网络编程
以前做的服务器项目偏重业务层,网络通信调用的网络组编写的库,因此不太熟悉,现在补充一下。
网络通信本质属于一种远程进程间通信。
1 目的
目前服务端开源的io库非常多,不需要都掌握。
重在掌握基本概念与基本原理,具体技术细节可以逐步学习。
2 基础知识复习
2.1 进程间通信(IPC,InterProcess Communication)
本地进程间通信:(掌握消息队列和共享内存吧,太多也记不住)
1)管道:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程之间使用。进程的亲缘关系通常是指父子进程关系。
2)有名管道(FIFO):有名管道也是半双工的通信方式,但是允许在没有亲缘关系的进程之间使用,管道是先进先出的通信方式。
3)信号量:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
4)消息队列:消息队列是有消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
5)信号 ( sinal ) :信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
6)共享内存( shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。
远程(不同机器):Socket
https://www.cnblogs.com/CheeseZH/p/5264465.html
都分为 创建-读/写-关闭 几个步骤。比如共享内存的例子:
https://www.cnblogs.com/youngerchina/p/5624525.html
通过共享内存的指针来读写操作
//创建共享内存
shmid = shmget((key_t)1234, sizeof(struct shared_use_st), 0666|IPC_CREAT); //sizeof(struct shared_use_st)指定共享内存大小,struct shared_use_st为一个预先定义好的结构体
//将共享内存连接到当前进程的地址空间
shm = shmat(shmid, 0, 0);
//设置共享内存指针
struct shared_use_st *shared = (struct shared_use_st*)shm;
//读取共享内存中的数据
printf("You wrote: %s", shared->text);
//把共享内存从当前进程中分离
shmdt(shm);
//删除共享内存
shmctl(shmid, IPC_RMID, 0);2.2 TCP UDP定义及区别:
1)TCP提供面向连接的传输,通信前要先建立连接(三次握手机制),因此提供可靠的传输。
UDP提供无连接的传输,通信前不需要建立连接,因此提供不可靠的传输。。
2)TCP**面向字节流的传输,因此它能将信息分割成组,并在接收端将其重组;UDP是面向数据报**的传输,没有分组开销。
2.3 TCP UDP的优缺点
tcp可靠,但占用资源多。
udp不可靠,但占用资源少。在大量短消息、对信息安全要求不高或网络比较阻塞时适用。
2.4 TCP三次握手、四次挥手
三次握手:
首先Client端发送连接请求报文。
Server段接受连接后回复ACK报文,并为这次连接分配资源。
Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。
四次挥手:
假设Client端发起中断连接请求,也就是发送FIN报文。
Server端接到FIN报文后,意思是说”我Client端没有数据要发给你了”,但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK。
当Server端确定数据已发送完成,则向Client端发送FIN报文,”告诉Client端,好了,我这边数据发完了,准备好关闭连接了”。
Client端收到FIN报文后,发送ACK,Server端收到ACK后,”就知道可以断开连接了”。
2.5 基于Socket的TCP UDP区别
从下图中可以看出udp相比tcp没有listen()、connect()、Accept()函数(这几个函数用来建立连接)

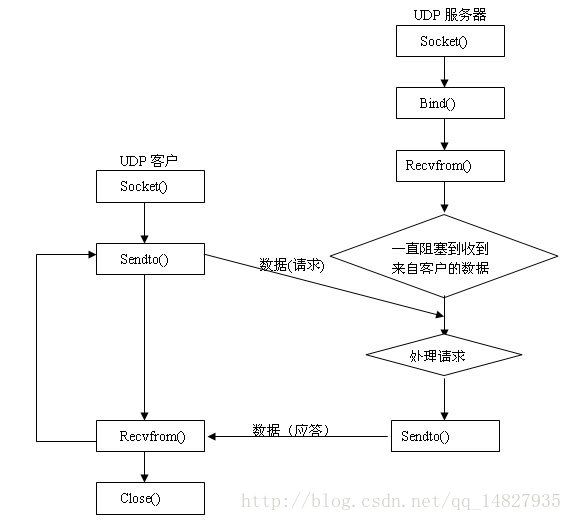
常用的Socket类型有两种:流式Socket(SOCK_STREAM)、服务于TCP和数据报式Socket(SOCK_DGRAM)、UDP。
