NLP面试题目汇总1-5
1.有哪些文本表示模型,它们各有什么优缺点?
文本表示模型是研究如何表示文本数据的模型,输入是语料库(文档)。
知识点:
- 词袋模型
- TF-IDF
- N-gram
词袋模型与N-gram
最基本的文本表示模型是词袋模型(Bag of Words)。基本思想是把每篇文章看成一袋子词,并忽略每个词出现的顺序。具体来看:将整段文本表示成一个长向量,每一维代表一个单词。该维对应的权重代表这个词在原文章中的重要程度。

常用TF-IDF计算权重。公式为:
T F − I D F ( t , d ) = T F ( t , d ) ∗ I D F ( t ) TF-IDF(t,d)=TF(t,d)*IDF(t) TF−IDF(t,d)=TF(t,d)∗IDF(t)
其中TF(t,d)为单词t在文档中出现的频率,IDF(t)是逆文档频率,用来衡量单词t对表达语义所起的重要性。表示为
I D F ( t ) = l o g 文 章 总 数 包 含 单 词 t 的 文 章 总 数 + 1 IDF(t)=log\frac{文章总数}{包含单词t的文章总数+1} IDF(t)=log包含单词t的文章总数+1文章总数
直观的解释是如果一个单词在非常多的文章里面都出现,那么它可能是一个比较通用的词汇,对于区分某篇文章特殊语义的贡献较小,因此对权重做一定惩罚。
缺点 单词程度的划分有时候并不是一个好的做法。比如Natural Language Processing一词,单个单词拆分的语义与三个词连续出现的语义并不相同。
改进 通常可将连续出现的N个单词构成的词组作为一个特征放到向量表示中去。构成N-gram模型
主题模型
主题模型用于从文本库中发现有代表性的主题(得到每个主题上的词的分布特性),并且能够计算出每篇文章的主题分布。
词嵌入与深度学习模型
词嵌入是一类将词向量化的模型的统称,核心思想是将每个单词都映射成地位空间上的一个稠密向量。低维空间上的每一个单词也可以看做是一个隐含的主题,只不过不像主题模型中那么明显。
对有N个单词的文档,词嵌入用K维向量映射单词,可以得到一个N*K的矩阵来表示这篇文档。但是还需要抽象出更高层的特征,通常使用深度学习来得到更高维的特征。
2.Word2vec是如何工作的?它和LDA有什么区别和联系?
谷歌2013年提出的word2vec是目前最常用的词嵌入模型之一。word2vec实际上是一种浅层的神经网络模型,它有两种网络结构,分别是CBOW和skip-gram。
知识点
- word2vec
- LDA
word2vec
CBOW目标是根据上下文出现的单词预测当前词的生成概率。而Skip-gram根据当前词预测上下文各词的生成概率。
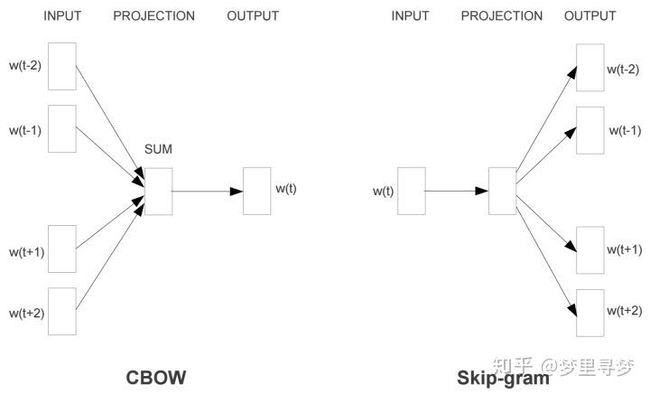
其中 w ( t ) w(t) w(t)是当前所关注的词, w ( t − 2 ) , w ( t − 1 ) , w ( t + 1 ) , w ( t + 2 ) w(t-2),w(t-1),w(t+1),w(t+2) w(t−2),w(t−1),w(t+1),w(t+2)是上下文单词,这里前后滑动窗口大小均设为2。
CBOW和skip-gram都可以表示为有输入层、映射层、输出层组成的浅层神经网络。
输入层中每个单词是由独热编码表示。所有词均表示一个N维向量,N为词汇表中单词的总数。在向量中,每个单词对应的维度为1,其余维度为0。
在映射层中,K个隐含单元的值可以由N维输入向量以及连接输入和隐含单元的NK维权重矩阵计算得到。
输出层向量的值可以由隐含层向量(K维),以及连接隐含层和输出层之间的KN维权重矩阵计算得到。输出层也是一个N维向量,每一维与词汇表中的一个单词对应。最后对输出层向量应用Softmax函数,可以得到每个单词的生成概率。
接下来需要训练神经网络权重,使得所有单词的整体生成概率最大化。共有两大参数:从输入层到隐含层的一个维度为NK的权重矩阵,从隐含层到输出层的一个维度为KN的权重矩阵。学习权重可以使用BP算法实现。
训练得到维度为N * K和K * N的两个权重矩阵之后,可以选择其中一个作为N个词的K维向量表示。
但是由于Softmax激活函数存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得迭代过程非常缓慢。由此产生了Hierarchical Softmax和Negative Sampling两种方法。
word2vec与LDA区别
首先,LDA是按照文档中单词的共现关系来对单词按照主题聚类,也可以理解为对“文档-单词”矩阵进行分解,得到“文档-主题”和“主题-单词”两个概率分布。而word2vec实际上是对“上下文-单词”矩阵进行学习,其中上下文由周围几个单词组成,由此学到的词向量更多融入了上下文特征。
主题模型和词嵌入两类方法最大的不同在于模型本身。
主题模型是一种基于概率图模型的生成式模型。其似然函数可以写为若干条件概率连乘的形式,其中包含需要推测的隐含变量(即主题)
词嵌入模型一般表示为神经网络的形式,似然函数定义在网络的输出之上。需要学习网络的权重来得到单词的稠密向量表示。
3.处理文本数据时,RNN比CNN有什么特点?
