高性能MySQL之Count统计查询
近一段时间,有同事问我 “MySQL执行count很慢,有没有什么优化的空间”。当时在忙,就回复了一句“innodb里面count统计都是实时统计,慢一些是正常的”, 周末闲暇下来,想到以前有好多人都问过关于count的问题,今天就聊聊MySQL之Count查询。
关于MySQL的count查询,很多人都会有疑问,同样在大表中执行 ,有些速度基本不耗时,有些又慢的要死。关于这些问题在《高性能MySQL》这本书中第6.7.1章节有如下相关解释:
COUNT()聚合函数,以及如何优化使用了该函数的查询,很可能是MySQL中最容易被误解的前10个话题之一,在网上随便搜索一下就能看到很多错误的理解,可能比我们想象的多得多。
在做优化之前,先来看看COUNT()函数的真正作用是什么。
COUNT()的作用
COUNT()是一个特殊的函数,有两种非常不同的作用:它可以统计某个列值的数量,也可以统计行数。在统计列值时要求列值非空的(不统计NULL)。如果在COUNT()的括号中指定了列或列的表达式,统计的就是这个表达式有值的结果数。因为很多人对NULL理解有问题,所以这里很容易产生误解。如果想了解更多关于SQL语句中NULL的含义,建议阅读一些关于SQL语句基础的书籍。(关于这个话题,互联网上的一些信息是不够精确的)
COUNT()的另外一个作用是统计结果集的行数。当mysql确认括号内的表达式值不可能为空时,实际上就是在统计行数。最简单的就是当我们使用COUNT(*)的时候,这种情况下通配符*并不会像我们猜想的那样扩展成所有的列,实际上,它会忽略所有的列而直接统计所有的行数。
我们发现一个最常见的错误就是,在括号内指定了一个列却希望统计结果集的行数。如果希望知道的是结果集的行数,最好使用COUNT(*),这样写意义清晰,性能也会很好。
于MyISAM的神话
一个容易产生的误解就是:MyISAM的COUNT()函数总是非常快,不过这是有前提条件的,即只有没有任何where条件的COUNT(*)才非常快,因为此时无需实际地去计算表的行数。MySQL可以利用存储引擎的特性直接获得这个值。如果MySQL知道某列col不可能为NULL值,那么MySQL内部会将COUNT(col)表达式优化为COUNT(*)。
当统计带WHERE子句的结果集行数,可以是统计某个列值的数量时,MySQL的COUNT()和其它存储引擎没有任何不同,就不再有神话般的速度了。所以在MyISAM引擎表上执行COUNT()有时候比别的引擎快,有时候比别的引擎慢,这受很多因素影响,要视具体情况而定。
《高性能MySQL》这本书只介绍了MyISAM存储引擎在count上的误区以及在MyISAM存储引擎上的count优化,而对于常用的innodb执行Count没有做过多讲解,下面我们就聊聊如何在Innodb上进行count优化。
Innodb存储引擎:
(1) innodb存储引擎的物理结构包含 表空间、段、区、页、行 五个层级,数据文件按照主键排序存储在页中(页在逻辑上连续),主键的位置即为数据存储位置。
(2) 二级索引存储的数据为指定字段的值与主键值。当我们通过二级索引统计数据的时候,无需扫描数据文件;而通过主键索引统计数据时,由于主键索引与数据文件存放在一起,所以每次都会扫描数据文件,故大多数情况下,通过二级索引统计数据效率 >= 基于主键统计效率。
(3) 由于二级索引存储的数据为指定字段的值与主键值,故在无索引覆盖的情况下,查询二级索引后会根据二级索引获取的主键到主键索引中提取数据,此过程可能造成大量的随机io,导致查询速度较慢。
(4) 由于主键索引与数据存储保持一致,故基于主键的查找数据要比通过二级索引查询数据要快(使用二级索引时,查询到的数据条数>总条数的20%时候mysql就选择全表扫描,但在主键索引上,即使符合条件的达到 90%依然会走索引)。
count慢的原因:
innodb为聚簇索引同时支持事物,其在count指令实现上采用实时统计方式。在无可用的二级索引情况下,执行count会使MySQL扫描全表数据,当数据中存在大字段或字段较多时候,其效率非常低下(每个页只能包含较少的数据条数,需要访问的物理页较多)。
innodb可优化点:
1. 主键需要采用占用空间尽量小的类型且数据具有连续性(推荐自增整形id),这样有利于减少页分裂、页内数据移动,可加快插入速度同时有利于增加二级索引密度(一个数据页上可以存储更多的数据)。
2.在表包含大字段或字段较多情况下,若存在count统计需求,可建一个较小字段的二级索引(例 char(1) , tinyint )来进行count统计加速。
下面做个count优化例子:
1.首先我们创建一直innodb表,并包含大字段(或包含较多字段):
CREATE TABLE `qstardbcontent` (
`id` BIGINT(20) NOT NULL DEFAULT '0',
`content` MEDIUMTEXT,
`length` INT(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8
2.插入50万条数据,每条数据 5K
3.执行select count(*) from qstardbcontent
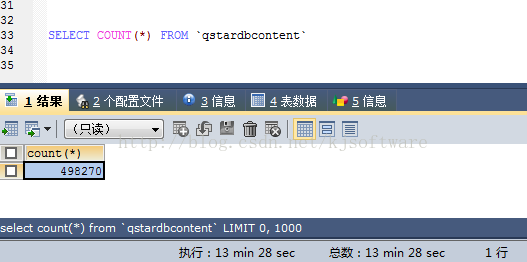
可以看到,近50万条内容较多的数据执行一个count(*) 就需要耗时 13分28秒
下面我们做个优化,在length字段上加个索引, 执行sql: ALTER TABLE qstardbcontent ADD KEY(LENGTH);
索引建完成后,再执行 select count(*) from qstardbcontent;
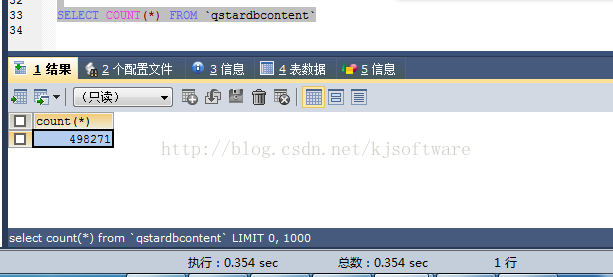
可以看到,整个统计查询非常快,仅用了 354毫秒就完成了查询。
加速原因:
我们在innodb表上创建了一个二级索引,Innodb在执行count(*)时候由优化器选择执行路径。本例中, 二级索引的存储空间仅包含length字段值、数据主键,假设二级索引辅助结构不占用空间(仅计算数据占用空间),在默认情况下,MySQL的一个数据页大小为16K,一个页可存储的数据条数为 16*1024/(4+8) =1365 ,按照单页存储空间占用为50%(页分裂现象导致页不满)计算,50万条数据的统计仅需要读取约732个物理页,而页在连续的情况下,数据库一次可读取多个连续的页,数据读取总量为 16k*732约 12MB,因mysql空间分配为按区分配,每个区1M,一次分配1-5个连续区,当数据量较小,一次仅分配一个区,12M数据会分配在12个区中,按照pc硬盘(转速7200转/分) 70m/s 的读取速度,整个过程的io寻址时间(12*8.5ms=102)+读取时间(12m/70m=171ms)=273ms,而数据解析统计约为 30-100ms,故总耗时会在300ms附近(注:count优化功能在5.1版本并不支持)。