hadoop2.7.1在vmware上3台centos7虚拟机上的完全分布式集群搭建
- 集群架构
- centos7的安装
- 安装java
- hadoop全分布
- ssh无密码登录
- hadoop集群正常启动测试
以下内容均属个人理解,如有偏差,望大家谅解。
集群架构
3台虚拟机都在同一个局域网中,网段是192.168.10.0,子网掩码是:255.255.255.0。
主节点:master.hadoop 192.168.10.2 namenode,SecondaryNamenode,Resource
NameNode
从节点:slavea.hadoop 192.168.10.3 datanode,nodemanage
从节点:slaveb.hadoop 192.168.10.4 datanode,nodemanage
centos7的安装
注意事项:网络选项为桥接。
桥接是将虚拟机当成物理机连接外网。和我们的物理主机在同一个局域网内。需要修改/etc/sysconfig/network-scripts/ifcfg-eno16777736,具体修改BOOTPROTO=static。
NAT是将虚拟机与物理主机隔开,但虚拟机仍可通过NAT服务上网,但是物理主机Ping不到虚拟机,同时,VMnet8的ip是网关。
以主节点为例
创建hadoop账户,以hadoop账户登录。
关闭防火墙:因为防火墙会限制端口的开放。
Linux命令(centos最原始的防火墙是firewall。iptables服务是最新的)是:
firewall-cmd –state 查询防火墙状态
systemctl stop firewalld.service 关闭防火墙
systemctl disable firewalld.service 禁止firewall开机启动
关闭SELinux服务:SELinux是对系统文件权限的控制。
Linux命令:
禁止SELinux开机启动
sudo vi /etc/sysconfig/selinux
将”SELINUX=enforcing”改成”SELINUX=disabled”,保存退出
关闭SELinux服务
sudo setenforce 0
查询SELinux服务的状态
sudo getenforce
为Permissive则可。
修改主机名
1.修改/etc/hosts(主机与ip的映射文件) 在原有的基础上加上
192.168.10.2 master.hadoop
2.修改/etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=master.hadoop
可以用echo $hostname测试一下
修改ip
修改/etc/sysconfig/network-script/ifcfg-eno16777736,修改或添加以下内容(以下内容有关ip部分根据自己情况填写):
BOOTPROTO=static
ONBOOT=yes
GATEWAY=192.168.10.1
IPADDR=192.168.10.2
NETMASK=255.255.255.0
DNS1=202.117.112.3
安装java
java 安装包 jdk-8u65-linux-x64.tar.gz
1.解压到/usr/java目录下得到jdk1.8.0_65,tar -zxvf jdk-8u65-linux-x64.tar.gz -C /usr/java/。
2.配置环境:
修改/etc/profile文件,添加以下内容:
#set java enviroment
export JAVA_HOME=/usr/java/jdk1.8.0_65
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATHsource /etc/profile来即时更新bash的环境。
判断jdk配置是否成功:
java -version
java version "1.8.0_65"
Java(TM) SE Runtime Environment (build 1.8.0_65-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.65-b01, mixed mode)
得到这个即表示配置成功。
hadoop全分布
1.下载解压hadoop-2.7.1.tar.gz到/usr/hadoop。
2.将hadoop目录的拥有权限设置成hadoop账户。
3.修改/etc/profile,添加以下内容:
#set HADOOP
HADOOP_PREFIX=/usr/hadoop
export HADOOP_PREFIX
export PATH=$PATH:$HADOOP_PREFIX/sbin
4.修改/etc/hadoop/mapred-env.sh,添加以下内容:
export JAVA_HOME=/usr/java/jdk1.8.0_655.在/usr/hadoop下创建目录tmp,用于存放hdfs的相关数据。
6.修改配置文件:
