arm汇编解析——qnnpack卷积实现
目录
前言
基础直通车
arm基础知识
arm指令释义
qnn汇编代码解析
前言
最近在移植QNNPACK神经网络加速库,涉及到对卷积arm汇编的修改,这边做个记录,对汇编部分的内容进行注释,顺便学习一下汇编的语法。
基础直通车
首先要补充arm汇编基础知识,特别是如何传参一定要搞清楚,另外对arm寄存器要了然于胸,剩下的就是指令的用法了:
利用堆栈入参参考:https://www.cnblogs.com/qq78292959/p/4013356.html
arm 32位NEON寄存器:https://blog.csdn.net/SoaringLee_fighting/article/details/81743505
ARM汇编器对ARM的寄存器预定义:https://blog.csdn.net/SoaringLee_fighting/article/details/81287824
ARM汇编指令:https://blog.csdn.net/zhangmiaoping23/article/details/8875193
arm基础知识
R0-R15和r0-r15
a1-a4(参数,结果或者临时寄存器,与r0-r3同意)
v1-v8(变量寄存器,与r4-r11同意)
sb和SB(静态基址寄存器,与r9同意)
sl和SL(堆栈限制寄存器,与r10同意)
fp和FP(帧指针,与r11同意)
ip和IP(过程调用中间临时寄存器,与r12同意)
sp和SP(堆栈指针,与r13同意)
lr和LR(连接寄存器,与r14同意)
pc和PC(程序计数器,与r15同意)
cpsr和CPSR(程序状态寄存器)
spsr和SPSR(程序状态寄存器)
f0-f7和F0-F7(FPA寄存器)
s0-s31和S0-S31(VFP单精度寄存器)
d0-d15和D0-D15(VFP双精度寄存器)
p0-p15(协处理器0-15)
c0-c15(协处理器寄存器0-15)
使用说明:
1、当参数少于4个时,子程序间通过寄存器R0~R3来传递参数;当参数个数多于4个时,将多余的参数通过数据栈进行传递,入栈顺序与参数顺序正好相反,子程序返回前无需恢复R0~R3的值;
2、在子程序中,使用R4~R11保存局部变量,若使用需要入栈保存,子程序返回前需要恢复这些寄存器;R12是临时寄存器,使用不需要保存。
3、R13用作数据帧指针,记作SP;R14用作链接寄存器,记作LR,用于保存子程序返回时的地址;R15是程序计数器,记作PC。
4、ATPCS规定堆栈是满递减堆栈FD;
5、子程序返回32位的整数,使用R0返回;返回64位整数时,使用R0返回低位,R1返回高位。
Arm32位寄存器主要分为ARM寄存器和NEON寄存器。
ARM32寄存器包括15个通用寄存器R0~R14和一个程序计数器PC,共16个,均为32位宽。
ARM32位寄存器的调用规则:遵循ATPCS调用规则
32位 NEON寄存器:
包括:32个S寄存器,S0~S31,(单字,32bit)
32个D寄存器,D0~D31,(双字,64bit)
16个Q寄存器,Q0~Q15,(四字,128bit)
寄存器的对应关系如下图所示:
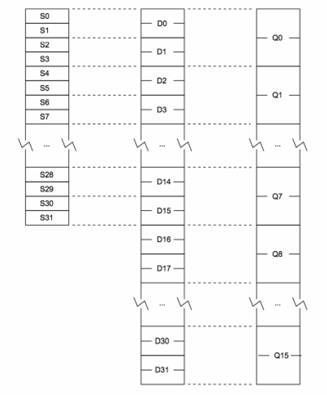
使用说明:
1、NEON寄存器将每个寄存器均视为一个向量,该向量又包含1,2,4,8或16个大小和类型均相同的元素。也可以将各个元素当做标量访问。
NEON的这三种寄存器是重叠的,物理地址是一样的。
2、NEON寄存器在使用时,如果用到d8~d15寄存器,需要先入栈保存vpush {d8-d15},使用完之后要出栈vpop {d8-d15}
arm指令释义
条件分支:
CMP:算数处理指令,用于把一个寄存器的内容和另一个寄存器的内容或立即数进行减法比较,不存储结果,都会更改标志位
BNE: 数据跳转指令,标志寄存器中Z标志位不等于零时, 跳转到BNE后标签处
BNE 3f 0b f:forward,b:backward
BEQ: 数据跳转指令,标志寄存器中Z标志位等于零时, 跳转到BEQ后标签处
BLO指令 小于(无符号数)跳转
数据加载及存储:
ldr ip,[sp],#4 将sp中内容存入ip,之后sp=sp+4;
ldr ip,[sp,#4] 将sp+4这个新地址下内容存入ip,之后sp值保持不变
ldr ip,[sp,#4]!将sp+4这个新地址下内容存入ip,之后sp=sp+4将新地址值赋给sp
str ip,[sp],#4 将ip存入sp地址处,之后sp=sp+4;
str ip,[sp,#4] 将ip存入sp+4这个新地址,之后sp值保持不变
str ip,[sp,#4]!将ip存入sp+4这个新地址,之后sp=sp+4将新地址值赋给sp
qnn汇编代码解析
先对BEGIN_FUNCTION定义说明:
#ifdef __ELF__ //linux系统编译宏
.macro BEGIN_FUNCTION name
