管理员解决深度学习服务器GPU内存占用问题
问题

解决方法
利用Linux自带的管道命令
nvidia-smi | grep python
获取到GPU中的进程号
然后通过
ps -lA | grep pid
找到进程的状态
若为S(sleep),并且超过容忍时间,则kill掉
测试python执行centos7系统命令的情况
import os
gpu_status = os.popen("nvidia-smi | grep python").readlines()
gpu_status
['| 0 27523 C python 399MiB |\n',
'| 0 31299 C python 10371MiB |\n']
for status in gpu_status:
id = status.split()[2]
processes = os.popen("ps -lA | grep {}".format(id)).readlines()
print("ps lA->",processes)
for p in processes:
p = p.split()
print(p[3],id)
if p[3] == id:
print("find->",p)
if p[1] == 'S':
# 这里需要管理员来运行,状态码为0则执行成功
print("kill",os.system("kill -9 {}".format(id)))
# os.system("kill -9 {}".format(id))
ps lA-> ['0 S 1002 27523 28715 0 80 0 - 4709685 ep_pol ? 00:02:31 python\n']
27523 27523
find-> ['0', 'S', '1002', '27523', '28715', '0', '80', '0', '-', '4709685', 'ep_pol', '?', '00:02:31', 'python']
kill 256
ps lA-> ['0 S 1002 31299 28715 0 80 0 - 7749808 ep_pol ? 00:07:22 python\n']
31299 31299
find-> ['0', 'S', '1002', '31299', '28715', '0', '80', '0', '-', '7749808', 'ep_pol', '?', '00:07:22', 'python']
kill 256
测试python3的写法
实际使用中,因为管理员自带的是python2,所以还需要改成python2的代码
import os
import time
record = [0]*100000 # 用于记录进程睡眠次数 pid的最大值默认是32767
while True:
time.sleep(1)
gpu_status = os.popen("nvidia-smi | grep python").readlines()
for status in gpu_status:
id = status.split()[2]
processes = os.popen("ps -lA | grep {}".format(id)).readlines()
for p in processes:
p = p.split()
if p[3] == id:
if p[1] == 'S':
record[int(id)] += 1
if record[int(id)] >= 60:
'''若进程超过60秒出于sleep状态将被kill掉'''
# print("s",id,os.system("kill -9 {}".format(id)))
os.system("kill -9 {}".format(id))
else:
record[int(id)] = 0
实际部署到服务器的代码
这里用python2写了一个死循环,可以配合Linux的screen命令或者是nohup &命令来执行这个程序
# -*- coding:utf-8 -*-
import os
import time
record = [0]*100000 # 用于记录进程睡眠次数
while True:
time.sleep(1)
gpu_status = os.popen("nvidia-smi | grep python").readlines()
for status in gpu_status:
id = status.split()[2]
processes = os.popen("ps -lA | grep {}".format(id)).readlines()
for p in processes:
p = p.split()
if p[3] == id:
'''
根据ps -lA命令的位置,得找到对应的PID位置
'''
if p[1] == 'S':
record[int(id)] += 1
print id,"已经睡眠了",record[int(id)],"次"
if record[int(id)] >= 300 :
'''若进程超过300秒出于sleep状态将被kill掉'''
print "kill->",id,os.system("kill -9 {}".format(id))
else:
'''
好好跑程序就清空惩罚
'''
print id,"正在GPU中运行"
record[int(id)] = 0
测试效果
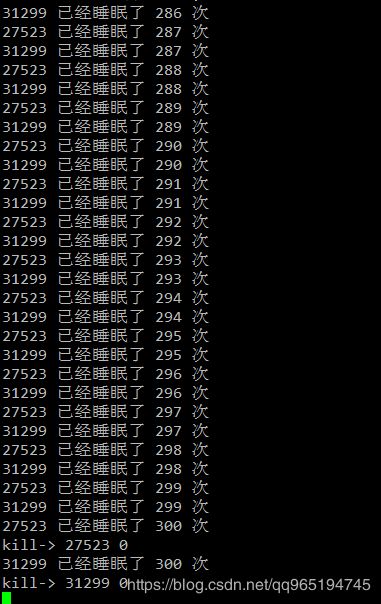
可以看到,如果连续睡眠超过300秒,将被kill掉

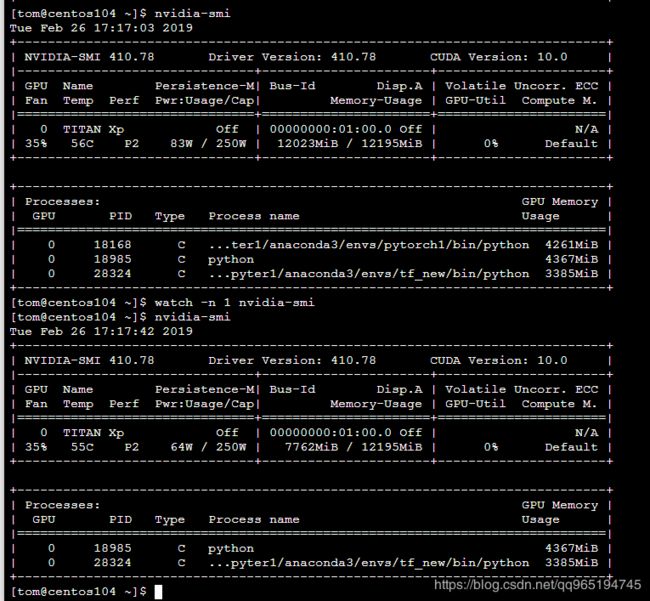
有用的参考
https://blog.csdn.net/kwsy2008/article/details/50906935
https://www.jb51.net/article/103092.htm