数据挖掘工具---流式处理---storm 教程
批处理和流式处理的应用程序对比
| 解决方案 | Storm | Spark Streaming | Flink | S4 | Hadoop |
|---|---|---|---|---|---|
| 开发者 | UC Berkeley AMPLab | Apache | Yahoo! | Apache | |
| 类型描述 | Twitter的流式处理大数据分析方案 | 支持内存数据集和弹性恢复的分析平台 | 针对流数据和批数据的分布式处理引擎,所有的数据都看作流 | Yahoo!的分布式流式计算平台 | MapReduce范式的第一个开源实现 |
| 吞吐量 | 低 | 高 | 高 | ||
| 延迟 | 毫秒级 | 秒级 | 亳秒级 | ||
| 语义保障 | at least once | exactly once | exactly once/ at least once | ||
| 处理模式 | 单条数据 | 处理批量数据处理 | 单条、批量数据处理 | ||
| 成熟度 | 成熟 | 成熟 | 新兴框架 | ||
| SQL支持 | Beta | 成熟 | 新兴 |
Spark Streaming与Storm 初步认识
storm是什么
部分来源:当storm遇上python
他的官方文档是这样介绍的
Storm is a distributed realtime computation system.
关键词:分布式、实时、计算
你什么时候需要storm
当你有海量数据需要进行实时处理的时候,在这种场景下你往往需要利用到多台机器,而且让你关注的某一类数据按一定的规则路由到确切的节点,从而实现对信息流(往往需是有状态的)的连续计算。
实际上分布式计算就是一大堆节点(一般是在多台机器上)之间的互相通信,而storm管理了这些节点,定义了一个计算的模型(topology)让开发者可以忽略很多细节(比如集群管理、消息队列),从而把实现实时分布式计算任务简单化。
storm的哲学
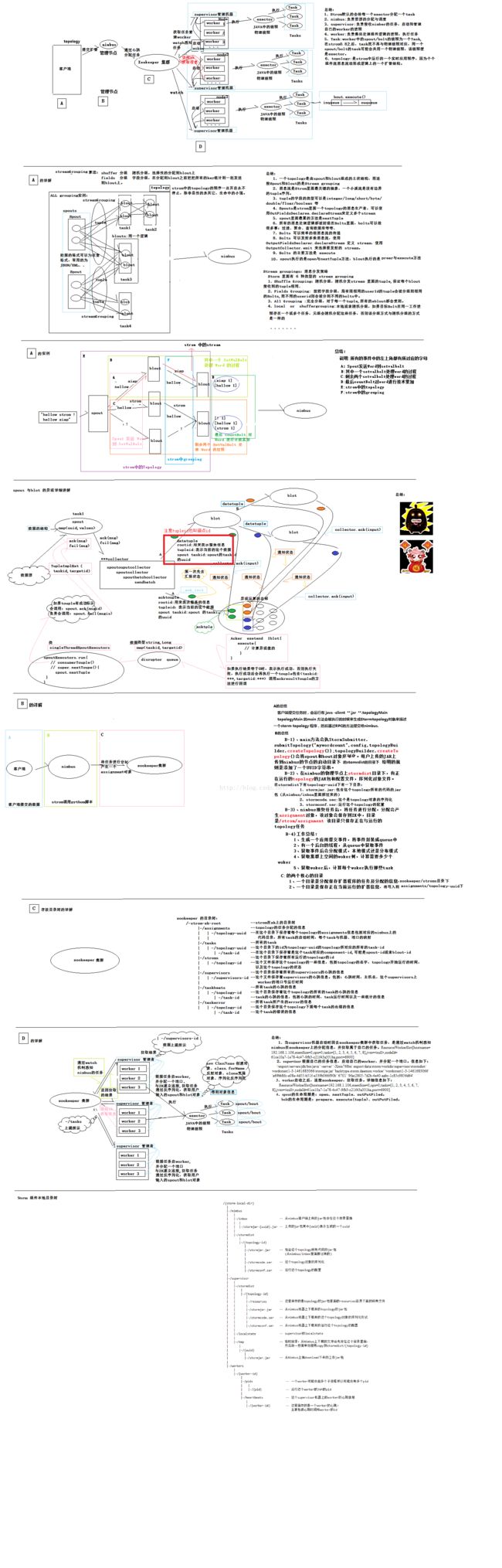
storm的组件
- Nimbus: 分发代码,分发任务,监控错误
- Zookeeper: 管理各个组件,保持系统稳定
- Supervisor: 执行任务,往往多个组成一个拓扑(Topology)
storm的计算模型
- topology: 拓扑,实际上是一副图,代表了对某个计算过程的描述,他的组成部分有 Spout, Bolt, stream
- Spout: 产生数据流,数据流的起点
- Bolt: 接收数据流,执行计算或者重新转发出数据流
- Stream: 数据流,即上图的箭头
- Tuple: 数据流在计算模型中是由无数个tuple组成的所有的节点在这个拓扑中都是并发执行的。
storm的几种路由方式
路由(grouping)定义了stream如何在各个节点之中流动,下面只介绍几种常见方式,如下:
Shuffle grouping: 洗牌模式。随机平均地发配到下游节点上。
Fields grouping: 按照某一个字段来分配,拥有相同值的字段会分配到同一个节点上(即可连续跟踪某个固定特征的数据流)
Global grouping: 强制到某唯一的节点,实际上如果有多个节点去到任务号最低的节点。
all grouping: 强制到所有节点,需小心使用。
Partial Key grouping: 最新支持的,带负载均衡的Fields grouping。
None grouping: 不关心数据流是如何分配的,当前等同于Shuffle grouping。
Direct grouping: 手动指定要流动到的节点。
**Local or shuffle grouping: ** 如果bolt有多个任务,那么数据流只会分配当正在处理的任务;其他情况与shuffle grouping一样 。
关于storm的组成部分与计算哲学的更详细文档
storm执行流程和一些总结
来源
《Storm入门》
来源:
章节目录
第一章 基础知识
介绍Storm的特性以及可能的应用场景。
第二章 起步
讲述了Storm的运行模式,Storm工程包含的组件,以及如何创建一个Storm工程。
第三章 拓扑
对Storm的拓扑结构,各个组件如何分工协作做了详细介绍,数据流分组是本章重点。
第四章 Spouts
介绍Storm的数据源——spouts,Storm的所有数据都从这里开始。
第五章 Bolts
介绍Storm处理数据的组件。
第六章 一个实际的例子
以一个简单的WEB应用讲解如何Storm进行数据分析。