知识点:
- RNN
- CNN
传统文本处理任务的方法一般将TF-IDF向量作为特征输入,这样实际上丢失了输入的文本系列中每个单词的顺序。
CNN一般会接收一个定长的向量作为输入,然后通过滑动窗口加池化的方法将原来的输入转换为一个固定长度的向量表示。这样做可以捕捉到文本中的一些局部特征,但是两个单词之间的长距离依赖关系难以学习。
RNN能够很好处理文本数据变长并且有序的输入序列。将前面阅读到的有用信息编码到状态变量中去,从而拥有了一定的记忆能力。
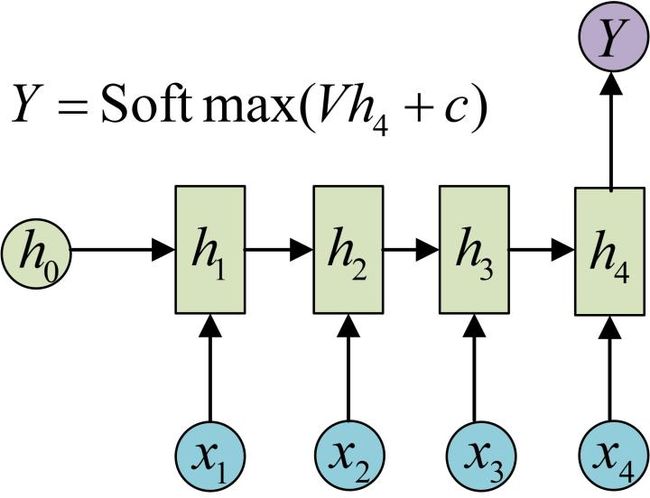
一个长度为T的序列用RNN建模,展开后可看做是一个T层前馈神经网络。其中第t层的隐含状态 h t h_t ht编码了序列中前t个输入的信息。可以通过当前的输入 x t x_t xt和上一层神经网络的状态 h t − 1 h_{t-1} ht−1计算得到。最后一层的状态 h T h_T hT编码了整个序列的信息,因此可以作为整篇文档的压缩表示。在 h T h_T hT后面加一个Softmax层,输出文本所属类别的预测概率y,就可以实现文本分类。 h t h_t ht和y的计算公式如下:
n e t t = U x t + W h t − 1 net_t = Ux_t+Wh_{t-1} nett=Uxt+Wht−1
h t = f ( n e t t ) h_t = f(net_t) ht=f(nett)
y = g ( V h T ) y=g(Vh_T) y=g(VhT)
其中f和g为激活函数,U为输入层到隐含层的权重矩阵,W为隐含层中从上一时刻到下一时刻转移的权重矩阵。在文本分类任务中,f可以选取Tanh或ReLU函数,g可以采用Softmax函数。
通过不断最小化损失误差(即输出的y与真实类别之间的距离),可以不断训练网络,使得得到的循环神经网络可以准确预测文本类别。相比于CNN,RNN由于具备对序列信息的刻画能力,往往能得到更加准确的结果。
4.RNN为什么会出现梯度消失或梯度爆炸?有哪些改进方案?
