tensorflow之综合学习系列实例之Word2Vector
这篇文章和大家一下学习在自然语言处理中用的最频繁的一个知识就是词向量,它不难,但很重要,而且已经有很多的开源实现!
前提:表示一个词的方法有哪些?,答案肯定是有很多的,比如 数组,索引下标,等...在这个里面有个比较流行的方法就是One-Hot
机制,它的特点是存储比较稀疏,缺点是所有词与词之间都是孤立的,所以缺少相互联系,这在NLP使用中有很多的不足,因此一种新的
替代方式产生了,就是词向量.
词向量是什么
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
举个栗子,
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
每个词都是茫茫 0 海中的一个 1。
这种 One-hot Representation 如果采用稀疏方式存储,会是非常的简洁:也就是给每个词分配一个数字 ID。比如刚才的例子中,话筒记为 3,麦克记为 8(假设从 0 开始记)。如果要编程实现的话,用 Hash 表给每个词分配一个编号就可以了。这么简洁的表示方法配合上最大熵、SVM、CRF 等等算法已经很好地完成了 NLP 领域的各种主流任务。
当然这种表示方法也存在一个重要的问题就是“词汇鸿沟”现象:任意两个词之间都是孤立的。光从这两个向量中看不出两个词是否有关系,哪怕是话筒和麦克这样的同义词也不能幸免于难。
Deep Learning 中一般用到的词向量并不是刚才提到的用 One-hot Representation 表示的那种很长很长的词向量,而是用 Distributed Representation(不知道这个应该怎么翻译,因为还存在一种叫“Distributional Representation”的表示方法,又是另一个不同的概念)表示的一种低维实数向量。这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …]。维度以 50 维和 100 维比较常见。这种向量的表示不是唯一的,后文会提到目前计算出这种向量的主流方法。
(个人认为)Distributed representation 最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。用这种方式表示的向量,“麦克”和“话筒”的距离会远远小于“麦克”和“天气”。可能理想情况下“麦克”和“话筒”的表示应该是完全一样的,但是由于有些人会把英文名“迈克”也写成“麦克”,导致“麦克”一词带上了一些人名的语义,因此不会和“话筒”完全一致。
词向量的来历
Distributed representation 最早是 Hinton 在 1986 年的论文《Learning distributed representations of concepts》中提出的。虽然这篇文章没有说要将词做 Distributed representation,(甚至我很无厘头地猜想那篇文章是为了给他刚提出的 BP 网络打广告,)但至少这种先进的思想在那个时候就在人们的心中埋下了火种,到 2000 年之后开始逐渐被人重视。
Distributed representation 用来表示词,通常被称为“Word Representation”或“Word Embedding”,中文俗称“词向量”。真的只能叫“俗称”,算不上翻译。半年前我本想翻译的,但是硬是想不出 Embedding 应该怎么翻译的,后来就这么叫习惯了-_-||| 如果有好的翻译欢迎提出。(更新:@南大周志华 在这篇微博中给了一个合适的翻译:词嵌入)Embedding 一词的意义可以参考维基百科的相应页面(链接)。后文提到的所有“词向量”都是指用 Distributed Representation 表示的词向量。
如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难[Bengio 2003]。使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要套用 Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
同时如上一节提到的,相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能,让模型看起来非常的漂亮。
词向量的训练
要介绍词向量是怎么训练得到的,就不得不提到语言模型。到目前为止我了解到的所有训练方法都是在训练语言模型的同时,顺便得到词向量的。
这也比较容易理解,要从一段无标注的自然文本中学习出一些东西,无非就是统计出词频、词的共现、词的搭配之类的信息。而要从自然文本中统计并建立一个语言模型,无疑是要求最为精确的一个任务(也不排除以后有人创造出更好更有用的方法)。既然构建语言模型这一任务要求这么高,其中必然也需要对语言进行更精细的统计和分析,同时也会需要更好的模型,更大的数据来支撑。目前最好的词向量都来自于此,也就不难理解了。
相关理论知识我们就说完了,接下来我们说一下具体的实现机制和方式
1 基于python的gensim 可以直接拿过来用 而且效果还是很不错的
2 基于tensoflow的nce机制可以实现,效果因数据量而定
3 基于facebook的fasttext开源框架,效果好而且性能也高
4 基于已经训练好的词向量模型文本,一般选择google,facebook,几乎都能够直接用于生产
个人推荐使用3和4这种方式,在实际生产环境中.
