#数据结构与算法学习笔记#PTA17:哈夫曼树与哈夫曼编码 Huffman Tree & Huffman Code(C/C++)
2018.5.16
最近一段时间忙于实验室各种项目和辅导员的各种杂活,间隔了半周没有耐下心学习。导师最近接了一个要PK京东方的项目让我来做总负责,确实是很惊喜了。责任心告诉我不能把工作做水了,但是还是尝试把实权移交给师兄们比较好。
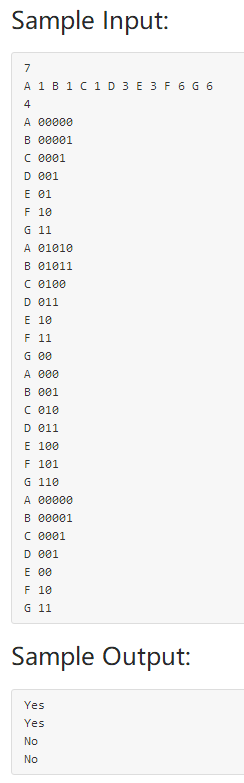
这道题可以说是树这块的压轴题了,无论是代码量还是思维难度都和其他题目不在一个档次。题目意思是给定一个带权的输入序列,和N个与带权输入序列元素相同的编码测试序列,若编码符合最优编码,则输出Yes,若不符合,则输出No。
这道题考察最优编码长度,实际上是在考察Huffman树与Huffman编码,出题人担心你想不到,还特地在题干开头专门介绍了David A. Huffman和他提出的"A Method for the Construction of Minimum-Redundancy Codes"(一种实现最小冗余编码结构的方法),也就是Huffman Codes(哈夫曼编码)。
对于每个给定的带权元素序列来说,其必定可以建成一棵Huffman树,尽管根据建树方法的不同,树的结构不同,但是对于这个给定的带权元素序列,其最优编码长度是固定的,即某一形式的Huffman树下的Huffman编码长度。(建立Huffman树的过程为,每次将权重最小的两个结点合成一棵二叉树,其树根结点权值为两子树权值之合。再将该二叉树当作结点进行重新合并。重复上述过程直到使用完所有结点,建立成一棵树(理论上N个结点要进行N-1次合并))但需要注意的是,Huffman编码的编码长度是最优编码长度,但是最优编码长度可以不是其Huffman编码(题目最后一句也有特地提醒,看来出题人还是比较好心的)。因此,验证输入测试序列需要靠两点:1.符合最优编码长度,2.能够无歧义解码。
那么思路就出来了。先根据输入序列建立Huffman树,并获得最优编码长度。再对提交数据进行检查:1.是否符合最优编码长度,2.是否符合无歧义解码规则(前缀码编码,数据仅存在于二叉树叶节点)。
获得最优编码长度的过程,需要先创建一棵Huffman树,又需要先将带权序列建立成最小堆,再每轮弹出2次最小堆的顶点,作为二叉树的左右子树进行合并,合并完后的二叉树进行权值更新,再继续放入最小堆进行合并……直到最小堆元素全部弹出,最后弹出一整棵Huffman树。(最小堆的建立可以参见:#数据结构与算法学习笔记#PTA14:最小堆与最大堆(C/C++))。计算每一个测试序列的编码长度,与标准Huffman编码长度比较即可。最小堆每次插入和弹出都需要对全堆某个路径(根节点到叶子结点的一条路径)进行一次调整,具体情况分析详见代码注释。
检查前缀码编码的过程,需要根据输入序列的每个元素编码,模拟其在树中的路径(相当于每次创建一个元素编码所代表一条二叉树的路径,0代表左子树,1代表右子树)。模拟过程中的两种情况可以验证不满足前缀码要求(如下图):1.后创建的分支经过或超过已经被定义的叶子结点,2.后创建分支创建结束时未达到叶子结点。具体情况分析详见代码注释。

题目要求:
In 1953, David A. Huffman published his paper "A Method for the Construction of Minimum-Redundancy Codes", and hence printed his name in the history of computer science. As a professor who gives the final exam problem on Huffman codes, I am encountering a big problem: the Huffman codes are NOT unique. For example, given a string "aaaxuaxz", we can observe that the frequencies of the characters 'a', 'x', 'u' and 'z' are 4, 2, 1 and 1, respectively. We may either encode the symbols as {'a'=0, 'x'=10, 'u'=110, 'z'=111}, or in another way as {'a'=1, 'x'=01, 'u'=001, 'z'=000}, both compress the string into 14 bits. Another set of code can be given as {'a'=0, 'x'=11, 'u'=100, 'z'=101}, but {'a'=0, 'x'=01, 'u'=011, 'z'=001} is NOT correct since "aaaxuaxz" and "aazuaxax" can both be decoded from the code 00001011001001. The students are submitting all kinds of codes, and I need a computer program to help me determine which ones are correct and which ones are not.
