hadoop3.x高可用安装
Hadoop3.x 高可用集群安装*
Hadoop3.x 高可用集群安装
环境准备
三台centos7的虚拟机
软件包准备:
Jdk
由于hadoop是基于java开发的,所以hadoop的运行必须基于jvm这里采用最新的jdk版本
Jdk下载:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
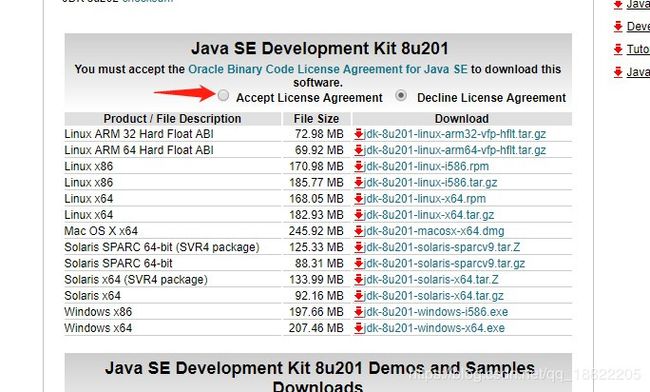
首先点击图中按钮,然后选择所需的安装包,本次采用tar.gz
Hadoop
Hadoop下载这里所提供的是hadoop官方所提供的下载地址
http://mirror.bit.edu.cn/apache/hadoop/common/
选择第三个就好,其余两个为源码包,需要解码
zookeeper
下载地址;
http://archive.apache.org/dist/zookeeper/
选择所需版本进行下载
直接下载tar.gz格式即可
网络配置
静态ip配置
Root用户编辑:/etc/sysconfig/network-scripts/ifcfg-ens33
编辑内容如下
更改BOOTPROTO=static
增加定义的ip地址 以及子网掩码
重启网卡服务 service network restart
然后尝试下ping外网 :ping baidu.com
如果成功,恭喜,静态ip设置成功
如果失败,执行命令 dhclient,然后在进行ping 外网;
关闭防火墙,并关闭开机自启
systemctl stop firewalld.service
systemctl disable firewalld.service
配置host 映射
免密登录
以ha01为例
执行命令 ssh-keygen -t rsa 一路回车生成密钥
然后执行命令 ssh-copy-id -i ~/.ssh/id_rsa.pub ha02 期间需要输入一次密码然后免密设置成功,并进行验证,
至此免密配置完成
Jdk配置
首先将官网下载jdk传入ha01进行配置
将jdk文件解压到某个文件夹下
tar -zxvf jdk-8u201-linux-x64.tar.gz -C /usr/lib/java
然后修改全局表量/etc/profile
在最后增加
JAVA_HOME=/usr/lib/java/jdk1.8.0_201
JRE_HOME=/usr/lib/java/jdk1.8.0_201/jre
CLASSPATH=.: J A V A H O M E / l i b / d t . j a r : JAVA_HOME/lib/dt.jar: JAVAHOME/lib/dt.jar:JAVA_HOME/lib/tools.jar: J R E H O M E / l i b P A T H = JRE_HOME/lib PATH= JREHOME/libPATH=JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
然后键入source /etc/profile
查看变量是否设置成功
echo $JAVA_HOME
cd $JAVA_HOME
查看java -version,还是其他版本jdk
发现原因由于本机安装了其他版本jdk 所以需要使当前jdk生效
键入命令
update-alternatives --install /usr/bin/java java /usr/lib/java/jdk1.8.0_201/bin/java 300
update-alternatives --install /usr/bin/javac javac /usr/lib/java/jdk1.8.0_201/bin/javac 300
update-alternatives --install /usr/bin/jar jar /usr/lib/java/jdk1.8.0_201/bin/jar 300
update-alternatives --install /usr/bin/javah javah /usr/lib/java/jdk1.8.0_201/bin/javah 300
update-alternatives --install /usr/bin/javap javap /usr/lib/java/jdk1.8.0_201/bin/javap 300
update-alternatives --config java
查看java -version
嗯现在没毛病了,是我想要的结果
Zookeeper配置
将下载好的zookeeper 进行解压
tar -zxvf zookeeper-3.4.9.tar.gz -C /usr/zookeeper
并配置变量
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.9
export PATH= P A T H : PATH: PATH:ZOOKEEPER_HOME/bin
使其生效
随后配置zoo.cfg
cd /usr/zookeeper/zookeeper-3.4.9/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
对照如下内容进行修改
The number of milliseconds of each tick
tickTime=2000
The number of ticks that the initial
synchronization phase can take
initLimit=10
The number of ticks that can pass between
sending a request and getting an acknowledgement
syncLimit=5
the directory where the snapshot is stored.
do not use /tmp for storage, /tmp here is just
example sakes.