第七章 使用非JVM语言开发
以PHP为例讲述如何使用非JVM语言开发Storm工程。
第八章 事务性拓扑
讲解支持事务的拓扑,当然不要把这里的事务跟关系型数据库的事务等同起来。
附录A
安装Storm客户端,以及常用命令。
附录B
安装与部署Storm集群。
附录C
如何运行第六章的例子
Storm UI 查看_Storm集群的基本信息
来源
通过Storm UI界面Topology Summary下的某个某个拓扑(对应某个storm应用),就可以看到该应用的具体信息,如
Topology summary:
Name Id Owner Status Uptime Num workers Num executors Num tasks Replication count Assigned Mem (MB) Scheduler Info
Topology actions(可对该应用进行一些操作):
Topology stats(在这里可以查看数据的接收情况):
Window Emitted Transferred Complete latency (ms) Acked Failed
Spouts (All time):
Id Executors Tasks Emitted Transferred Complete latency (ms) Acked Failed Error Host Error Port Last error Error Time
Bolts (All time):
Id Executors Tasks Emitted Transferred Capacity (last 10m) Execute latency (ms) Executed Process latency (ms) Acked Failed Error Host Error Port Last error Error Time
Worker Resources:
Host Supervisor Id Port Uptime Num executors Assigned Mem (MB) Components
Topology Visualization:
Topology Configuration:
Cluster Summary : 集群概要
集群概要下的一些指标:
|-- Version 版本信息
|-- Supervisor 子节点的数量. 一个节点可以即做主节点 也做 子节点。 Storm nimbus && Storm supervisor
|-- Total Slots: 总共的槽,所有的子节点的槽相加之和
|-- Free Slots: 可用的槽, 槽:即指监听的端口 , Slots 对应的最后对应的worker, worker对应的Topology。
|-- Used Slots: 已经被使用的槽
|-- Executors: 执行的线程
|-- Tasks:
Numbus Summary:主节点概要
主节点概要下的一些指标:
|-- Uptime 启动的时间
|-- Port 使用的端口号
|-- Version Storm的版本号
Supervisor Summary:子节点概要
子节点概要下的一些指标:
|-- Uptime 启动的时间
|-- Port 使用的端口号
|-- Version Storm的版本号
|-- Num Slots:该子节点槽的数量
|-- Used Slots: 已经被使用的槽的数量
提交storm应用和配置
写好storm的三个文件后,可能需要打成jar包,下面是两个相似的命令
maven clean install (清除并安装)
maven clean package (清除并打包)
运行storm程序的命令
storm jar XXX-comsumer-storm.jar XXX.storm.topology.calc.CalcTopology2 -workers 10 -calc 5
运行strom时会造成内存溢出,可能是因为程序中的问题,造成jvm无法及时回收内存。关于jvm内存回收机制可参考:
JVM内存管理、JVM垃圾回收机制、新生代、老年代以及永久代
关于指定资源可参考下文
Storm拓扑的并行度(parallelism)介绍
使用非JVM语言来操作Storm
- 两步:一是创建topologies ,二是用其他语言来执行spouts 和bolts 。
- 用其他语言创建topologies很容易,因为topologies是thrift 框架(连接到storm.shift)
- 用其他语言来执行spouts和bolts被称作 “multilang components” 或者"shelling"