.text
.align 2
.global \name
.type \name, %function
\name:
.endm
.macro END_FUNCTION name
.size \name, .-\name
.endm
#elif defined(__MACH__) //ios/machos系统编译宏
.macro BEGIN_FUNCTION name
.text
.align 2
.global _\name
.private_extern _\name
_\name:
.endm
.macro END_FUNCTION name
.endm
#endif
卷积汇编代码:
/*
* Copyright (c) Facebook, Inc. and its affiliates.
* All rights reserved.
*
* This source code is licensed under the BSD-style license found in the
* LICENSE file in the root directory of this source tree.
*/
.include "assembly.h"
.syntax unified
# void q8conv_ukernel_4x8__aarch32_neon(
# size_t mr,
# size_t nr,
# size_t kc,
# size_t ks,
# const uint8_t**restrict a, ###### r8 [sp, 96] ,3
# const void*restrict w, ###### ip [sp, 4] ,1
# uint8_t*restrict c, -> int32_t*restrict c, ###### r2, r3, [sp, 104] ,4
# size_t c_stride,
# const union qnnp_conv_quantization_params quantization_params[restrict static 1]) ###### r9 [sp, 112] ,2
#关于参数说明:从a开始的参数因为超过了4个,采用堆栈方式传参,从最后一个参数params入栈,入栈方式为满减栈(从上往下递减)
BEGIN_FUNCTION q8conv_ukernel_4x8__aarch32_neon
.arm
#ifndef __APPLE__
.arch armv7-a
.fpu neon
#endif
# Load w
# - ip = w
# ip==r12:temp register; sp==r13:top stack;
# ip=sp+4=w,the 4 is size of ptr a(地址偏移都以字节为单位)
LDR ip, [sp, 4]
PUSH {r4, r5, r6, r7, r8, r9, r10, r11} #压入栈中保存r4-r11的值。r4-r11用作局部变量
VPUSH {d8-d15} #压栈保存
# Load bias0123, bias4567
VLDM ip!, {d16-d19} # load bias:8xint32 = 4x64(d16-d19)
# Load params:
# - r9 = params
LDR r9, [sp, 112] #sizeof(r4-r11) + sizeof(d8-d15) +sizeof(a+w+c+c_stride)=32/8*8+64/8*8+4*4=112
# q10 := vacc1x0123
VMOV.I32 q10, q8 # mov 32x4 bias t0 q10(sizeof(q8)==128 bits)
MOV r4, 4
# q11 := vacc1x4567
VMOV.I32 q11, q9 # 将q9中的4个32赋值为q11
# Load a
# - r8 = a
LDR r8, [sp, 96] #sizeof(r4-r11) + sizeof(d8-d15) = 32/8*8 + 64/8*8=96
# q12 := vacc2x0123
VMOV.I32 q12, q8
# q13 := vacc2x4567
VMOV.I32 q13, q9
# q14 := vacc3x0123
VMOV.I32 q14, q8
# Load b_zero_point:
# - d15 = b_zero_point
VLD1.8 {d15[]}, [r9], r4 # mov the value from r9 to all d15(per 8bit); r9=r9+r4(per 8bit)
# q15 := vacc3x4567
VMOV.I32 q15, q9
# Load multiplier:
# - d12 = vmultiplier
VLD1.32 {d12[]}, [r9]!
