颜值打分器
颜值打分器
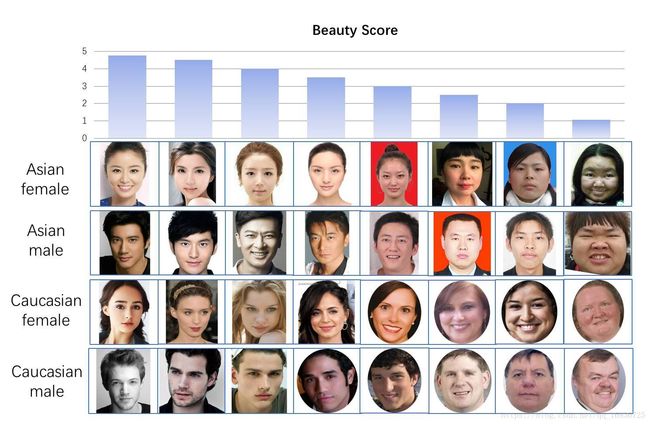
最近,华南理工大学发布了一个颜值数据库SCUT-FBP5500,数据集共有5500个人,分值在1~5之间,
数据库下载地址:
- 百度网盘:https://pan.baidu.com/s/1gguqPpx,密码是mh8j
- GoogleDrive:https://drive.google.com/open?id=1_BBiG0xOxYnCTItUXh82GTVorp6ODy-m
我将利用keras建立一个基于深度学习的颜值打分系统,不同于图像分类任务,颜值打分是一个回归任务,不能利用keras自带的ImageDatagenerator产生迭代器给模型喂数据,我们将实现一个类似的迭代器
__author__ = 'lzy'
# image_input.py
import cv2
from keras.utils import Sequence
import math
import numpy as np
from random import shuffle, randint
import os
class SequenceData(Sequence):
def __init__(self, file_list, batch_size, target_size, mode='caffe'):
self.file_list = file_list
self.batch_size = batch_size
self.target_size = target_size
self.mode = mode
def __len__(self):
num_imgs = len(self.file_list)
return math.ceil(num_imgs / self.batch_size)
def __getitem__(self, idx):
file_sub_list = self.file_list[idx*self.batch_size : (idx+1)*self.batch_size]
batch_x = np.array([self.read_img(file[0]) for file in file_sub_list])
batch_y = np.array([file[1] for file in file_sub_list], dtype=np.float32)
return batch_x, batch_y
def read_img(self, file_name):
file_path = os.path.join('data/Images', file_name)
try:
img = cv2.imread(file_path)
img = cv2.resize(img, self.target_size)
# 象征性的做一点数据增广
# 随机对图像进行数据翻转
if randint(0, 1):
img = img[:, ::-1, :]
img = np.array(img, dtype=np.float32)
if self.mode == 'caffe':
img[:, :, 0] -= 103.939
img[:, :, 1] -= 116.779
img[:, :, 2] -= 123.68
elif self.mode == 'tf':
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img / 127.5 - 1.0
except Exception as e:
print(e)
else:
return img
def read_file_list(train_test_split_ratio=0.8):
with open('data/train_test_files/SCUT-FBP5500.txt', 'r') as f:
file_list = f.read()
file_list = file_list.split('\n')[:-1]
file_list = [file.split(' ') for file in file_list]
# 将颜值分数归一化到[0, 1]之间
file_list = [(file[0], 0.2 * float(file[1])) for file in file_list]
shuffle(file_list)
train_len = int(len(file_list) * train_test_split_ratio)
train_file_list = file_list[:train_len]
test_file_list = file_list[train_len:]
return train_file_list, test_file_list
if __name__ == '__main__':
read_file_list()keras已经提供了好多个在Imagenet上训练过的模型,我们将采用这些预训练模型来建议一个颜值打分系统
__author__ = 'lzy'
import tensorflow as tf
from keras.applications import ResNet50
from keras import optimizers
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpoint
from keras.backend.tensorflow_backend import set_session
import math
import os
from image_input import SequenceData, read_file_list
# 指定gpu和显存占用, stupid tensorflow
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
set_session(tf.Session(config=config))
batch_size = 32
target_size = (224, 224)
# 这个例子中我们采用resnet50作为base network
resnet = ResNet50(include_top=False, pooling='avg')
resnet.trainable = False
model = Sequential()
model.add(resnet)
model.add(Dropout(0.5)) # 加个dropout防止过拟合
model.add(Dense(1, activation='sigmoid')) # 增加一层给颜值打分,激活函数选择为sigmoid保证输出在[0, 1]之间
print(model.summary())
model.compile(optimizer=optimizers.SGD(lr=0.001), loss='mse')
callbacks = [EarlyStopping(monitor='val_loss',
patience=5,
verbose=1,
min_delta=1e-4),
ReduceLROnPlateau(monitor='val_loss',
patience=3,
factor=0.1,
epsilon=1e-4),
ModelCheckpoint(monitor='val_loss',
filepath='weights/resnet50_weights.hdf5',
save_best_only=True,
save_weights_only=True)]
train_file_list, test_file_list = read_file_list()
train_steps_per_epoch = math.ceil(len(train_file_list) / batch_size)
test_steps_per_epoch = math.ceil(len(test_file_list) / batch_size)
train_data = SequenceData(train_file_list, batch_size, target_size)
test_data = SequenceData(test_file_list, batch_size, target_size)
model.fit_generator(train_data,
steps_per_epoch=train_steps_per_epoch,
epochs=30,
verbose=1,
callbacks=callbacks,
validation_data=test_data,
validation_steps=test_steps_per_epoch,
use_multiprocessing=True)
训练结束就来测试一下吧,
__author__ = 'lzy'
from keras.applications import ResNet50
from keras.models import Sequential
from keras.layers import Dense
import numpy as np
import os
import cv2
def score(model, img_path, target_size=(224, 224), mode='caffe'):
img = cv2.imread(img_path)
img = cv2.resize(img, target_size)
img = np.array(img, dtype=np.float32)
if mode == 'caffe':
img[:, :, 0] -= 103.939
img[:, :, 1] -= 116.779
img[:, :, 2] -= 123.68
elif mode == 'tf':
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = img / 127.5 - 1.0
img = np.expand_dims(img, axis=0)
scores = model.predict_on_batch(img)
print(scores)
os.environ['CUDA_VISIBLE_DEVICES'] = '1'
target_size = (224, 224)
resnet = ResNet50(include_top=False, pooling='avg')
model = Sequential()
model.add(resnet)
model.add(Dense(1, activation='sigmoid'))
model.trainable = False
model.load_weights('weights/resnet50_weights.hdf5')
score(model, 'data/Images/test.jpg')搞一张大幂幂的头像来评一下:

竟然得到了4.29这么高的分数
再来试试程序员共同的老婆Gakki吧:
哎,老婆只得到了3.76分,不过这已经比80%的人都好看了
输给了大幂幂,这个系统一定把欧派也考虑在内了,不正经的CNN
最后再来看看我自己能得到多少分

只能告诉你们我和吴彦祖的平均分是3.53,搞什么搞嘛