tensorflow----预测sinx的值
RNN之预测sinx的值
这是来自深度学习实战那本书上的例子,本人小白,做个笔记,加深理解。
先来看大体思路:
sinx 里面,连续取11个数,其中前10的值作为我们的输入序列,最后一个表示lable。
好了,就是就是这么简单。接下来就是设计RNN了。
设计两层的RNN。采用lstm。输入序列为10,输出只取最后一个时间的输出作为预测值。上图最好,(最近不知道用什么软件可以画出神经网络的图,这里只好手写了,字写的不好,莫怪) 上面写的也是十分具体了,接下来,我们分析程序。代码是非常直观的!
上面写的也是十分具体了,接下来,我们分析程序。代码是非常直观的!
先上参数:
HIDDEN_SIZE = 30 #lstm中隐藏节点个数
NUM_LAYERS =2 #lstm的层数
TIMESTEPS =10; #RNN训练序列长度
TRAINING_STEPS = 10000 #训练轮数
BATCH_SIZE= 32 #batch大小
TRAINING_EXAMPLES = 10000
TESTING_EXAMPLES =1000
SAMPLE_GAP = 0.01 #采样间隔
首先肯定是构造数据
test_start = (TRAINING_EXAMPLES+TIMESTEPS)*SAMPLE_GAP
test_end = test_start+(TESTING_EXAMPLES+TIMESTEPS)*SAMPLE_GAP
train_X,train_y=generate_data(np.sin(np.linspace(0,test_start,TRAINING_EXAMPLES+TIMESTEPS,dtype=np.float32)))
test_X, test_y = generate_data(np.sin(np.linspace(test_start, test_end, TESTING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
np.linspace(1,10,5)表示在1到10之间取5个数返回。np.sin不用多说,就是求sinx的值。
generate_data()函数就是将取到的点存放在X,y中。这个代码写的很好,刚开始没看懂为什么要len(seq)-TIMESTEPS这样写,不就是在序列中不断的取10个作为X,再取一个作为y,然后继续取10个,再取1个…一直取完整个序列嘛!但是下面这个程序就很完美的实现了这一要求,而且很简洁,如果换做是我来写,我肯定写的很,,,哎,废话了。
def generate_data(seq):
X=[]
y=[]
for i in range(len(seq)-TIMESTEPS):
X.append([seq[i:i+TIMESTEPS]])
y.append([seq[i+TIMESTEPS]])
return np.array(X,dtype=np.float32),np.array(y,dtype=np.float32)
接下来是构建两层lstm:
def lstm_model(X,y,is_training):
#建立多层lstm
cell = tf.nn.rnn_cell.MultiRNNCell([
tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)
])
outputs,_ = tf.nn.dynamic_rnn(cell,X,dtype = tf.float32) #outputs 输出维度是[batch_size,time,hidden_size]
output = outputs[:,-1,:]
#再加一层全连接层
predictions = tf.layers.dense(output,1,activation=None)
if not is_training:
return predictions,None,None
loss = tf.losses.mean_squared_error(labels=y,predictions=predictions)
op = tf.train.AdamOptimizer(learning_rate=0.1)
train_op = op.minimize(loss,tf.train.get_global_step())
return predictions,loss,train_op
这里需要了解的是output = outputs[:,-1,:]这个是取最后一个时刻的输出。outputs是顶层LSTM在每一步的输出结果,它的维度是[batch_size,time,HIDDEN_SIZE]。
HIDDEN_SIZE是LSTM的输出ht的维度。—这里我有点模糊,请大佬指教!
上面定义了模型,那么接下来就是定义如何训练了,这就是静态图。
def trains(sess,train_X,train_y):
ds = tf.data.Dataset.from_tensor_slices((train_X,train_y))
ds = ds.repeat().shuffle(1000).batch(BATCH_SIZE)
X,y = ds.make_one_shot_iterator().get_next()
with tf.variable_scope("model"):
predictions,loss,train_op = lstm_model(X,y,True)
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
_,l = sess.run([train_op,loss])
if i % 100 == 0:
print("train step: " + str(i)+ ", loss: "+str(l))
好了,上面 ds = tf.data.Dataset.from_tensor_slices((train_X,train_y))
ds = ds.repeat().shuffle(1000).batch(BATCH_SIZE)
X,y = ds.make_one_shot_iterator().get_next(),这个我知道它是调用Dataset这个API,但是这里面实现细节,我不清楚。只是百度了一下它做了那些事情,先打乱,然后将数据分为很多个batch,给train。
接下来是测试,测试调用“model”,with tf.variable_scope(“model”,reuse=True)这句话很关键,reuse参数设置True表示重用lstm_model。其它的代码应该好理解。
def run_eval(sess,test_X,test_y):
ds = tf.data.Dataset.from_tensor_slices((test_X, test_y))
ds = ds.batch(1)
X, y = ds.make_one_shot_iterator().get_next()
with tf.variable_scope("model",reuse=True):
prediction,_,_ = lstm_model(X,[0.0],False)
predictions =[]
labels = []
for i in range(TESTING_EXAMPLES):
p,l = sess.run([prediction,y])
predictions.append(p)
labels.append(l)
#计算rmse作为评价指标
predictions = np.array(predictions).squeeze()