2.6 基于TCP/Socket自定义应用层协议
通过Socket传输的数据可以分为:包头+数据正文。
包头里面可以包含:
服务器IP、端口;
数据正文长度(告诉服务器接收多长的数据正文);
同步码(区分每一个有效的数据包,告诉服务器从哪边开始接收)
校验位(证明接收的数据是无误的)
数据包类型,可以指定数据包用来的目的
2.7 长连接、短连接、异步双工
http://blog.csdn.net/mazy1226/article/details/21220307
长连接是整个通讯过程,客户端和服务端只用一个Socket对象,长期保持Socket的连接;短连接是每次请求,都新建一个Socket,处理完一个请求就直接关闭掉Socket。
3 网络io四种模型:同步异步、阻塞非阻塞
https://www.cnblogs.com/Anker/p/3254269.html
http://blog.csdn.net/zh13544539220/article/details/44856363
这两个帖子写的很具体了,对照着看。
个人理解分为四种:
最后,再举几个不是很恰当的例子来说明这四个IO Model:
有A,B,C,D四个人在钓鱼(服务器等待接收数据):
A用的是最老式的鱼竿,所以呢,得一直守着,等到鱼上钩了再拉杆;(阻塞io)
B的鱼竿有个功能,能够显示是否有鱼上钩,所以呢,B就和旁边的MM聊天,不断地主动看看有没有鱼上钩,有的话就迅速拉杆(非阻塞io);
C用的鱼竿和B差不多,但他想了一个好办法,就是同时放好几根鱼竿,然后守在旁边,一旦有显示说鱼上钩了,它就将对应的鱼竿拉起来(不断的轮询所负责的所有socket,IO多路复用);
D是个有钱人,干脆雇了一个人帮他钓鱼,一旦那个人把鱼钓上来了,就给D发个短信(异步io)。
其中,由于异步io信号个数有限,多个描述符时不适用。较常用的是IO多路复用。
4 epoll与select的区别
4.1 问题的引出
当需要读两个以上的I/O的时候,如果使用阻塞式的I/O,那么可能长时间的阻塞在一个描述符上面,另外的描述符虽然有数据但是不能读出来,这样实时性不能满足要求,大概的解决方案有以下几种:
1.使用多进程或者多线程,但是这种方法会造成程序的复杂,而且对与进程与线程的创建维护也需要很多的开销。(Apache服务器是用的子进程的方式,优点可以隔离用户)
2.用一个进程,但是使用非阻塞的I/O读取数据,当一个I/O不可读的时候立刻返回,检查下一个是否可读,这种形式的循环为轮询(polling),这种方法比较浪费CPU时间,因为大多数时间是不可读,但是仍花费时间不断反复执行read系统调用。
3.异步I/O(asynchronous I/O),当一个描述符准备好的时候用一个信号告诉进程,但是由于信号个数有限,多个描述符时不适用。
4.一种较好的方式为I/O多路转接(I/O multiplexing)(貌似也翻译多路复用),先构造一张有关描述符的列表(epoll中为队列),然后调用一个函数,直到这些描述符中的一个准备好时才返回,返回时告诉进程哪些I/O就绪。select和epoll这两个机制都是多路I/O机制的解决方案,select是POSIX标准中的,一般操作系统均有实现。而epoll为Linux所特有的。
个人理解就是主流的分两种,阻塞式io+多线程/多进程、io多路复用。
4.2 select poll epoll三者的区别
https://www.cnblogs.com/jeakeven/p/5435916.html
个人理解就是:
select是windows、linux都有的,epoll是linux特有的。
select一般只支持1024个连接,poll没有限制,epoll可以支持十万级的连接。
select、poll都是进程主动轮询,随着fd的增加,轮询耗时较大。而epoll是操作系统主动通知我。
最起码掌握select、epoll。
4.3 select的例子
http://blog.csdn.net/timmiy/article/details/52123755
http://blog.csdn.net/leo115/article/details/8097143
简单的说,