- 关于协议的详情可参考:Multilang protocol
- thrift 框架让你能够明确地以程序或脚本的方式来定义多语言模块(比如python,py文件会执行你的bolt)
- 对于java语言,通过覆盖ShellBolt 或ShellSpout来创建多语言模块。
- 注意:输出字段声明了thrift 框架中要发生的事情,所以在java中,你可以通过下面的方式来创建多语言模块。
- 用java来声明字段,然后用其它语言来实现处理逻辑并在shellbolt构造器中指明。
- 注意:输出字段声明了thrift 框架中要发生的事情,所以在java中,你可以通过下面的方式来创建多语言模块。
- 各语言都是以json 作为标准输入输出数据格式,以便和其他过程进行通信。
- Storm附带了 Ruby, Python, and Fancy 的适配器的库。以python为例
- python 支持emitting, anchoring, acking, and logging
- “storm shell” 命令使得构建和上传jar变得很容易
- 创建jar并上传
- 通过nimbus 的主机/端口和jarfile id来调用你的应用。
用非java语言执行DSL
从 src/storm.thrift开始是个不错的选择,因为storm的拓扑结构就是Thrift 框架,Nimbus 是一个Thrift 守护进程。你可以用任何语言创建和提交拓扑。
当你为spouts 和bolts创建Thrift 结构时,spout 或bolt 相关的代码是在ComponentObject 结构中指明。
union ComponentObject {
1: binary serialized_java;
2: ShellComponent shell;
3: JavaObject java_object;
}
对于非java DSL,你需要利用 “2” 和"3",ShellComponent 可以设置执行那个组件的脚本(比如你的python代码),JavaObject 可以设置原生java语言的spout 和 bolt (storm会使用映射去创建那个spout 或bolt)。
有一个storm shell命令可以提交一个拓扑结构,用法如下:
storm shell resources/ python topology.py arg1 arg2
storm shell 会将resources/ 下的文件打包进一个jar包,上传这个jar包到Nimbus,并像下面那样调用你的topology.py 脚本:
python topology.py arg1 arg2 {nimbus-host} {nimbus-port} {uploaded-jar-location}
然后你就可以用thift API连接到Nimbus 并提交这个拓扑结构,调用时需要将 {uploaded-jar-location}作为参数传递给提交的submitTopology 方法。下面给出了一个submitTopology 定义的参考:
void submitTopology(1: string name, 2: string uploadedJarLocation, 3: string jsonConf, 4: StormTopology topology)
throws (1: AlreadyAliveException e, 2: InvalidTopologyException ite);
利用python 操作storm
一般的入门会让你开始你的第一个java程序来提交topology,这里会使用python(对,只需要python)来进行示例。
Python目前有两个库,一个是pyleus(yelp公司出品),一个是streamparse。前者在github上已经有两年都不更新了,只支持到storm 0.9。后者一直在更新,需要选择配套的storm和streamparse版本。
python玩storm趟坑记
二十八、在storm上运行python程序
二十九、在storm上运行python程序(修正)
streamparse 快速上手
streamparse Quickstart
streamparse 3.14.0
streamparse API
github主页
依赖
Java and Clojure
具体讲:
1.JDK 7+
2.lein ,lein是Clojure的包管理工具和编译工具,可通过 Leiningen project page 或github
lein的安装有两种方式,一种是用脚本下载安装,一种是直接linux系统安装,如下所示,可能需要添加可靠的源。