本文主要介绍如何通过TF实现一个词向量模型,要完成的功能就是给定一个文本内容,进行模型训练,然后输入指定的词,找出对应的TOP的相似词..
我们分析一下步骤;
1 准备一个停用词文本,并加载到内存
2 读取训练文本,并进行分词
3 对词进行ID的词典转换
4 定义输入模型参数
5 生成训练图
6 准备批量训练的词句
7 计算词的相似度
8 训练模型
9 加载模型
10 测试模型
我们看一下最终实现的完整代码:
# coding=gbk # author jiahp import tensorflow as tf import numpy as np import math import collections import pickle as pkl import jieba import os # 创建词向量 class word2vec(): # 初始化 def __init__(self, vocab_list=None, embedding_size = 200,# 词向量维度 win_len = 3, # 词的滑动窗口大小 num_sampled = 1000,# 负采样的样本数量 learning_rate = 1.0,# 学习率 logdir='/tmp/simple_word2vec',# tensorboard保存地址 model_path = None # 模型保存路径 ): # 获得模型的基本参数 self.batch_size = None # 一批中数据个数, 目前是根据情况来的 if model_path!=None: self.load_model(model_path) else: # model parameters assert type(vocab_list)==list self.vocab_list = vocab_list # 指定词汇的集合 self.vocab_size = vocab_list.__len__() # 指定词汇集合的大小 self.embedding_size = embedding_size # 指定词向量维度 self.win_len = win_len # 词滑动窗口 self.num_sampled = num_sampled # 负采样的样本大小 self.learning_rate = learning_rate # 学习比率 self.logdir = logdir # 保存路径 self.word2id = {} # word => id 的映射 (jack,1)(jhp,2) for i in range(self.vocab_size): self.word2id[self.vocab_list[i]] = i # train times self.train_words_num = 0 # 训练的单词对数 self.train_sents_num = 0 # 训练的句子数 self.train_times_num = 0 # 训练的次数(一次可以有多个句子) # train loss records self.train_loss_records = collections.deque(maxlen=10) # 保存最近10次的误差 self.train_loss_k10 = 0 self.build_graph() self.init_op() if model_path!=None: tf_model_path = os.path.join(model_path,'tf_vars') self.saver.restore(self.sess,tf_model_path) def init_op(self): self.sess = tf.Session(graph=self.graph) self.sess.run(self.init) self.summary_writer = tf.summary.FileWriter(self.logdir, self.sess.graph) # 生成图 def build_graph(self): self.graph = tf.Graph() with self.graph.as_default(): self.train_inputs = tf.placeholder(tf.int32, shape=[self.batch_size])# 输入词汇 self.train_labels = tf.placeholder(tf.int32, shape=[self.batch_size, 1]) # 向量 self.embedding_dict = tf.Variable(tf.random_uniform([self.vocab_size,self.embedding_size],-1.0,1.0))# 词对应的向量(字典) # n*k n代表分类的个数 k 单词向量 #指定nce self.nce_weight = tf.Variable(tf.truncated_normal([self.vocab_size, self.embedding_size],stddev=1.0/math.sqrt(self.embedding_size))) self.nce_biases = tf.Variable(tf.zeros([self.vocab_size])) # 将输入序列向量化 - # 根据词的ID,查找对应的向量维度 # tf.nn.embedding_lookup(tensor, id):tensor就是输入张量,id就是张量对应的索引 # 简单的讲就是根据input_ids中的id,寻找embedding中的对应元素。