我们在TCP的服务端里边,接收一个客户端的时候,我们调用accept函数,这个函数会返回一个客户端的socket,我们在主线程里边不停的接收客户的连接,每当有客户连接时,我们就会在开一个线程(因为recv操作是阻塞的,很耗时),用于对客户的服务。因此,如果有N个的客户进行连接的话,那么线程数量就会有N+1个(N个服务线程+主线程),若N比较大,则线程就会非常多,以至于将整个电脑都给拖垮掉。而我们的select模型呢,就是为了解决这个问题而设计的。接下来看下它是如何实现的。
服务端accept()后获得一个客户端的socket,把所有客户端的socket放入数组中,然后select函数去轮询获得数组中哪一个socket有数据来,然后对那一个socket调用recv函数。
4.4 epoll的例子
https://www.cnblogs.com/thrillerz/articles/4473970.html
http://blog.csdn.net/hnlyyk/article/details/48974749
个人理解就是,如果服务端socket有事件,代表有客户端连接,则accept后获得客户端的socket,把它加入epoll队列;如果客户端socket有事件,则对该客户端socket进行read/write操作。
4.5 完成端口(IOCP)
个人理解就是,
windows服务端的。
说白了 IOCP 就是一个消息队列。我们设想一下,如果事先开好 N 个线程,让它们 hold 住,将所有用户的请求都投递到一个消息队列中去。然后这 N 个线程逐一从消息队列中去取出消息并加以处理。这样一来,就可以避免对每个用户请求都开新线程,不仅减少了线程的资源,也提高了线程的利用率。
5 one loop per thread思想
服务器有很多线程。每个线程的结构都是一样的,都包含一个固定的循环。
这个循环包含三个主要步骤: 第一步:io多路复用 第二步:读写数据 第三步:解包

有时候还包含定时器事件,更加详细的步骤如下:

6 网络设计模式Reactor 和 Proactor
http://blog.csdn.net/llj1985/article/details/51558584
https://segmentfault.com/a/1190000002715832
http://blog.csdn.net/u013074465/article/details/46276967
个人理解就是:
reactor、proactor是网络编程的两种典型的设计模式。可以看做是在select、epoll函数基础上基于事件-通知机制封装了一层。
reactor即反应堆模式,proactor即主动器模式。
reactor即当io有读写事件时,通知应用程序,应用程序自己实现读写以及数据处理操作。而proactor即由内核异步读写,读写完后事件通知应用程序,由应用程序实现数据处理操作。
reactor模式的经典开源网络库如libevent,ace。proactor模式的如Boost.Asio,ace。整体看,reactor用的更多一些。
7 并发服务器技术选型
https://www.cnblogs.com/my_life/articles/5333436.html
个人理解,高并发的技术选型都是reactor模式和threads或者threadpool结合的产物。
8 开源网络库学习
8.1 经典开源io:thrift
http://blog.csdn.net/sunmenggmail/article/details/46818147
掌握原理以后,理解各类开源库就简单多了。
TSimpleServer模式是阻塞式io。 TThreadPoolServer模式是阻塞式io+多线程(线程池),其缺点是当并发请求数大于线程池中的线程数时。
TNonblockingServer模式是io多路复用,其缺点是业务处理耗时。因此出现 THsHaServer模式,也是io多路复用,将业务处理过程交由一个线程池来完成,其缺点是当并发请求数较大时,且发送数据量较多时,监听socket上新连接请求不能被及时接受。因此出现TThreadedSelectorServer模式,个人理解也是io多路复用,优点更多。
8.2 经典的开源io库:libevent
http://www.cnblogs.com/xiehongfeng100/p/4686221.html
https://www.cnblogs.com/nearmeng/p/4043548.html
个人理解如下:
该库由C语言编写,跨平台,相对权威,网络库。
该库基于Reactor设计模式,封装了epoll等底层API。
基本的使用流程可以参考epoll的流程。
8.3 经典的开源io:asio
netty,nginx一类。