yum install lein
我自己的安装方式是
- 下载脚本,windows是一个脚本。具体看官网。
我将脚本另存为lein - 把脚本复制到shell 可以找到的地方,比如/usr/local/bin
- 让脚本可执行
chmod a+x /usr/local/bin/lein - 运行脚本,就会自己下载相关的包leiningen-2.8.1-standalone.jar.
lein文件一定要放在系统路径上
可通过lein version查看lein是否安装,成功安装会有类似如下的显示:
Leiningen 2.3.4 on Java 1.7.0_55 Java HotSpot(TM) 64-Bit Server VM
3.Apache Storm 的开发环境,至少需要 0.10.0以上版本。
具体安装参考另一篇组件安装的资料。
可通过storm version查看strom是否安装。安装成功是有类似如下的显示:
Running: java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/opt/apache-storm-1.0.1 -Dstorm.log.dir=/opt/apache-storm-1.0.1/logs -Djava.library.path=/usr/local/lib:/opt/local/lib:/usr/lib -Dstorm.conf.file= -cp /opt/apache-storm-1.0.1/lib/reflectasm-1.10.1.jar:/opt/apache-storm-1.0.1/lib/kryo-3.0.3.jar:/opt/apache-storm-1.0.1/lib/log4j-over-slf4j-1.6.6.jar:/opt/apache-storm-1.0.1/lib/clojure-1.7.0.jar:/opt/apache-storm-1.0.1/lib/log4j-slf4j-impl-2.1.jar:/opt/apache-storm-1.0.1/lib/servlet-api-2.5.jar:/opt/apache-storm-1.0.1/lib/disruptor-3.3.2.jar:/opt/apache-storm-1.0.1/lib/objenesis-2.1.jar:/opt/apache-storm-1.0.1/lib/storm-core-1.0.1.jar:/opt/apache-storm-1.0.1/lib/slf4j-api-1.7.7.jar:/opt/apache-storm-1.0.1/lib/storm-rename-hack-1.0.1.jar:/opt/apache-storm-1.0.1/lib/log4j-api-2.1.jar:/opt/apache-storm-1.0.1/lib/log4j-core-2.1.jar:/opt/apache-storm-1.0.1/lib/minlog-1.3.0.jar:/opt/apache-storm-1.0.1/lib/asm-5.0.3.jar:/opt/apache-storm-1.0.1/conf org.apache.storm.utils.VersionInfo
Storm 1.0.1
URL https://git-wip-us.apache.org/repos/asf/storm.git -r b5c16f919ad4099e6fb25f1095c9af8b64ac9f91
Branch (no branch)
Compiled by tgoetz on 2016-04-29T20:44Z
From source with checksum 1aea9df01b9181773125826339b9587e
安装streamparse
pip3 install streamparse
即然是一个python库就会有各种安装方法,这是一个安装包的位置,上面还有一个wordcount的例子。
由于使用pip安装可能会需要libffi等系统依赖(也可以先安装这些系统依赖)
yum install libffi-devel
如果提示“致命错误:openssl/opensslv.h:没有那个文件或目录”,可参考:作者yum info openssl发现,openssl已经安装过了,怎么还是会缺少openssl.c的文件呢?openssl是已经安装二进制的可执行程序,而这里的安装scrapy则需要的是openssl的源文件程序,比如openssl.h。故这里需要补充安装的是openssh.h的开发版,其中包含相关的安装源代码文件。在确认了问题之后,接下来就是安装openssl-devel的安装包了:yum install openssl-deve