labels = np.array(labels).squeeze()
rmse = np.sqrt(((predictions-labels)**2).mean(axis=0))
print("Mean Square Error is : %f"%rmse)
plt.figure()
plt.plot(predictions,label = "predictions")#labels="predictions"
plt.plot(labels,label='labels')
plt.legend()
plt.show()
将y值全部描点,然后连线是可以得到sinx图像的,因为我们就是在sinx上间隔一段小距离取的点。而predictions是我们通过这段小距离上的点用RNN预测出来的点。看看和y描绘的sinx有啥区别,这里看图:
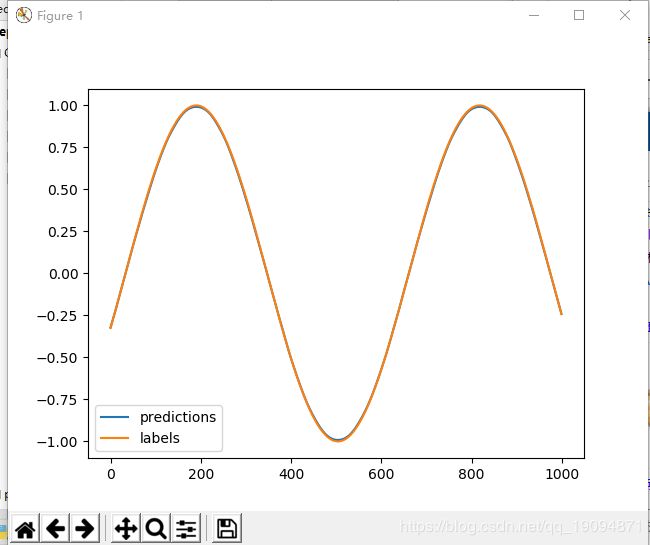 可以看到两条线只有在峰值那块可以看出差距,其它地方基本重合。
可以看到两条线只有在峰值那块可以看出差距,其它地方基本重合。
这里附上全部代码,如果有什么不懂的,我们相互讨论。我其实也有些地方没搞懂,比如HIDDEN_SIZE这个参数设置的是什么,是我理解的lstm输出的ht维度吗?欢迎大佬留言讨论!
'''---来自深度学习实战书上的对sinx取值预测的例子---'''
import tensorflow as tf
import numpy as np
import matplotlib as mpl
mpl.use('TkAgg')
from matplotlib import pyplot as plt
HIDDEN_SIZE = 30 #lstm中隐藏节点个数
NUM_LAYERS =2 #lstm的层数
TIMESTEPS =10; #RNN训练序列长度
TRAINING_STEPS = 10000 #训练轮数
BATCH_SIZE= 32 #batch大小
TRAINING_EXAMPLES = 10000
TESTING_EXAMPLES =1000
SAMPLE_GAP = 0.01 #采样间隔
def generate_data(seq):
X=[]
y=[]
for i in range(len(seq)-TIMESTEPS):
X.append([seq[i:i+TIMESTEPS]])
y.append([seq[i+TIMESTEPS]])
return np.array(X,dtype=np.float32),np.array(y,dtype=np.float32)
def lstm_model(X,y,is_training):
#建立多层lstm
cell = tf.nn.rnn_cell.MultiRNNCell([
tf.nn.rnn_cell.BasicLSTMCell(HIDDEN_SIZE) for _ in range(NUM_LAYERS)
])
outputs,_ = tf.nn.dynamic_rnn(cell,X,dtype = tf.float32) #outputs 输出维度是[batch_size,time,hidden_size]
output = outputs[:,-1,:]
#再加一层全连接层
predictions = tf.layers.dense(output,1,activation=None)
if not is_training:
return predictions,None,None
loss = tf.losses.mean_squared_error(labels=y,predictions=predictions)
op = tf.train.AdamOptimizer(learning_rate=0.1)
train_op = op.minimize(loss,tf.train.get_global_step())
return predictions,loss,train_op
def trains(sess,train_X,train_y):
ds = tf.data.Dataset.from_tensor_slices((train_X,train_y))
ds = ds.repeat().shuffle(1000).batch(BATCH_SIZE)
X,y = ds.make_one_shot_iterator().get_next()
with tf.variable_scope("model"):
predictions,loss,train_op = lstm_model(X,y,True)
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
_,l = sess.run([train_op,loss])
if i % 100 == 0:
print("train step: " + str(i)+ ", loss: "+str(l))
def run_eval(sess,test_X,test_y):
ds = tf.data.Dataset.from_tensor_slices((test_X, test_y))
ds = ds.batch(1)
X, y = ds.make_one_shot_iterator().get_next()
with tf.variable_scope("model",reuse=True):
prediction,_,_ = lstm_model(X,[0.0],False)
predictions =[]
labels = []
for i in range(TESTING_EXAMPLES):
p,l = sess.run([prediction,y])
predictions.append(p)
labels.append(l)
#计算rmse作为评价指标
predictions = np.array(predictions).squeeze()
labels = np.array(labels).squeeze()
rmse = np.sqrt(((predictions-labels)**2).mean(axis=0))
print("Mean Square Error is : %f"%rmse)
plt.figure()
plt.plot(predictions,label = "predictions")#labels="predictions"
plt.plot(labels,label='labels')
plt.legend()
plt.show()
def MAIN():
test_start = (TRAINING_EXAMPLES+TIMESTEPS)*SAMPLE_GAP
test_end = test_start+(TESTING_EXAMPLES+TIMESTEPS)*SAMPLE_GAP
train_X,train_y=generate_data(np.sin(np.linspace(0,test_start,TRAINING_EXAMPLES+TIMESTEPS,dtype=np.float32)))
test_X, test_y = generate_data(np.sin(np.linspace(test_start, test_end, TESTING_EXAMPLES + TIMESTEPS, dtype=np.float32)))
with tf.Session() as sess:
trains(sess,train_X,train_y)
run_eval(sess,test_X,test_y)
if __name__ == '__main__':
MAIN()