比如,input_ids=[1,3,5],则找出embedding中下标为1,3,5的向量组成一个矩阵返回。 embed = tf.nn.embedding_lookup(self.embedding_dict, self.train_inputs) # batch_size # 得到NCE损失 self.loss = tf.reduce_mean( # 专门计算nce的损失函数 tf.nn.nce_loss( weights = self.nce_weight, biases = self.nce_biases, labels = self.train_labels, inputs = embed, num_sampled = self.num_sampled, num_classes = self.vocab_size ) ) # tensorboard 相关 tf.summary.scalar('loss',self.loss) # 让tensorflow记录参数 # 根据 nce loss 来更新梯度和embedding self.train_op = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(self.loss) # 训练操作 # 计算与指定若干单词的相似度 self.test_word_id = tf.placeholder(tf.int32,shape=[None]) # 求各词向量的L2模 # [1]代表横向对矩阵求和 # [0]是纵向对矩阵求和 原来矩阵有几列就得到几个值 # 没有改参数的值 默认对矩阵所有元素进行求和 # keep_dims = True 维度不缩减 vec_l2_model = tf.sqrt(tf.reduce_sum(tf.square(self.embedding_dict),reduction_indices=[1],keep_dims=True)) avg_l2_model = tf.reduce_mean(vec_l2_model)# 求平均 tf.summary.scalar('avg_vec_model',avg_l2_model) self.normed_embedding = self.embedding_dict / vec_l2_model # 向量归一化 # 根据input_ids中的id,寻找embedding中的对应元素 # input_ids=[1,3,5],则找出embedding中下标为1,3,5的向量组成一个矩阵返回 test_embed = tf.nn.embedding_lookup(self.normed_embedding, self.test_word_id) # 相似度 self.similarity = tf.matmul(test_embed, self.normed_embedding, transpose_b=True) # 变量初始化 self.init = tf.global_variables_initializer() self.merged_summary_op = tf.summary.merge_all() self.saver = tf.train.Saver() # 训练句子 def train_by_sentence(self, input_sentence=[]): # input_sentence: [sub_sent1, sub_sent2, ...] # 每个sub_sent是一个单词序列,例如['这次','大选','让'] batch_inputs = [] batch_labels = [] for sent in input_sentence: for i in range(sent.__len__()): # 获取单个词汇的起始位置和结束位置 start = max(0,i-self.win_len) end = min(sent.__len__(),i+self.win_len+1) for index in range(start,end): if index == i: continue else: input_id = self.word2id.get(sent[i]) # 输入词汇对应的ID label_id = self.word2id.get(sent[index]) # 输入词汇的预测词汇对应的ID if not (input_id and label_id):# 词不在其中 直接跳过 continue batch_inputs.append(input_id) batch_labels.append(label_id) if len(batch_inputs)==0: return batch_inputs = np.array(batch_inputs,dtype=np.int32) batch_labels = np.array(batch_labels,dtype=np.int32) #更改数组形状 batch_labels = np.reshape(batch_labels,[batch_labels.