RNN的求解可以采用BPTT(Back Propagation Through Time)算法实现。实际上是BP的简单变种。RNN设计的初衷在于捕捉长距离输入之间的依赖关系,然而使用BPTT的算法并不能成功捕捉远距离依赖关系,这一现象源于深度神经网络中的梯度消失问题。
传统的RNN网络梯度可以表示为连乘的形式:
∂ n e t t ∂ n e t 1 = ∂ n e t t ∂ n e t t − 1 . ∂ n e t t − 1 ∂ n e t t − 2 . . . ∂ n e t 2 ∂ n e t 1 \frac{\partial net_t}{\partial net_1}=\frac{\partial net_t}{\partial net_{t-1}}.\frac{\partial net_{t-1}}{\partial net_{t-2}}...\frac{\partial net_{2}}{\partial net_{1}} ∂net1∂nett=∂nett−1∂nett.∂nett−2∂nett−1...∂net1∂net2
其中
n e t t = U x t + W h t − 1 net_t = Ux_t+Wh_{t-1} nett=Uxt+Wht−1
h t = f ( n e t t ) h_t = f(net_t) ht=f(nett)
y = g ( V h t ) y=g(Vh_t) y=g(Vht)
所以
∂ n e t t ∂ n e t t − 1 = ∂ n e t t ∂ h t − 1 ∂ h t − 1 ∂ n e t t − 1 ( 链 式 法 则 ) = W . d i a g [ f ‘ ( n e t t − 1 ) ] \frac{\partial net_t}{\partial net_{t-1}}=\frac{\partial net_{t}}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial net_{t-1}} (链式法则)=W.diag[f`(net_{t-1})] ∂nett−1∂nett=∂ht−1∂nett∂nett−1∂ht−1(链式法则)=W.diag[f‘(nett−1)]
其中 ∂ n e t t ∂ n e t t − 1 \frac{\partial net_t}{\partial net_{t-1}} ∂nett−1∂nett对应的n*n矩阵又被称为雅克比矩阵。
由于预测误差沿神经网络每一层反向传播,当雅克比矩阵最大特征值大于1时,随着离输出越来越远,每层的梯度大小会呈指数增长,导致梯度爆炸。反之若最大特征值小于1,梯度大小会指数减小,产生梯度消失。梯度消失意味着无法通过加深网络层数来提升预测效果,只有靠近输出的几层才真正起到学习的作用,这样RNN很难学习到输入序列中的长距离依赖关系。
梯度爆炸可以通过梯度裁剪来缓解,即当梯度的范式大于某个给定值的时候,对梯度进行等比缩放。而梯度消失问题需要对模型本身进行改进。深度残差网络是对前馈神经网络的改进。通过残差学习的方式缓解了梯度消失的现象,从而可以学习到更深层的网络表示。对于RNN来说,长短时记忆模型及其变种门控循环单元等模型通过加入门控机制,很大程度上缓解了梯度消失带来的损失。
5.在RNN中可以采用ReLU作为激活函数吗?
在CNN中采用ReLU激活函数可以有效改进梯度消失,取得更好收敛速度和收敛结果,那么在RNN中可以采用ReLU作为激活函数吗?
答案是肯定的。但是需要对矩阵的初值做一定限制,否则容易引发数值问题。首先回顾一下RNN前向传播公式:
n e t t = U x t + W h t − 1 net_t = Ux_t+Wh_{t-1} nett=Uxt+Wht−1
h t = f ( n e t t ) h_t = f(net_t) ht=f(nett)
根据前向传播公式,向前传播一层,得到:
n e t t = U x t + W h t − 1 = U x t + W f ( U x t − 1 + W h t − 2 ) net_t = Ux_t+Wh_{t-1}=Ux_t+Wf(Ux_{t-1}+Wh_{t-2}) nett=Uxt+Wht−1=Uxt+Wf(Uxt−1+Wht−2)
如果采用ReLU替换公式中的激活函数f,并且假设ReLU一直处于激活区域(即输入大于0),则有 f ( x ) = x f(x)=x f(x)=x
带入可得:
n e t t = U x t + W ( U x t − 1 + W h t − 2 net_t=Ux_t+W(Ux_{t-1}+Wh_{t-2} nett=Uxt+W(Uxt−1+Wht−2
继续将其展开,net的表达式最终包含t个W连乘。如果W不是单位矩阵(对角线上为1,其余元素为0的矩阵),最终的结果将会趋于0或无穷,引发严重的数值问题。
那么为什么在CNN中不会出现这样的问题呢,因为CNN中每一层的权重矩阵是不同的,并且在初始化的时候它们是独立同分布的,可以相互抵消,多层之后不会出现严重的数值问题。
回到RNN的梯度计算公式
∂ n e t t ∂ n e t t − 1 = W . d i a g [ f ‘ ( n e t t − 1 ) ] \frac{\partial net_t}{\partial net_{t-1}}=W.diag[f`(net_{t-1})] ∂nett−1∂nett=W.diag[f‘(nett−1)]
假设采用了ReLU激活函数,且一开始所有神经元都处于激活中(即输入大于0)。则 d i a g [ f ‘ ( n e t t − 1 ) ] diag[f`(net_{t-1})] diag[f‘(nett−1)]为单位矩阵。则有 ∂ n e t t ∂ n e t t − 1 = W \frac{\partial net_t}{\partial net_{t-1}}=W ∂nett−1∂nett=W。经历了n层传递之后,有 ∂ n e t t ∂ n e t t − 1 = W n \frac{\partial net_t}{\partial net_{t-1}}=W^n ∂nett−1∂nett=Wn。可以看到,即使采样了ReLU,只要W不是单位矩阵,还是会出现梯度消失或梯度爆炸问题。
综上所述,采用ReLU作为RNN中隐含层的激活函数时,只有当W的取值在单位矩阵附近时才能取得较好结果。因此需要将W初始化为单位矩阵。实践证明,初始化W为单位矩阵并使用ReLU激活函数在一些应用中取得了与LSTM相似的结果,并且学习速度更快。
6.LSTM是如何实现长短期记忆功能的?