Input Specification:
Each input file contains one test case. For each case, the first line gives an integer N (2≤N≤63), then followed by a line that contains all the N distinct characters and their frequencies in the following format:
c[1] f[1] c[2] f[2] ... c[N] f[N]
where c[i] is a character chosen from {'0' - '9', 'a' - 'z', 'A' - 'Z', '_'}, and f[i] is the frequency of c[i] and is an integer no more than 1000. The next line gives a positive integer M (≤1000), then followed by M student submissions. Each student submission consists of N lines, each in the format:
c[i] code[i]
where c[i] is the i-th character and code[i] is an non-empty string of no more than 63 '0's and '1's.
Output Specification:
For each test case, print in each line either "Yes" if the student's submission is correct, or "No" if not.
Note: The optimal solution is not necessarily generated by Huffman algorithm. Any prefix code with code length being optimal is considered correct.
实现代码:
// HuffmanCodes.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include
#include
#include
using namespace std;
//Huffman树结点类
class Node {
public:
Node() {}
Node(char element, int weight)
:element(element), weight(weight), left(NULL), right(NULL) {}
char element;
int weight;
Node* left = NULL;
Node* right = NULL;
bool isleave = false;
};
typedef Node* HFMTree;
//输入测试样例结点类
class Case {
public:
char element;
char route[1000];
int length;
int getlength() {
return strlen(this->route);
}
};
void Read(int num, vector& minHeap, vector& inputlist);
void Insert(vector& minHeap, HFMTree node); //插入数据创建最小堆
HFMTree CreateHFMT(vector& minHeap); //根据最小堆创建Huffman树
HFMTree DeleteMinHeap(vector& minHeap); //从最小堆中取出最小元素,删除该结点并重新调整最小堆,最后删除该结点
int getHFMLength(HFMTree hfmtree, int depth); //获得该树编码长度
void Input(vector& testcase, int num);
bool isOptimalLen(vector& testcase, vector& inputlist, int weight); //检查是否符合最优编码长度
bool isPrefixCode(vector& testcase); //检查是否符合前缀码编码
int main()
{
/*根据输入序列建立Huffman树,并获得最优编码长度*/
int num;
cin >> num;
vector minHeap; //创建最小堆,用最小堆对序列进行存储
vector inputlist; //记录输入顺序与权值大小
HFMTree flag = new Node('-', -1);
minHeap.push_back(flag);
Read(num, minHeap, inputlist);
HFMTree hfmtree; //利用最小堆创建Huffman树
hfmtree = CreateHFMT(minHeap);
int optcodelength = getHFMLength(hfmtree, 0); //通过序列创建的Huffman树获得最优编码长度
/*对提交数据进行检查:1.是否符合最优编码长度,2.是否符合无歧义解码规则(前缀码编码,数据仅存在于二叉树叶节点)*/
int count;
cin >> count;
for (int i = 0;i < count;i++) {
vector testcase;
Input(testcase, num);
bool isoptimallen = isOptimalLen(testcase, inputlist, optcodelength);
bool isprefixcode = isPrefixCode(testcase);
if (isoptimallen && isprefixcode) {
cout << "Yes" << endl;
}
else {
cout << "No" << endl;
}
}
system("pause");
return 0;
}
void Read(int num, vector& minHeap, vector& inputlist) {
char element;
int weight;
for (int i = 0; i < num; i++) {
cin >> element >> weight;
HFMTree node = new Node(element, weight);
inputlist.push_back(node);
Insert(minHeap, node);
}
//minHeap.erase(minHeap.begin());
}
void Insert(vector& minHeap, HFMTree node) {
int index = minHeap.size();
minHeap.push_back(node);
//每次插入后自底向上进行调整
while ((*minHeap[index / 2]).weight > (*node).weight) {
//此处不可单纯进行值交换,需要交换两个对象
//(*minHeap[index]).element = (*minHeap[index / 2]).element;
//(*minHeap[index]).weight = (*minHeap[index / 2]).weight;
minHeap[index] = minHeap[index / 2];
index /= 2;
}
minHeap[index] = node;
}
HFMTree CreateHFMT(vector& minHeap) {
HFMTree hfmtree = new Node();
int size = minHeap.size() - 1;