由于我的系统上有两个版本的python,系统默认是较低版本,自己安装的是python3.5,spark中已经设置默认指向python3.5,strom中如何设置还要研究。但是个人觉得streamparse即是python的一个库,同时又有点独立应用的感觉(就是可以自己单独运行,像spark下的pyspark一样)。故而如果我将streamparse安装在python3.5下,同时将streamparse路径添加到环境变量。启动streamparse应该就是使用python3.5环境来运行了。
安装完streamparse后会在对应版本python的bin目录下产生以下几个文件
/usr/local/python35/bin/sparse
/usr/local/python35/bin/streamparse
/usr/local/python35/bin/streamparse_run
如果bin目录不在系统路径中,那么应该把sparse 或streamparse_run(链接到linux shell可以识别的地方我把streamparse也链接过去了)。后面我们就可以在shell里通过sparse来运行相关程序的。
Your First Project
lein安装好,streamparse安装好,strom安装并启动(nimbus和supervisor都要启动)后,就可以启动streamparse来运行我们的程序了。
创建项目文件
运行
sparse quickstart wordcount
这是streamparse团队编的一个例子,运行后会自动在当前目录产生一个wordcount目录,内含
wordcount/.gitignore
wordcount/config.json
wordcount/fabfile.py
wordcount/project.clj
wordcount/README.md
wordcount/src
wordcount/src/bolts
wordcount/src/bolts/__init__.py
wordcount/src/bolts/wordcount.py
wordcount/src/spouts
wordcount/src/spouts/__init__.py
wordcount/src/spouts/words.py
wordcount/topologies
wordcount/topologies/wordcount.py
wordcount/virtualenvs
wordcount/virtualenvs/wordcount.txt
其实就是创建了一个python语言的storm项目,内含config.json等配置文件,拓扑的定义文件,spouts的定义文件等。
运行本地拓扑
先修改项目配置文件,配置config.json如下:
{
"serializer": "json",
"topology_specs": "topologies/",
"virtualenv_specs": "virtualenvs/",
"envs": {
"prod": {
"user": "digger",
"ssh_password": "",
"nimbus": "localhost",
"workers": ["localhost"],
"log": {
"path": "",
"max_bytes": 1000000,
"backup_count": 10,
"level": "info"
},
"virtualenv_root": "~/tmp/wordcount/virtualenvs"
}
}
}
应该是只是nimbus和workers地址设置比较重要。
cd wordcount
sparse run
需要跑到项目下运行,可能是以config.json的位置为参考;这个应该是可以设置的吧,要不运行起来太不灵活了。不过运行过程会自动将相关程序打包成jar文件,个人感觉这个jar文件才是关键,然后这个jar被提交的storm.
如果碰到下面这样的错误
ValueError: Local Storm version, 1.2.2, is not the same as the version in your project.clj, 1.1.0. The versions must match.
就要修改wordcount/project.clj文件,以及更换对应版本的storm.
