节点ip即可。
nimbus.seeds: ["127.0.0.1"]
ui.port: 8080
#也可以改为其他端口号,我改成了9090
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
#注意这里supervisor的端口号前有空格,端口号不能用"",网上有的资料有""号,坑死了。
可能碰到的问题:
Unable to create file /pankoo/soft/apache-storm-1.2.2/logs/access-web-nimbus.log
这是storm 安装目录的权限问题,chown XXX:XXX storm即可
java.lang.IllegalArgumentException: Field supervisor.slots.ports must be an Iterable of java.lang.Number
看看supervisor设置的端口号
将端口号加了引号,去掉引号就可以了,如:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 将storm添加至环境变量
- 启动storm
启动之前,要先启动zookeeper.
nohup storm nimbus &
nohup storm supervisor &
nohup storm ui &
启动需要花费数秒钟时间,直到打开http://localhost:9090能正常显示web页说明启动正常
Flink的安装使用
http://ifeve.com/apache-flink-introduction/
https://www.cnblogs.com/leesf456/p/8027772.html
mysql的安装使用
Ubuntu 16.04 上安装 MySQL 5.7 教程
如果出现问题,可查看sudo apt-get install mysql-server 安装不上
Windows系统安装MySQL
MySQL几种经典的安装方式介绍
二进制安装mysql数据库:
- 官网下载mysql-5.7.18-linux-glibc2.5-x86_64.tar.gz
- 解压
- 配置路径
- 添加mysql用户并创建数据库目录
[root@localhost ~]# groupadd mysql
[root@localhost ~]# useradd -r -g mysql -s /bin/false -M mysql
[root@localhost ~]# cd /usr/local/mysql/
[root@localhost mysql]# mkdir data
[root@localhost mysql]# chown -R mysql:mysql /usr/local/mysql/
#注意不是操作软链接,或者可能子目录的拥有者不会发生变化
[root@localhost mysql]# chgrp -R mysql .
[root@localhost mysql]# chmod +755 data/
- 给mysql数据库初始化
[root@localhost mysql]# mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
[root@localhost mysql]#
5.7以后的版本,默认有一个随机密码,而不是没有密码;随机密码就是在初始化的过程中产生,注意将这一随机密码保存下来。
- 添加mysql主配置文件
vim /etc/my.cnf
[client]
socket=/usr/local/mysql/mysql.sock
[mysqld]
basedir=/usr/local/mysql
datadir=/usr/local/mysql/data
pid-file=/usr/local/mysql/data/mysqld.pid
socket=/usr/local/mysql/mysql.sock
log_error=/usr/local/mysql/data/mysqld.err
- 添加mysql服务并且启动
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysqld;service mysqld start

mysql启动时报错:Starting MySQL… ERROR! The server quit without updating PID file (/opt/mysql/data/mysql.pid) 的解决方法 - 同样去事先定义好的/usr/local/mysql/data/目录下找到mysqld.err文件过滤出密码
cd /usr/local/mysql/data/;cat mysqld.err|grep password

- 同样登录mysql数据进行验证!!
mysql -u root -p
第一次登录修改密码的问题:
mysql 报错ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executin
各个平台的mysql重启命令
/etc/init.d/mysqld restart
安装较量级数据库
很多时候可以使得mariaDB来代替mysql,其安装没有mysql那么多依赖和设置。
Linux下rpm包方式离线安装mariaDB
Java 开发环境配置
http://www.runoob.com/java/java-environment-setup.html
Linux 下安装JDK1.8
https://www.cnblogs.com/xuliangxing/p/7066913.html
就是解压、配置环境变量
scala安装
http://www.runoob.com/scala/scala-install.html
http://scala-ide.org/
Hue安装部署
HUE管理工具
Hue安装
高可用Hadoop平台-Hue In Hadoop
Linux下rpm包方式离线安装mariaDB
Hue v4.3.0, released October 17th 2018
Hue 4.3 and its Analytics and Django improvements are out!