.p2align 5
0:
SUBS r10, r2, 8
# Load a0, a1, a2, a3
# - r4 = a0
# - r5 = a1
# - r6 = a2
# - r7 = a3
LDM r8!, {r4-r7}
BLO 2f
1:
# Load va0
# - d1 = va0
VLD1.8 {d1}, [r4]!
# Load va1
# - d3 = va1
VLD1.8 {d3}, [r5]!
# Load vb0-vb7 (channel 0)
# - d9 = vb0-vb7
VLD1.8 {d9}, [ip:64]!
# Load va2
# - d5 = va2
VLD1.8 {d5}, [r6]!
# q0 = va0 = a0
VMOVL.U8 q0, d1
# Load va3
# - d7 = va3
VLD1.8 {d7}, [r7]!
# q1 = va1 = a1
VMOVL.U8 q1, d3
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 0)
# - d9 = vb4567 (channel 0)
VSUBL.U8 q4, d9, d15
# q2 = va2 = a2
VMOVL.U8 q2, d5
# q3 = va3 = a3
VMOVL.U8 q3, d7
### Channel 0 ###
# Load b0-b7 (channel 1)
# - d11 = b0-b7
VLD1.8 {d11}, [ip:64]!
# vacc0x0123 += vb0123 * va0[0]
VMLAL.S16 q8, d8, d0[0]
# vacc0x4567 += vb4567 * va0[0]
VMLAL.S16 q9, d9, d0[0]
# vacc1x0123 += vb0123 * va1[0]
VMLAL.S16 q10, d8, d2[0]
# vacc1x4567 += vb4567 * va1[0]
VMLAL.S16 q11, d9, d2[0]
# vacc2x0123 += vb0123 * va2[0]
VMLAL.S16 q12, d8, d4[0]
# vacc2x4567 += vb4567 * va2[0]
VMLAL.S16 q13, d9, d4[0]
# q5 = b0:7 - vb_zero_point
# - d10 = vb0123 (channel 1)
# - d11 = vb4567 (channel 1)
VSUBL.U8 q5, d11, d15
# vacc3x0123 += vb0123 * va3[0]
VMLAL.S16 q14, d8, d6[0]
# vacc3x4567 += vb4567 * va3[0]
VMLAL.S16 q15, d9, d6[0]
### Channel 1 ###
# Load b0-b7 (channel 2)
# - d9 = b0-b7
VLD1.8 {d9}, [ip:64]!
# vacc0x0123 += vb0123 * va0[1]
VMLAL.S16 q8, d10, d0[1]
# vacc0x4567 += vb4567 * va0[1]
VMLAL.S16 q9, d11, d0[1]
# vacc1x0123 += vb0123 * va1[1]
VMLAL.S16 q10, d10, d2[1]
# vacc1x4567 += vb4567 * va1[1]
VMLAL.S16 q11, d11, d2[1]
# vacc2x0123 += vb0123 * va2[1]
VMLAL.S16 q12, d10, d4[1]
# vacc2x4567 += vb4567 * va2[1]
VMLAL.S16 q13, d11, d4[1]
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 2)
# - d9 = vb4567 (channel 2)
VSUBL.U8 q4, d9, d15
# vacc3x0123 += vb0123 * va3[1]
VMLAL.S16 q14, d10, d6[1]
# vacc3x4567 += vb4567 * va3[1]
VMLAL.S16 q15, d11, d6[1]
### Channel 2 ###
# Load b0-b7 (channel 3)
# - d11 = b0-b7
VLD1.8 {d11}, [ip:64]!
