大数据学习——win环境下hadoop安装教程
程序开发往往在win环境下完成,对于需要linux环境的技术栈学习往往借助于虚拟机。
但是在学习和测试hadoop生态技术组件时,这东西是真的很吃内存,本地安装的虚拟机很难提供足够的资源让hadoop平稳运行。
以下记录在windows下安装hadoop的过程。
hadoop在windows下运行需要对bin和etc路径下的可执行文件和配置文件进行调整,来兼容win运行环境。下载一个合适的兼容win的hadoop版本要比自己一点一点调试效率高多了,当然如果你是大牛的话请忽略以下教程。
一、下载hadoop和win兼容组件。
百度网盘备份(hadoop2.7.1):链接:https://pan.baidu.com/s/1EAmeBHU3YhQBfNhfR2RKkA 提取码:553d
二、安装:
hadoop安装前请确定java已安装好,具体可参考我的教程:https://blog.csdn.net/qq_15903671/article/details/81702284
hadoop是开箱即用的,只需要解压到一个固定路径就好。
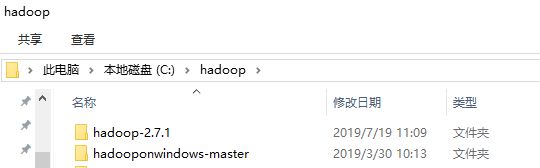
解压好后的hadoop-2.7.1即为windows下的hadoop运行目录了。
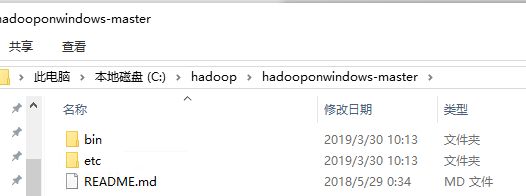
hadoopwindows-master里有修改好的bin和etc文件夹。复制到hadoop-2.7.1文件夹中,把原来的bin和etc覆盖掉。
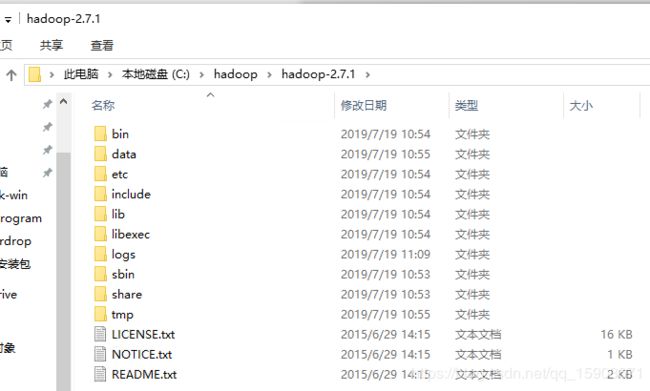
hadoop-2.7.1文件夹内是没有data和tmp的,需要手动创建一下。然后data文件夹下还需要创建datanode和namenode两个文件夹。这个文件夹是用来存储数据的,如果C盘是机械盘或容量较小的话,可以把tmp和data创建到D盘或其他容量较大的盘,但后面调整hdfs配置的时候要留意。
三、配置环境变量:
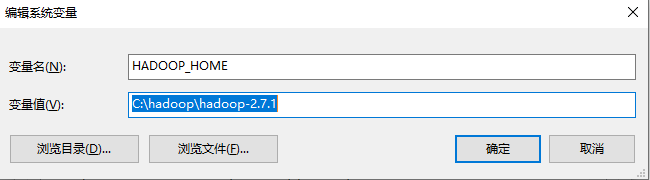
HADOOP_HOME配置到刚刚解压好的hadoop路径下。
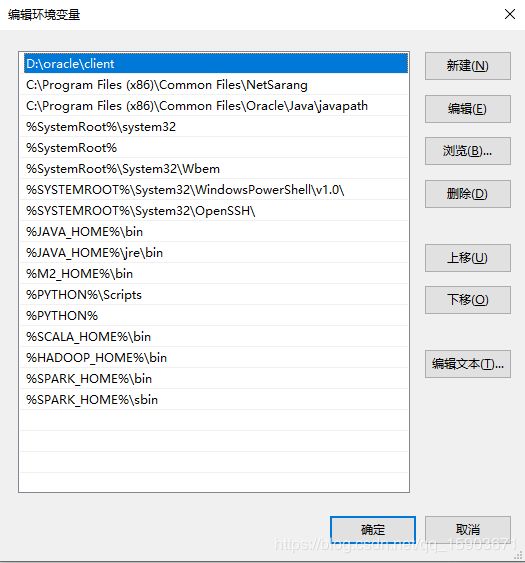
Path里添加%HADOOP_HOME%\bin配置
四、修改配置文件:
配置好环境变量不是说就能用了,还要几个必要的配置文件要设置。
如果只是学习测试,只要单机运行hadoop即可,需要配置JAVA_HOME,让hadoop找到jdk,需要配置namenode和datanode,让hadoop知道把数据存在哪。
4.1 配置JAVA_HOME: 找到etc\hadoop\hadoop-env.cmd 右键编辑。
由于是针对windows重新构建过的hadoop,所以存在cmd文件,如果是在linux环境下,应该是sh文件。