Hue Administration Guide
HUE下载链接
一、 HUE简介
Hue是Apache开源的大数据UI组件,可以通过界面操作包括Hdfs、mysql、Hive、Hbase等大部分Hadoop组件。
特点:
- 可视化操作存储在Hdfs的文件
- 提供了编辑区,作为算法的开发调试功能
- 作为客户端,将需要上线的算法文件或者Jar包提交到集群做计算
- 提供了参数配置和定时执行任务的功能
二、 安装
- 下载地址: http://gethue.com/hue-4-and-its-new-interface-is-out
- 下载后解压(本次项目安装在/opt路径下)
tar –zxf hue-4.0.0.tgz –C /opt - 安装依赖
yum -y install krb5-devel cyrus-sasl-gssapi cyrus-sasl-devel libxml2-devel libxslt-devel mysql mysql-devel openldap-devel python-devel python-simplejson sqlite-devel
官网上hue-4.0.1上是说安装
sudo yum install ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel
这个具体根据linux上安装,如果怕出错就装全一点
不提示错误则表示依赖安装成功
cd /opt/hue-4.0.0
make apps
编译成功后会生成/opt/hue-4.0.0/build目录
(或从服务器上复制 scp –r hue-4.0.0 ***.***.***.***:/opt只能在opt下—因在opt下编译待验证)
三、 修改配置
vi /opt/hue-4.0.0/desktop/conf/hue.ini
1. time_zone=Asia/Shanghai
2. # Webserver runs as this user(root设为管理员帐号)
server_user=root
server_group=root
3. 561行[[database]](配置HUE数据库若没有创建一个 CREATE DATABASE `hue` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;)
[[database]]
engine=mysql
host=***.***.***.***
port=3306
user=root
password=root
name=hue
- 703行 [[interpreters]]
定义hue中开放的接口,将需要的接口前面#去掉 - 843行[[hdfs_clusters]]
[[[default]]]
# Enter the filesystem uri(定义HDFS的namespace)
fs_defaultfs=hdfs://hdp (hdfs主备名称)
webhdfs_url=http://hadoop02.***.com:50070/webhdfs/v1 (主)
hadoop_conf_dir=/etc/hadoop/conf
- 867行[[yarn_clusters]]
resourcemanager_host=hadoop02.***.com (yarn resourcemanager 查看地址)
# The port where the ResourceManager IPC listens on
resourcemanager_port=8050
# Whether to submit jobs to this cluster
submit_to=True
# Resource Manager logical name (required for HA)
## logical_name=
# Change this if your YARN cluster is Kerberos-secured
security_enabled=false
# URL of the ResourceManager API
resourcemanager_api_url=http://***-tdp-spark02.***.com:8088
# URL of the ProxyServer API
# proxy_api_url=http://***-tdp-spark02.***.com:8088
# URL of the HistoryServer API
history_server_api_url=http://***-tdp-spark02.***.com:19888
# URL of the Spark History Server
spark_history_server_url=http://***-tdp-spark02.***.com:18080
# In secure mode (HTTPS), if SSL certificates from YARN Rest APIs
# have to be verified against certificate authority
ssl_cert_ca_verify=false
- 1080行[spark]接口定义
[spark]