# vacc0x0123 += vb0123 * va0[2]
VMLAL.S16 q8, d8, d0[2]
# vacc0x4567 += vb4567 * va0[2]
VMLAL.S16 q9, d9, d0[2]
# vacc1x0123 += vb0123 * va1[2]
VMLAL.S16 q10, d8, d2[2]
# vacc1x4567 += vb4567 * va1[2]
VMLAL.S16 q11, d9, d2[2]
# vacc2x0123 += vb0123 * va2[2]
VMLAL.S16 q12, d8, d4[2]
# vacc2x4567 += vb4567 * va2[2]
VMLAL.S16 q13, d9, d4[2]
# q5 = b0:7 - vb_zero_point
# - d10 = vb0123 (channel 3)
# - d11 = vb4567 (channel 3)
VSUBL.U8 q5, d11, d15
# vacc3x0123 += vb0123 * va3[2]
VMLAL.S16 q14, d8, d6[2]
# vacc3x4567 += vb4567 * va3[2]
VMLAL.S16 q15, d9, d6[2]
### Channel 3 ###
# Load b0-b7 (channel 4)
# - d9 = b0-b7
VLD1.8 {d9}, [ip:64]!
# vacc0x0123 += vb0123 * va0[3]
VMLAL.S16 q8, d10, d0[3]
# vacc0x4567 += vb4567 * va0[3]
VMLAL.S16 q9, d11, d0[3]
# vacc1x0123 += vb0123 * va1[3]
VMLAL.S16 q10, d10, d2[3]
# vacc1x4567 += vb4567 * va1[3]
VMLAL.S16 q11, d11, d2[3]
# vacc2x0123 += vb0123 * va2[3]
VMLAL.S16 q12, d10, d4[3]
# vacc2x4567 += vb4567 * va2[3]
VMLAL.S16 q13, d11, d4[3]
# q5 = b0:7 - vb_zero_point
# - d10 = vb0123 (channel 4)
# - d11 = vb4567 (channel 4)
VSUBL.U8 q4, d9, d15
# vacc3x0123 += vb0123 * va3[3]
VMLAL.S16 q14, d10, d6[3]
# vacc3x4567 += vb4567 * va3[3]
VMLAL.S16 q15, d11, d6[3]
### Channel 4 ###
# Load b0-b7 (channel 5)
# - d11 = b0-b7
VLD1.8 {d11}, [ip:64]!
# vacc0x0123 += vb0123 * va0[4]
VMLAL.S16 q8, d8, d1[0]
# vacc0x4567 += vb4567 * va0[4]
VMLAL.S16 q9, d9, d1[0]
# vacc1x0123 += vb0123 * va1[4]
VMLAL.S16 q10, d8, d3[0]
# vacc1x4567 += vb4567 * va1[4]
VMLAL.S16 q11, d9, d3[0]
# vacc2x0123 += vb0123 * va2[4]
VMLAL.S16 q12, d8, d5[0]
# vacc2x4567 += vb4567 * va2[4]
VMLAL.S16 q13, d9, d5[0]
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 5)
# - d9 = vb4567 (channel 5)
VSUBL.U8 q5, d11, d15
# vacc3x0123 += vb0123 * va3[4]
VMLAL.S16 q14, d8, d7[0]
# vacc3x4567 += vb4567 * va3[4]
VMLAL.S16 q15, d9, d7[0]
### Channel 5 ###
# Load b0-b7 (channel 6)
# - d9 = b0-b7
VLD1.8 {d9}, [ip:64]!
# vacc0x0123 += vb0123 * va0[5]
VMLAL.S16 q8, d10, d1[1]
# vacc0x4567 += vb4567 * va0[5]
VMLAL.S16 q9, d11, d1[1]
# vacc1x0123 += vb0123 * va1[5]
VMLAL.S16 q10, d10, d3[1]
# vacc1x4567 += vb4567 * va1[5]
VMLAL.S16 q11, d11, d3[1]
# vacc2x0123 += vb0123 * va2[5]
VMLAL.S16 q12, d10, d5[1]
# vacc2x4567 += vb4567 * va2[5]
VMLAL.S16 q13, d11, d5[1]
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 6)
# - d9 = vb4567 (channel 6)
VSUBL.U8 q4, d9, d15
# vacc3x0123 += vb0123 * va3[5]
VMLAL.S16 q14, d10, d7[1]
# vacc3x4567 += vb4567 * va3[5]
VMLAL.S16 q15, d11, d7[1]
### Channel 6 ###
# Load b0-b7 (channel 7)
# - d11 = b0-b7
VLD1.8 {d11}, [ip:64]!