我是仅修改了project.clj文件对应strom版本号,没有重新安装storm。
如果碰到下面的错误
Caused by: java.io.IOException: Cannot run program "streamparse_run" (in directory "/tmp/b5e287fa-4eba-4097-a8d5-22e2a4911694/supervisor/stormdist/wordcount-1-1540393384/resources"): error=2, 没有那个文件或目录
那可能是linux系统不认识streamparse_run,应该像sparse命令一样,添加到shell可以识别的路径。
机器会花一定时间来编译JAR文件,然后就能看到实时流的输出了。
除了编译还会运行一大堆的东西,包括各种文件的复制。最终持续进行中的状态是类似下的输出内容不断滚动
102540 [Thread-29] INFO o.a.s.t.ShellBolt - ShellLog pid:61460, name:count_bolt 2018-10-25 00:05:23,417 - pystorm.component.count_bolt - counted [360,000] words [pid=61460]
103257 [Thread-29] INFO o.a.s.t.ShellBolt - ShellLog pid:61460, name:count_bolt 2018-10-25 00:05:24,135 - pystorm.component.count_bolt - counted [363,000] words [pid=61460]
103914 [Thread-29] INFO o.a.s.t.ShellBolt - ShellLog pid:61460, name:count_bolt 2018-10-25 00:05:24,791 - pystorm.component.count_bolt - counted [366,000] words [pid=61460]
104643 [Thread-29] INFO o.a.s.t.ShellBolt - ShellLog pid:61460, name:count_bolt 2018-10-25 00:05:25,521 - pystorm.component.count_bolt - counted [369,000] words [pid=61460]
这个快速上手教程提供了一个简单的拓扑例子,可以进一步查看和修改。
更多命令
如果想要看sparse有哪些命令,可以sparse -h,具体的命令如下:
jar Create a deployable JAR for a topology.
kill Kill the specified Storm topology
list List the currently running Storm topologies
quickstart Create new streamparse project template.
remove_logs Remove logs from Storm workers.
run Run the local topology with the given arguments
slot_usage Display slots used by every topology on the cluster.
stats Display stats about running Storm topologies.
submit Submit a Storm topology to Nimbus.
tail Tail logs for specified Storm topology.
update_virtualenv Create or update a virtualenv on Storm workers.
visualize Create a Graphviz visualization of the topology
worker_uptime Display uptime for Storm workers.
help Print help information about other commands.
项目结构
| File/Folder | Contents |
|---|---|
| config.json | Configuration information for all of your topologies. |
| fabfile.py | Optional custom fabric tasks. |
| project.clj | leiningen project file (can be used to add external JVM dependencies). |
| src/ | Python source files (bolts/spouts/etc.) for topologies. |
| tasks.py | Optional custom invoke tasks. |
| topologies/ | Contains topology definitions written using the Topology DSL. |
| virtualenvs/ | Contains pip requirements files used to install dependencies on remote Storm servers. |
定义拓扑结构
storm是基于shift框架的,可以用纯python语言来定义拓扑结构。
下面是例子中的拓扑结构
"""
Word count topology
"""
from streamparse import Grouping, Topology
from bolts.wordcount import WordCountBolt
from spouts.words import WordSpout
class WordCount(Topology):
word_spout = WordSpout.spec()
count_bolt = WordCountBolt.spec(inputs={word_spout: Grouping.fields('word')},
par=2)
count_bolt 告诉storm,输入的元组是按单词作为域进行路由。storm提供了丰富的路由方式可供选择,用得最多的是随机分配和按域分配。
Spouts 和 Bolts
一般用streamparse 创建Spouts 和 Bolts的方式是将两类文件加入项目下的src文件夹,并更新拓扑文件。
下面是定义发送句子的spout 。
import itertools
from streamparse.spout import Spout
class SentenceSpout(Spout):
outputs = ['sentence']
def initialize(self, stormconf, context):
self.sentences = [
"She advised him to take a long holiday, so he immediately quit work and took a trip around the world",
"I was very glad to get a present from her",
"He will be here in half an hour",
"She saw him eating a sandwich",
]
self.sentences = itertools.cycle(self.sentences)
def next_tuple(self):
sentence = next(self.sentences)
self.emit([sentence])
def ack(self, tup_id):
pass # if a tuple is processed properly, do nothing
def fail(self, tup_id):
pass # if a tuple fails to process, do nothing
一旦spout 进入主程序,streamparse 就是调用initialize() 方法,初始化完成后streamparse就会不断地调用next_tuple()方法。在这个函数中会不断发送元组,而通过拓扑的设置,对应的bolt就能接收到这些元组。
下面是一个bolt 的例子,它接收句子,并将它拆分成单词。
import re
from streamparse.bolt import Bolt
class SentenceSplitterBolt(Bolt):
outputs = ['word']
def process(self, tup):
sentence = tup.values[0] # extract the sentence
sentence = re.sub(r"[,.;!\?]", "", sentence) # get rid of punctuation
words = [[word.strip()] for word in sentence.split(" ") if word.strip()]
if not words:
# no words to process in the sentence, fail the tuple
self.fail(tup)
return
for word in words:
self.emit([word])
# tuple acknowledgement is handled automatically
bolt 执行的操作更简单,这里只是简单的覆盖process()方法,当由spout 或其他bolt发送的输入流到达的时候streamparse 就会调用process()方法来进行相应处理。在这里你可以定义自己的处理逻辑,并将结果发送给下游。
如果调用process()时发生意外,那么streamparse 会先丢掉当前元组信息,然后再杀死python进程。
Failed Tuples
Bolt Configuration Options
Handling Tick Tuples
如何接收外部数据输入和输出数据到外部系统
Spouts 和 Bolts是我们数据处理的核心。但是之前介绍Spouts都是手动制造的数据 ,而介绍Bolt时只介绍了一个简单的数据处理方式和发送机制,并没有真正发送到外部系统(默认是到标准输出用屏幕打印?)