dataDir=/opt/zookeepertmp/data
dataLogDir=/opt/zookeepertmp/log
the port at which the clients will connect
clientPort=2181
the maximum number of client connections.
increase this if you need to handle more clients
#maxClientCnxns=60
Be sure to read the maintenance section of the
administrator guide before turning on autopurge.
http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
Purge task interval in hours
Set to “0” to disable auto purge feature
#autopurge.purgeInterval=1
server.1=ha01:2888:3888
server.2=ha02:2888:3888
server.3=ha03:2888:3888
注意新建这里的 dataDir=/opt/zookeepertmp/data 与dataLogDir=/opt/zookeepertmp/log
并执行echo 1 >/opt/zookeepertmp/data/myid 创建myid文件
*注:这里已ha01 为模板,ha02的myid为2 ha03的myid为3
编辑完如上的内容执行 scp -r /usr/zookeeper root@ha02:/usr 将配置好的ha01 zookeeper scp 到其他两台机子 并在其他两台机子配置环境变量生成相应文件
随后在 /usr/zookeeper/zookeeper-3.4.9/bin/ 下执行
zkServer.sh start 三台机子都要执行
执行 zkServer.sh status
查看三个节点的状态,可以看到一个leader和两个follower,说明zookeeper安装成功。
Hadoop安装
将下载好的hadoop安装包解压至 /usr/local/hadoop3
tar -zxvf hadoop-3.1.2.tar.gz -C /usr/local/hadoop3
配置环境变量:/etc/profile
添加
#Hadoop 3.0
export HADOOP_HOME=/usr/local/hadoop3
export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME= H A D O O P H O M E e x p o r t H A D O O P H D F S H O M E = HADOOP_HOME export HADOOP_HDFS_HOME= HADOOPHOMEexportHADOOPHDFSHOME=HADOOP_HOME
export HADOOP_MAPRED_HOME= H A D O O P H O M E e x p o r t H A D O O P Y A R N H O M E = HADOOP_HOME export HADOOP_YARN_HOME= HADOOPHOMEexportHADOOPYARNHOME=HADOOP_HOME
export HADOOP_INSTALL= H A D O O P H O M E e x p o r t H A D O O P C O M M O N L I B N A T I V E D I R = HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR= HADOOPHOMEexportHADOOPCOMMONLIBNATIVEDIR=HADOOP_HOME/lib/native
export HADOOP_CONF_DIR= H A D O O P H O M E e x p o r t H A D O O P P R E F I X = HADOOP_HOME export HADOOP_PREFIX= HADOOPHOMEexportHADOOPPREFIX=HADOOP_HOME
export HADOOP_LIBEXEC_DIR= H A D O O P H O M E / l i b e x e c e x p o r t J A V A L I B R A R Y P A T H = HADOOP_HOME/libexec export JAVA_LIBRARY_PATH= HADOOPHOME/libexecexportJAVALIBRARYPATH=HADOOP_HOME/lib/native: J A V A L I B R A R Y P A T H e x p o r t H A D O O P C O N F D I R = JAVA_LIBRARY_PATH export HADOOP_CONF_DIR= JAVALIBRARYPATHexportHADOOPCONFDIR=HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
然后source /etc/profile 使环境生效,并验证
随后修改hadoop 文件
/usr/local/hadoop3/etc/Hadoop
文件1 core-site.xml
追加
文件2 hdfs-site.xml
追加
dfs.namenode.name.dir
file:///usr/local/hadoop3/hdfs/name
dfs.datanode.data.dir
file:///usr/local/hadoop3/hdfs/data
dfs.replication
2
dfs.webhdfs.enabled
true
文件3 mapred-site.xml
mapreduce.framework.name
yarn
文件4 yarn-site.xml
mapreduce.framework.name yarn yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname ha03文件5 workers
ha01
ha02
ha03
由于root用户安装hadoop 还需修改sbin/start -dfs.sh与stop-dfs.sh
在文件第一行下方添加
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
以及start-yarn.sh 与stop-yarn.sh文件第一行下方添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
按照如上步骤将ha02,ha03配置完成 也可用scp命令传到其他两台主机
至此hadoop3.x安装完成
首次启动初始化
zookeeper leader初始化
在hadoop namenode其中一个节点执行
hdfs zkfc -formatZK
所有节点启动journalnode
hadoop-daemon.sh start journalnode
Namenode 格式化
格式化namenode之前应当先启动journalnode节点。
hadoop namenode -format ns
启动namenode
1:首先ha01 hadoop-daemon.sh start namenode
2:ha02 与ha01同步hdfs namenode -bootstrapStandby
3.在ha02 启动 namenode hadoop-daemon.sh start namenode
启动zkfc
hadoop-daemon.sh start zkfc
启动datanode
$ hadoop-daemon.sh start datanode
在ha03上启动 yarn
Start-yarn.sh
至此hadoop3.x部署并验证完成