__len__(),1]) # 创建输入数据和对应标签 feed_dict = { self.train_inputs: batch_inputs, self.train_labels: batch_labels } _, loss_val, summary_str = self.sess.run([self.train_op,self.loss,self.merged_summary_op], feed_dict=feed_dict) # 损失函数 self.train_loss_records.append(loss_val) # self.train_loss_k10 = sum(self.train_loss_records)/self.train_loss_records.__len__() self.train_loss_k10 = np.mean(self.train_loss_records) if self.train_sents_num % 1000 == 0 : self.summary_writer.add_summary(summary_str,self.train_sents_num) print("{a} sentences dealed, loss: {b}" .format(a=self.train_sents_num,b=self.train_loss_k10)) # train times self.train_words_num += batch_inputs.__len__() self.train_sents_num += input_sentence.__len__() self.train_times_num += 1 # 计算相似度 取TOP N 通过欧几里德距离来计算的 def cal_similarity(self,test_word_id_list,top_k=10): # 获取相似矩阵 sim_matrix = self.sess.run(self.similarity, feed_dict={self.test_word_id:test_word_id_list}) sim_mean = np.mean(sim_matrix) sim_var = np.mean(np.square(sim_matrix-sim_mean)) test_words = [] near_words = [] for i in range(test_word_id_list.__len__()): test_words.append(self.vocab_list[test_word_id_list[i]]) nearst_id = (-sim_matrix[i,:]).argsort()[1:top_k+1] nearst_word = [self.vocab_list[x] for x in nearst_id] near_words.append(nearst_word) return test_words,near_words,sim_mean,sim_var # 保存模型 训练的参数 def save_model(self, save_path): if os.path.isfile(save_path): raise RuntimeError('the save path should be a dir') if not os.path.exists(save_path): os.mkdir(save_path) # 记录模型各参数 model = {} var_names = ['vocab_size', # int model parameters 'vocab_list', # list 'learning_rate', # int 'word2id', # dict 'embedding_size', # int 'logdir', # str 'win_len', # int 'num_sampled', # int 'train_words_num', # int train info 'train_sents_num', # int 'train_times_num', # int 'train_loss_records', # int train loss 'train_loss_k10', # int ] for var in var_names: model[var] = eval('self.'+var) param_path = os.path.join(save_path,'params.pkl') if os.path.exists(param_path): os.remove(param_path) with open(param_path,'wb') as f: pkl.dump(model,f) # 记录tf模型 tf_path = os.path.join(save_path,'tf_vars') if os.path.exists(tf_path): os.remove(tf_path) self.saver.save(self.sess,tf_path) #加载模型 获取当前模型的参数 不能获取整个模型 def load_model(self, model_path): if not os.path.exists(model_path): raise RuntimeError('file not exists') param_path = os.path.join(model_path,'params.pkl') with