//进行size-1次合并
for (int i = 1; i < size; i++) {
HFMTree node = new Node();
//每次从最小堆中取出堆顶的两个结点作为该结点的左右子结点
node->left = DeleteMinHeap(minHeap);
node->right = DeleteMinHeap(minHeap);
node->weight = node->left->weight + node->right->weight;
//将该结点作为根节点的二叉树重新加入最小堆
Insert(minHeap, node);
}
//从最小堆中取出建好的Huffman树
hfmtree = DeleteMinHeap(minHeap);
return hfmtree;
}
HFMTree DeleteMinHeap(vector& minHeap) {
//检查是否堆空
if (minHeap.size() == 1) {
return NULL;
}
//将该堆最大元素装入新结点并返回
HFMTree node = new Node();
node = minHeap[1];
//重新调整该堆
int size = minHeap.size();
int parent, child;
//用最大堆中最后一个元素从根结点开始向上过滤下层结点
HFMTree cmp = new Node();
cmp = minHeap[size - 1];
//从根节点开始,用parent记录根结点下标,用child记录其最小子结点下标,每次循环将parent更新为上一次循环的child
//当parent指向底层结点时跳出循环(会有极端情况比如偏向一边的堆使得parent最终并非指向该子树底层结点,但不影响结果)
for (parent = 1; 2 * parent < size; parent = child) {
child = parent * 2;
//若该子结点不是堆尾结点,令child指向左右子结点中的较小者
if ((child != size - 1) && ((*minHeap[child]).weight > (*minHeap[child + 1]).weight)) {
child++;
}
//当循环到堆尾结点值小于等于该子结点值时,可以结束(此时堆尾结点会替换parent结点而不是child结点)
if (cmp->weight <= (*minHeap[child]).weight) {
break;
}
else {
minHeap[parent] = minHeap[child];
}
}
//将尾结点与当前父结点替换
minHeap[parent] = cmp;
//删除堆尾结点
//此处不能用minHeap.erase(minHeap.end());,因为erase会返回被删除结点的下一结点,而尾结点的下一结点超限
minHeap.pop_back();
//返回该结点
return node;
}
int getHFMLength(HFMTree hfmtree, int depth) {
//若为叶子节点,直接返回其编码长度
if (!hfmtree->left && !hfmtree->right) {
return hfmtree->weight * depth;
}
//否则其他节点一定有两个子树,返回左右子树编码长度之合,深度相应加一
else {
return getHFMLength(hfmtree->left, depth + 1) + getHFMLength(hfmtree->right, depth + 1);
}
}
void Input(vector& testcase, int num) {
for (int i = 0;i < num;i++) {
Case inputcase;
cin >> inputcase.element >> inputcase.route;
inputcase.length = inputcase.getlength();
testcase.push_back(inputcase);
}
}
bool isOptimalLen(vector& testcase, vector& inputlist, int weight) {
int testweight = 0;
for (int i = 0;i < testcase.size();i++) {
testweight += (testcase[i].length * (*inputlist[i]).weight);
}
if (testweight == weight) {
return true;
}
else {
return false;
}
}
bool isPrefixCode(vector& testcase) {
bool isprefixcode = true;
HFMTree newtree = new Node();
//两种情况验证不满足前缀码要求:1.后创建的分支经过或超过已经被定义的叶子结点,2.后创建分支创建结束时未达到叶子结点
for (int i = 0;i < testcase.size();i++) {
HFMTree point = newtree;
if (isprefixcode == false)break;
for (int j = 0;j < testcase[i].length;j++) {
if (isprefixcode == false)break;
if (testcase[i].route[j] == '0') {
//先检查左子结点是否存在,若不存在,则创建一个左子结点
if (!point->left) {
HFMTree newnode = new Node();
point->left = newnode;
point = point->left;
//若此时为分支的最后一环,则将该结点定义为叶子结点
if (j == testcase[i].length - 1) {
point->isleave = true;
}
}
//若左子树存在,则先将标记指针移至左子树。
else {
point = point->left;
//若左子树为叶子结点,则不符合要求
if (point->isleave) {
isprefixcode = false;
break;
}
//若此时为分支的最后一环且仍有叶子结点,则不符合要求
if ((j == testcase[i].length - 1) && (point->left || point->right)) {
isprefixcode = false;
break;
}
}
}
else if (testcase[i].route[j] == '1') {
//先检查右子结点是否存在,若不存在,则创建一个右子结点
if (!point->right) {
HFMTree newnode = new Node();
point->right = newnode;
point = point->right;
//若此时为分支的最后一环,则将该结点定义为叶子结点
if (j == testcase[i].length - 1) {
point->isleave = true;
}
}
//若左子树存在,则先将标记指针移至左子树。
else {
point = point->right;
//若左子树为叶子结点,则不符合要求
if (point->isleave) {
isprefixcode = false;
break;
}
//若此时为分支的最后一环且仍有叶子结点,则不符合要求
if ((j == testcase[i].length - 1) && (point->left || point->right)) {
isprefixcode = false;
break;
}
}
}
}
}
return isprefixcode;
} #Coding一小时,Copying一秒钟。留个言点个赞呗,谢谢你#