外部数据输入
streamparse/examples/kafka-jvm/ :
这是一个混合了java和python例子,数据输入部分是用java从kafka读取数据实现的spout,数据输出是由python写的bolt实现。
PixelSpout.java
package pixelcount.spouts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import backtype.storm.spout.SchemeAsMultiScheme;
public class PixelSpout extends KafkaSpout {
public PixelSpout(SpoutConfig spoutConf) {
super(spoutConf);
}
public PixelSpout() {
this(PixelSpout.defaultSpoutConfig());
}
public static SpoutConfig defaultSpoutConfig() {
ZkHosts hosts = new ZkHosts("streamparse-box:2181", "/brokers");
SpoutConfig spoutConf = new SpoutConfig(hosts, "pixels", "/kafka_storm", "pixel_reader");
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
spoutConf.forceFromStart = true;
return spoutConf;
}
}
如何运行在python环境:
第一种方法是把这个java写的spout当成一个后续数据接入的配置文件,我们只要修改里面kafka相关的内容,就可以实现不同场景的移植。这样即使我不会java我也可以完成自己的项目。
第二种方法是用python重写,spout的结构我们是知道的,用python写的spout的也见过,只是之前是自己造的数据源;如果直接在spout.py文件中读入kafka数据,并处理这些数据,处理结果给spout的相关接口,应该也是可以。有时间可以试一下。
整个用streamparse操作storm跟用pyspark-streaming处理流式数据很像,程序都要提交给一个框架。
结果给出的外部系统
streamparse/examples/redis/
这个例子输入spout是手动产生的数据,最终结果则是输出到redis.
from collections import Counter
from redis import StrictRedis
from streamparse import Bolt
class WordCountBolt(Bolt):
outputs = ['word', 'count']
def initialize(self, conf, ctx):
self.counter = Counter()
self.total = 0
def _increment(self, word, inc_by):
self.counter[word] += inc_by
self.total += inc_by
def process(self, tup):
word = tup.values[0]
self._increment(word, 10 if word == "dog" else 1)
if self.total % 1000 == 0:
self.logger.info("counted %i words", self.total)
self.emit([word, self.counter[word]])
class RedisWordCountBolt(Bolt):
outputs = ['word', 'count']
def initialize(self, conf, ctx):
self.redis = StrictRedis()
self.total = 0
def _increment(self, word, inc_by):
self.total += inc_by
return self.redis.zincrby("words", word, inc_by)
def process(self, tup):
word = tup.values[0]
count = self._increment(word, 10 if word == "dog" else 1)
if self.total % 1000 == 0:
self.logger.info("counted %i words", self.total)
self.emit([word, count])
其中的initialize()和_increment()函数就是定义数据输出到redis的。process()是数据处理过程。
Remote Deployment
Setting up a Storm Cluster
Submit
Disabling & Configuring Virtualenv Creation
Using unofficial versions of Storm
Local Clusters
Setting Submit Options in config.json
Logging
其他资料:
从零开始学Storm