open(param_path,'rb') as f: model = pkl.load(f) self.vocab_list = model['vocab_list'] self.vocab_size = model['vocab_size'] self.logdir = model['logdir'] self.word2id = model['word2id'] self.embedding_size = model['embedding_size'] self.learning_rate = model['learning_rate'] self.win_len = model['win_len'] self.num_sampled = model['num_sampled'] self.train_words_num = model['train_words_num'] self.train_sents_num = model['train_sents_num'] self.train_times_num = model['train_times_num'] self.train_loss_records = model['train_loss_records'] self.train_loss_k10 = model['train_loss_k10'] if __name__=='__main__': # step 1 读取停用词 stop_words = [] with open('stop_words.txt',encoding= 'utf-8') as f: line = f.readline() while line: stop_words.append(line[:-1])#去除换行符 line = f.readline() stop_words = set(stop_words)#去重复值 print('停用词读取完毕,共{n}个单词'.format(n=len(stop_words))) # step2 读取文本,预处理,分词,得到词典 raw_word_list = [] sentence_list = [] with open('4.txt') as f: line = f.readline() while line: # 替换换行符 while '\n' in line: line = line.replace('\n','') while ' ' in line: line = line.replace(' ','') if len(line)>0: # 如果句子非空 raw_words = list(jieba.cut(line,cut_all=False))# 存储分过词的字段 dealed_words = [] for word in raw_words: if word not in stop_words and word not in ['qingkan520','www','com','http']: raw_word_list.append(word)# 把分过词的字段添加到指定的集合 dealed_words.append(word) sentence_list.append(dealed_words)# 分过词的句子 line = f.readline() # ["a":1,"b":2] word_count = collections.Counter(raw_word_list)# 计算整个句子的各个词出现的词频 print('文本中总共有{n1}个单词,不重复单词数{n2},选取前30000个单词进入词典' .format(n1=len(raw_word_list),n2=len(word_count))) word_count = word_count.most_common(30000)#取词汇中前top个词 word_list = [x[0] for x in word_count]#取出所有的词 # 创建模型,训练 w2v = word2vec(vocab_list=word_list, # 词汇集合 embedding_size=200,# 向量维度 win_len=2,# 词滑动的左右长度 learning_rate=1,# 学习率 num_sampled=100, # # 负采样个数 logdir='/tmp/280') # tensorboard记录地址 num_steps = 10000 # 迭代次数 for i in range(num_steps): sent = sentence_list[i%len(sentence_list)] w2v.train_by_sentence([sent]) # 保存模型 w2v.save_model('model') # 加载模型 w2v.load_model('model') # 测试词汇 test_word = ['天地','级别'] test_id = [word_list.index(x) for x in test_word] # 找相似字段 test_words,near_words,sim_mean,sim_var = w2v.cal_similarity(test_id) print (test_words,near_words,sim_mean,sim_var)
到此代码就写完了,大家可以看看最终效果,如果训练的文本内容越多,准确度也会相对越高,这里使用了NCE机制,负采样