1)/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://192.168.10.2:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:///usr/hadoop/tmpvalue>
property>
configuration>
2) /etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///usr/hadoop/tmp/dfsnamenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///usr/hadoop/tmp/dfsdatanodevalue>
property>
<property>
<name>dfs.blocksizename>
<value>268435456value>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.handle.countname>
<value>100value>
property>
<property>
<name>dfs.datanode.http.addressname>
<value>0.0.0.0:50076value>
property>
configuration>3) /etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
4) /etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.log-aggregation-enable name>
<value>falsevalue>
property>
<property>
<name>yarn.resourcemanager.address name>
<value>192.168.10.2:8032value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>master.hadoopvalue>
property>
configuration>5)修改/etc/hadoop/slaves文件,来告知主节点有哪两个子节点
slavea.hadoop
slaveb.hadoop主机配置告一段落。
其余两子节点
1.利用vmware的克隆功能,克隆跟主节点一模一样的两个子节点。
2.修改ip,将两台子节点ip改为192.168.10.3,192.168.10.4。
3.修改主机名,将两台子节点主机名改为:slavea.hadoop,slaveb.hadoop。
ssh无密码登录
1.修改/etc/hosts ,在原有的基础上分别添加另外两台主机ip映射关系,三台虚拟机统一内容为:
27.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
192.168.10.2 master.hadoop
192.168.10.3 slavea.hadoop
192.168.10.4 slaveb.hadoop2.对master.hadoop节点的hadoop用户使用如下命令生成密钥对:
ssh-keygen -t rsa -P ''在/home/hadoop/.ssh目录下生成id_rsa和id_rsa.pub。
3.将公钥id_rsa.pub追加到授权的key中:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys4.修改authorized_keys的权限:
chmod 600 ~/.ssh/authorized_keys5.ssh localhost 若无密码登录,则设置成功。
6.将authorized_keys文件以及id_rsa文件用scp命令分别复制到其他2个节点,即可实现节点之间免密码登录了。。
//复制到slava.hadoop的目录下,复制到slaveb.hadoop目录命令类似
scp ~/.ssh/authorized_keys slavea.hadoop@192.168.10.3:~/.ssh
scp ~/.ssh/id_rsa slavea.hadoop@192.168.10.3:~/.sshhadoop集群正常启动测试
1.首先需要格式化一下namenode。
$HADOOP_PREFIX/bin/hdfs namenode -format
2.启动所有的进程服务。
start-all.sh
3.用jps命令查看一下所有的服务进程是否启动。
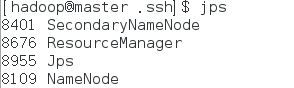
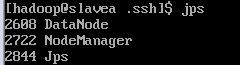

4.可以通过网页查看集群运行情况:
http://192.168.10.2:50070 namenode information
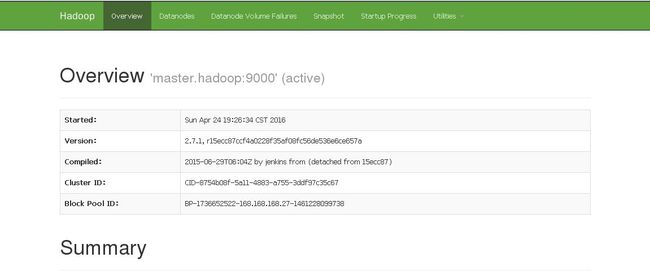
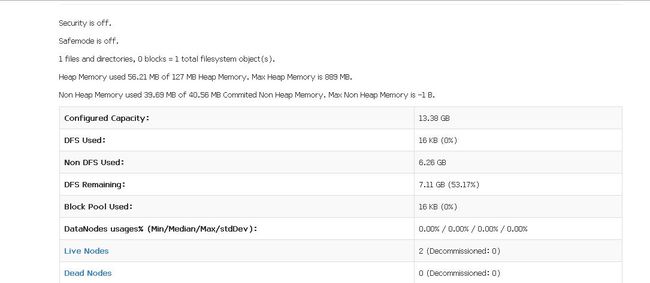
http://192.168.10.2:8088 ResourceManager information

5.关闭集群
stop-all.sh