# Host address of the Livy Server.
livy_server_host=***-tdp-spark02.***.com
# Port of the Livy Server.
livy_server_port=8998
# Configure Livy to start in local 'process' mode, or 'yarn' workers.
livy_server_session_kind=yarn
- 1315行[zookeeper]接口定义
host_ports=***-tdp-spark01.***.com:2181,***-tdp-spark02.***.com:2181,***-tes-ambari.***.com:2181
- 1356行[liboozie]
oozie_url=http://***.26.38.***:11000/oozie
详细见复件:
- 到ambari界面修改livy配置
livy_server_csrf_protection.enabled:改成false,防止跨域
修改为false - 由于集群自带Python2.6,而算法需要python2.7,需要在spark,yarn,oozie里设置Pythond 环境变量
yarn-env template:
export PYSPARK_PYTHON =/usr/anacoda2/bin/python2.7
export PYSPARK_DRIVER_PYTHON=/usr/anacoda2/bin/python2.7
spark-env template:
export PYSPARK_PYTHON =/usr/anacoda2/bin/python2.7
export PYSPARK_DRIVER_PYTHON=/usr/anacoda2/bin/python2.7
四、 启动脚本: cd /opt
由于HUE与其他组件的交互是通过livy来进行的,所以在启动hue之前,其实是需要先启动livy的。
关于livy的消息可参考如下的文章:
Livy:基于Apache Spark的REST服务
spark livy hue
配置:
cat livy-env.sh
export SPARK_HOME=/opt/spark-2.1.1-bin-2.6.0-cdh5.11.1
export SPARK_CONF_DIR=${SPARK_HOME}/conf
export HADOOP_CONF_DIR=/etc/hadoop/conf.cloudera.yarn
vim livy.conf
#默认是local模式
livy.server.session.factory = yarn
启动:
bin/livy-server
#放到后台
bin/livy-server >/dev/null 2>&1 &
sh ./ hue_start.sh
进入浏览器输入***.26.38.***:8888
(假如出现html页面提示找不到表,则需要初始化HUE数据库
cd /opt/hue-4.0.0/build/env
bin/hue syncdb
bin/hue migrate)
HUE问题集锦
error1:当出现
这是由于“IP为***.**.**.**,名字为root”的用户 没有权限访问数据库
解决办法:
grant all privileges on *.* to root@'%' identified by '******' //***表示数据库连接密码
- 根据配置中定义的root用户登录
- 新建一个hdfs用户
- Pyspark代码编辑窗口
- Py文件提交,设置参数和定时任务
Workflow:工作流,到hdfs上选择算法文件,选择参数直接运行
Scheduler:定时,选择已经定义好的Workflow,为参数赋值后设置指定时间运行
a. Workflow
将Spark图标拖到action区域进行编辑
选择从HDFS上传文件
ARGUMENTS为参数定义,可定义多个参数
Option list为运行时spark相关参数(视情况而定)
配置好以后点击右上角设置键,将运行模式client该为cluster
点击保存后并运行填入对应的参数,代码里获取参数
Scheduler
当定义好一个workflow并保存后,可以直接在界面上选择Schedule进行定时执行
保存后运行
附加:
-
配置过程中可能出现的问题:
org.apache.oozie.action.ActionExecutorException: Could not locate Oozie sharelib
a. 执行oozie admin -oozie http://***.26.38.***:11000/oozie -shareliblist查看可利用的包,
b. 执行/usr/hdp/current/oozie-server/bin/oozie-setup.sh sharelib create -fs hdfs://http://***.26.38.***:8020 -locallib /usr/hdp/current/oozie-server/oozie-sharelib.tar.gz将oozie运行所依赖的所有jar上传至hdfs指定路径
2.利用hue配置连续action -
hue启动pyspark等脚本问题,出现csrf跨域,改Livy配置
-
hue出现
’sparksession is not created’,修改spark python版本变量和系统python环境变量 -
hue安装时初始化数据库,执行:
bin/hue syncdb和bin/hue migrate(不然报错找不到表) -
问题:
org.apache.oozie.action.ActionExecutorException: Could not locate Oozie sharelib
a. 执行oozie admin -oozie http://***.26.***.75:11000/oozie -shareliblist查看可利用的包,
b. 执行/usr/hdp/current/oozie-server/bin/oozie-setup.sh sharelib create -fs hdfs://http://***.26.***.75:8020 -locallib /usr/hdp/current/oozie-server/oozie-sharelib.tar.gz将oozie运行所依赖的所有jar上传至hdfs指定路径
c. 在oozie添加配置(第一个路径前可能要加hdfs://ns) -
HDP系统自带python2.6,算法需要python2.7,所以需要在spark和yarn的环境变量里配python2.7的地址
-
python写HANA数据库需要安装dbapi
将这4个文件(dbapi.py, __init__.py, resultrow.py, pyhdbcli.so)添加到/usr/anaconda2/lib/python2.7/site-packages下面
参考https://blogs.sap.com/2014/04/02/%E5%9C%A8python%E4%B8%AD%E8%BF%9E%E6%8E%A5sap-hana/ -
参数传递
HUE变通的方法安装
在集群环境如果没有网,自动下载安装会比较困难。
其他可以将已经安装好的hue,整个拷到其他机。
后面就主要是进行各种配置。
我们一般会将mysql作为HUE的数据库,但mysql并不是一定要在安装HUE的过程中安装,也可以后来安装mysql,再配置给HUE.
关于配置mysql过程中的一些问题,可以参考
Hue添加MySQL数据库
用MySQL解决HUE登录忘记账号、密码
关于HUE的其他资料:
高可用Hadoop平台-Hue In Hadoop
Hadoop 管理工具HUE配置
HUE管理工具
How to build Hue on Ubuntu
Hue Administration Guide