在此插入一个知识点,就是训练词向量的加速策略,一般有哪些?
paper中提出了两种方法,一种是Hierarchical Softmax,另一种是Negative Sampling。
本文简述了以下内容:
CBOW / Skip-gram模型的加速策略(一):Hierarchical Softmax
CBOW / Skip-gram模型的加速策略(二):Negative Sampling
Hierarchical Softmax
拿原始模型来说,计算 y^y^ 的一个分量 yi–^=P(wi–|wt−m,...,wt−1,wt+1,...,wt+m)=softmax(zi–)yi_^=P(wi_|wt−m,...,wt−1,wt+1,...,wt+m)=softmax(zi_) 时,由于使用的是softmax()函数,时间复杂度为 O(|V|)O(|V|) ,因此计算代价很大,对大规模的训练语料来说,非常impractical。
Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。
以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。Huffman树是二叉树,在叶子节点及叶子节点的权给定的情况下,该树的带权路径长度最短(一个节点的带权路径长度指根节点到该节点的路径长度乘以该节点的权,树的带权路径长度指全部叶子节点的带权路径长度之和)。直观上可以看出,叶子节点的权越大,则该叶子节点就应该离根节点越近。因此对于模型来说就是,词频越高的词,距离根节点就越近。
从根节点出发,到达指定叶子节点的路径是唯一的。Hierarchical Softmax正是利用这条路径来计算指定词的概率,而非用softmax来计算。
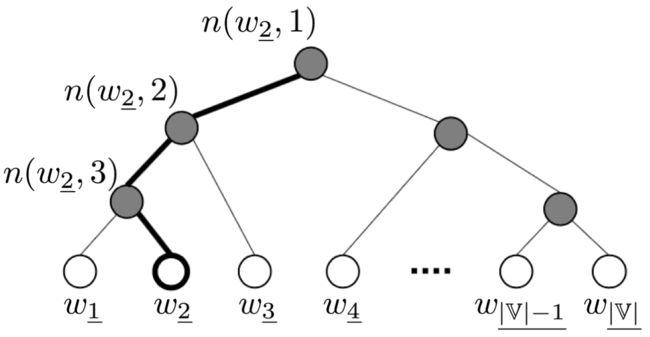
图片来源:[2],记号改成和本文一致
上图是一个已根据词频构建好的Huffman树,各叶子节点代表词表中的各个词,非叶子节点共 |V|−1|V|−1 个。以词 w2–w2_ 为例,从根节点到该叶子节点的路径长度 L(w2–)=4L(w2_)=4 ,各个节点依次被记为 n(w2–,1)n(w2_,1) 、n(w2–,2)n(w2_,2) 、n(w2–,3)n(w2_,3) 和 n(w2–,L(w2–))n(w2_,L(w2_)) 。对于每个非叶子节点 n(w,j)n(w,j) ,虽然不是词表中的词,但也引入所谓的“输出词向量” un(w,j)un(w,j) ,是需要学习的参数,为什么要引入它?下面讲述。
从根节点出发,走到指定叶子节点 ww 的过程,就是一个进行 L(w)−1L(w)−1 次二分类的过程:路径上的每个非叶子节点都拥有两个孩子节点,从当前节点 n(w,j)n(w,j) 向下走时共有两种选择,走到左孩子节点 ch(n(w,j))ch(n(w,j)) 就定义为分类到了正类,走到右孩子节点就定义为分类到了负类。
以CBOW模型为例,即输入层是 v^tv^t 。用二项Logistic回归模型对每一次分类过程建模:从当前节点 n(w,j)n(w,j) 走到下一节点,那么走到左孩子节点的概率为
走到右孩子节点的概率为
将上面两个式子统一起来,那就是
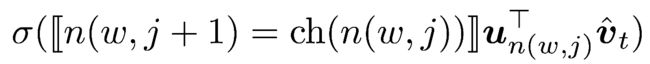
(双线括号的意思是,当括号内为真则输出1,为假则输出-1。因为这个符号渲染不出来,就用截图代替了)
现在计算输出词为 ww 的概率:这对应于一条从根节点 n(w,1)n(w,1) 走到叶子节点 n(w,L(w))n(w,L(w)) 的路径,概率计算式为下式:
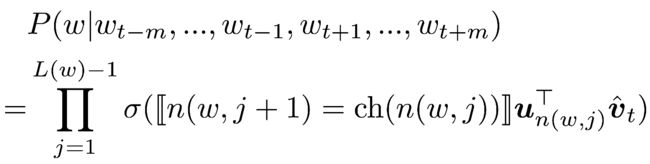
平均时间复杂度为 O(log|V|)O(log|V|) ,相比于使用softmax()函数有很大提高。
对于Skip-gram模型,表达式类似:
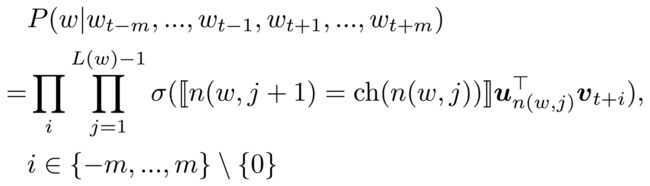
可以证明,这样计算的结果满足概率和为1:
模型对语料中的全部词串计算概率值做连乘得到似然函数,再取对数得到对数似然 LL,进而用极大似然估计来求取参数。使用SGD更新参数(求取梯度时,由于是SGD,所以 LL 的求和号可以去掉)。易知在Hierarchical Softmax的情况下每个词只会得到一个词表示(输入词向量)。梯度求取比较简单,[3] 写的非常详细并给出了参数更新过程的伪代码(Skip-gram部分写反了,应改为“各个周围词预测中心词再做连乘”,而非“中心词预测各个周围词再做连乘”)。
缺点:如果我们的训练样本里的中心词ww是一个很生僻的词,那么就得在霍夫曼树中辛苦的向下走很久了
Negative Sampling
第二种加速策略是Negative Sampling(简写NEG,负采样),这是Noise-Contrastive Estimation(简写NCE,噪声对比估计)的简化版本:把语料中的一个词串的中心词替换为别的词,构造语料 DD 中不存在的词串作为负样本。因此在这种策略下,优化目标变为了:最大化正样本的概率,同时最小化负样本的概率。对于一个词串 (w,c)(w,c) ( cc 表示 w
w 的上下文),用二项Logistic回归模型对其是正样本的概率建模:
最后建议大家在实际使用中如果需要自己做词向量可以优先使用fasttext,如果想要现成的可以使用google 已经训练好的模型