找到set JAVA_HOME 这行,把jdk地址写进去。注意 Program Files这个路径需要使用PROGRA~1来替代,否则读到空格后面的内容就过滤掉了。
4.2 配置namenode和datanode: 找到etc\hadoop\hdfs-site.xml 右键编辑。
这里配置刚刚创建的data文件夹中的namenode和datanode,如果你是创建在其他位置,记住这里不要写错了。
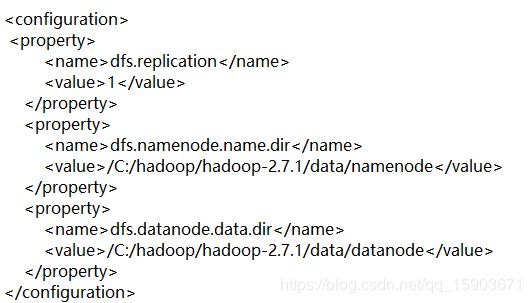
注意 盘服前面还要加一个斜杠。不加找不到地址。。。
五、格式化namenode,测试hadoop
hadoop使用前需要对hdfs进行格式化,创建这个数据存储工具。指令是 hdfs namenode -format
这个指令真的不是随便用的,执行之后hdfs会被格成空的,如果已经有数据了,那么会丢失!!!另外,如果hadoop已经运行起来了,由于某种原因你想格式化hdfs的话。。。指令运行之后需要手工调整些配置才能跑起来哦。
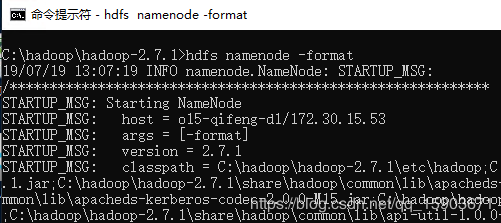
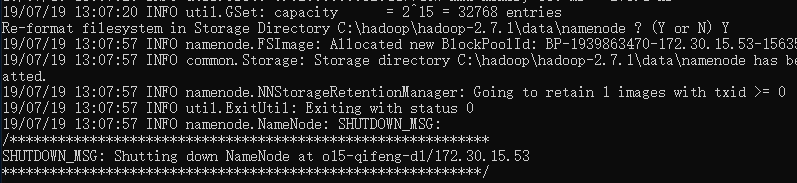
格式化hdfs完成后,就可以启动hadoop了。
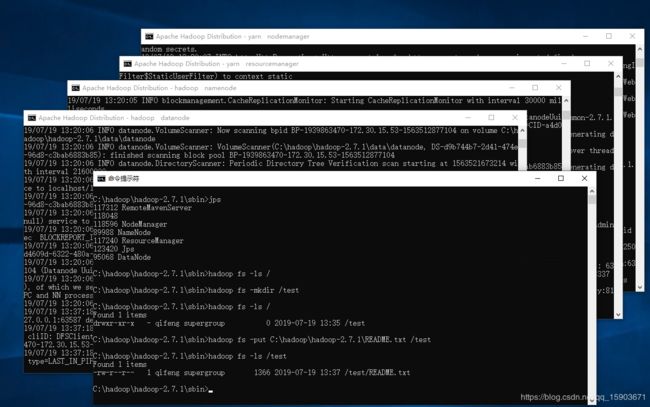
在 sbin路径下有 start-all.cmd 启动脚本,会启动四个java进程,分别是:yarn NodeManager(hadoop的节点代理)、ResourceManager(交互协议)、namenode(hdfs的命名空间)、datanode(hdfs的数据节点)
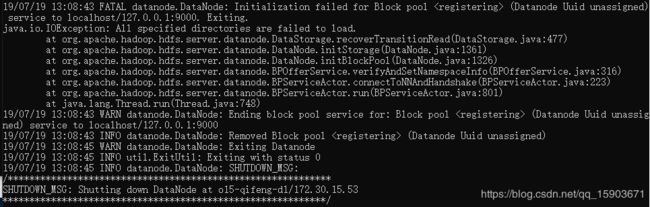
如果发现datenode起不来了,可能是因为再次格式化hdfs了。在hdfs格式化时,会将namenode中的clusterID更新掉,但是datanode只有第一次格式化时会写入clusterID,之后不会更新。所以,对hdfs重新格式化有两种方法:
1.hdfs重新格式化,原来的数据不想要了:清空datanode文件夹,然后hdfs namenode -format
2.hdfs重新格式化,原来的数据暂时保留:修改hdfs-site.xml给datanode换个地址,然后hdfs namenode-format
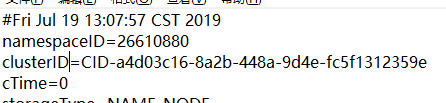
当然了,还有一种情况就是:hdfs重新格式化,datanode已经起不来了。这个时候检查一下datanode和namenode的clusterID是否不一致,然后改成一致的就能启动了。
在namenode和datanode文件夹下current\VERSION中有clusterID属性,单机模式下只要改成一致的就行了。如果分布式模式下有多个datanode,那么更改namenode的clusterID是个好的选择。
重新启动看到四个进程都跑起来且没有报错,就可以使用hadoop了。