RNN有梯度消失和梯度爆炸问题,学习能力有限。LSTM可以对有价值的信息进行长期记忆,有广泛应用
首先结合LSTM结构图和更新的计算公式探讨这种网络如何实现功能。
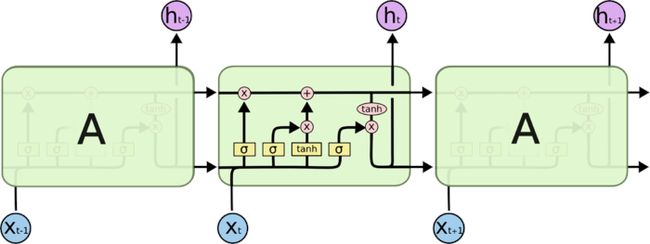
与传统的RNN相比,LSTM依然是基于 x t x_t xt和 h t − 1 h_{t-1} ht−1来计算 h t h_t ht,只不过对内部的结果进行了更加精细的设计:加入了输入门 i t i_t it,遗忘门 f t f_t ft以及输出门 o t o_t ot和一个内部记忆单元 c t c_t ct。
输入门控制当前计算的新状态以及以多大程度更新到记忆单元中;遗忘门控制前一步记忆单元中的信息以多大程度被遗忘掉;输出门控制当前的输出有多大程度取决于当前的记忆单元。
经典的LSTM中,第t步的更新计算公式为:
i t = σ ( W i x t + U i h t − 1 + b i ) i_t=\sigma(W_ix_t+U_ih_{t-1}+b_i) it=σ(Wixt+Uiht−1+bi) 输入门
f t = σ ( W f x t + U f h t − 1 + b f ) f_t=\sigma(W_fx_t+U_fh_{t-1}+b_f) ft=σ(Wfxt+Ufht−1+bf) 遗忘门
o t = σ ( W o x t + U o h t − 1 + b o ) o_t=\sigma(W_ox_t+U_oh_{t-1}+b_o) ot=σ(Woxt+Uoht−1+bo) 输出门
c t ~ = T a n h ( W c x t + U c h t − 1 ) \widetilde{c_t}=Tanh(W_cx_t+U_ch_{t-1}) ct =Tanh(Wcxt+Ucht−1) 候选记忆
c t = f t ⊙ c t − 1 + i t ⊙ c t ~ {c_t}=f_t\odot c_{t-1}+i_t\odot \widetilde{c_t} ct=ft⊙ct−1+it⊙ct 记忆单元
h t = o t ⊙ T a n h ( c t ) {h_t}=o_t\odot Tanh(c_{t}) ht=ot⊙Tanh(ct)
其中 i t i_t it是通过输入 x t x_t xt和上一步的隐含层输出 h t − 1 h_{t-1} ht−1进行线性变换,再经过激活函数 σ \sigma σ得到。输入门的 i t i_t it的结果是向量,其中每个元素都是从0到1之间的实数,用于控制各维度流过阀门的信息量; W t W_t Wt和 U t U_t Ut两个矩阵和向量 b t b_t bt为输入门的参数,是在训练过程中得到的。遗忘门 f t f_t ft和输出门 o t o_t ot的计算方式与输入门类似,它们有各自的参数W、U和b。
与传统RNN不同的是,从上一个记忆单元 c t − 1 c_{t-1} ct−1到当前状态 c t c_{t} ct的转移不一定完全取决于激活函数计算得到的状态,还得由输入门和遗忘门共同控制。
在一个训练好的网络中,当输入序列没有重要信息时,LSTM遗忘门的值接近为1,输入门接近0,此时过去的记忆会被保存,从而实现了长期记忆;当输入的序列中出现了重要信息时,LSTM会将其存入记忆中,此时输入门的值会接近于1;当输入序列出现重要信息,且该信息意味着之前的记忆不再重要的时候,输入门接近1,遗忘门接近0,这样旧的记忆被遗忘,新的重要信息被记忆。经过这样的设计,整个网络更容易学习到序列之间的长期依赖。