# vacc0x0123 += vb0123 * va0[6]
VMLAL.S16 q8, d8, d1[2]
# vacc0x4567 += vb4567 * va0[6]
VMLAL.S16 q9, d9, d1[2]
# vacc1x0123 += vb0123 * va1[6]
VMLAL.S16 q10, d8, d3[2]
# vacc1x4567 += vb4567 * va1[6]
VMLAL.S16 q11, d9, d3[2]
# vacc2x0123 += vb0123 * va2[6]
VMLAL.S16 q12, d8, d5[2]
# q5 = b0:7 - vb_zero_point
# - d10 = vb0123 (channel 7)
# - d11 = vb4567 (channel 7)
VSUBL.U8 q5, d11, d15
# vacc2x4567 += vb4567 * va2[6]
VMLAL.S16 q13, d9, d5[2]
# vacc3x0123 += vb0123 * va3[6]
VMLAL.S16 q14, d8, d7[2]
# vacc3x4567 += vb4567 * va3[6]
VMLAL.S16 q15, d9, d7[2]
### Channel 8 ###
SUBS r10, r10, 8
# vacc0x0123 += vb0123 * va0[7]
VMLAL.S16 q8, d10, d1[3]
# vacc0x4567 += vb4567 * va0[7]
VMLAL.S16 q9, d11, d1[3]
# vacc1x0123 += vb0123 * va1[7]
VMLAL.S16 q10, d10, d3[3]
# vacc1x4567 += vb4567 * va1[7]
VMLAL.S16 q11, d11, d3[3]
# vacc2x0123 += vb0123 * va2[7]
VMLAL.S16 q12, d10, d5[3]
# vacc2x4567 += vb4567 * va2[7]
VMLAL.S16 q13, d11, d5[3]
# vacc3x0123 += vb0123 * va3[7]
VMLAL.S16 q14, d10, d7[3]
# vacc3x4567 += vb4567 * va3[7]
VMLAL.S16 q15, d11, d7[3]
BHS 1b
2:
CMP r10, -8
BEQ 3f
# Adjust a0, a1, a2, a3
ADD r4, r10
ADD r5, r10
ADD r6, r10
ADD r7, r10
# a_shift = 8 * k - 64
LSL r10, r10, 3
VDUP.32 d13, r10
# Load va0
# - d1 = va0
VLD1.8 {d1}, [r4]
# Load va1
# - d3 = va1
VLD1.8 {d3}, [r5]
# Load b0-b7 (channel 0)
# - d9 = b0-b7
VLD1.8 {d9}, [ip:64]!
# Load a2
# - d5 = a2
VLD1.8 {d5}, [r6]
# q0 = va0 = a0
VSHL.U64 d1, d1, d13
VMOVL.U8 q0, d1
# Load a3
# - d7 = a3
VLD1.8 {d7}, [r7]
# q1 = va1 = a1
VSHL.U64 d3, d3, d13
VMOVL.U8 q1, d3
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 0)
# - d9 = vb4567 (channel 0)
VSUBL.U8 q4, d9, d15
# q2 = va2 = a2
VSHL.U64 d5, d5, d13
VMOVL.U8 q2, d5
# q3 = va3 = a3
VSHL.U64 d7, d7, d13
VMOVL.U8 q3, d7
### Channel 0 ###
# vacc0x0123 += vb0123 * va0[0]
VMLAL.S16 q8, d8, d0[0]
# vacc0x4567 += vb4567 * va0[0]
VMLAL.S16 q9, d9, d0[0]
# vacc1x0123 += vb0123 * va1[0]
VMLAL.S16 q10, d8, d2[0]
# vacc1x4567 += vb4567 * va1[0]
VMLAL.S16 q11, d9, d2[0]
# vacc2x0123 += vb0123 * va2[0]
VMLAL.S16 q12, d8, d4[0]
# vacc2x4567 += vb4567 * va2[0]
VMLAL.S16 q13, d9, d4[0]
# vacc3x0123 += vb0123 * va3[0]
VMLAL.S16 q14, d8, d6[0]
# vacc3x4567 += vb4567 * va3[0]
VMLAL.S16 q15, d9, d6[0]
CMP r10, -48
BLO 3f
### Channel 1 ###
# Load b0-b7 (channel 1)
# - d11 = b0-b7
VLD1.8 {d11}, [ip:64]!
# q5 = b0:7 - vb_zero_point
# - d10 = vb0123 (channel 1)
# - d11 = vb4567 (channel 1)
VSUBL.U8 q5, d11, d15
# vacc0x0123 += vb0123 * va0[1]
VMLAL.S16 q8, d10, d0[1]
# vacc0x4567 += vb4567 * va0[1]
VMLAL.S16 q9, d11, d0[1]
# vacc1x0123 += vb0123 * va1[1]
VMLAL.S16 q10, d10, d2[1]
# vacc1x4567 += vb4567 * va1[1]
VMLAL.S16 q11, d11, d2[1]
# vacc2x0123 += vb0123 * va2[1]
VMLAL.S16 q12, d10, d4[1]
# vacc2x4567 += vb4567 * va2[1]
VMLAL.S16 q13, d11, d4[1]
# vacc3x0123 += vb0123 * va3[1]
VMLAL.S16 q14, d10, d6[1]
# vacc3x4567 += vb4567 * va3[1]
VMLAL.S16 q15, d11, d6[1]
### Channel 2 ###
BLS 3f
# Load b0-b7 (channel 2)
# - d9 = b0-b7
VLD1.8 {d9}, [ip:64]!
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 2)
# - d9 = vb4567 (channel 2)
VSUBL.U8 q4, d9, d15
# vacc0x0123 += vb0123 * va0[2]
VMLAL.S16 q8, d8, d0[2]
# vacc0x4567 += vb4567 * va0[2]
VMLAL.S16 q9, d9, d0[2]
# vacc1x0123 += vb0123 * va1[2]
VMLAL.S16 q10, d8, d2[2]
# vacc1x4567 += vb4567 * va1[2]
VMLAL.S16 q11, d9, d2[2]
# vacc2x0123 += vb0123 * va2[2]
VMLAL.S16 q12, d8, d4[2]
# vacc2x4567 += vb4567 * va2[2]
VMLAL.S16 q13, d9, d4[2]
# vacc3x0123 += vb0123 * va3[2]
VMLAL.S16 q14, d8, d6[2]
# vacc3x4567 += vb4567 * va3[2]
VMLAL.S16 q15, d9, d6[2]
### Channel 3 ###
CMP r10, -32
BLO 3f
# Load b0-b7 (channel 3)
# - d9 = b0-b7
VLD1.8 {d11}, [ip:64]!
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 3)
# - d9 = vb4567 (channel 3)
VSUBL.U8 q5, d11, d15
# vacc0x0123 += vb0123 * va0[3]
VMLAL.S16 q8, d10, d0[3]
# vacc0x4567 += vb4567 * va0[3]
VMLAL.S16 q9, d11, d0[3]
# vacc1x0123 += vb0123 * va1[3]
VMLAL.S16 q10, d10, d2[3]
# vacc1x4567 += vb4567 * va1[3]
VMLAL.S16 q11, d11, d2[3]
# vacc2x0123 += vb0123 * va2[3]
VMLAL.S16 q12, d10, d4[3]
# vacc2x4567 += vb4567 * va2[3]
VMLAL.S16 q13, d11, d4[3]
# vacc3x0123 += vb0123 * va3[3]
VMLAL.S16 q14, d10, d6[3]
# vacc3x4567 += vb4567 * va3[3]
VMLAL.S16 q15, d11, d6[3]
### Channel 4 ###
BLS 3f
# Load b0-b7 (channel 4)
# - d11 = b0-b7
VLD1.8 {d9}, [ip:64]!
# q5 = b0:7 - vb_zero_point
# - d10 = vb0123 (channel 4)
# - d11 = vb4567 (channel 4)
VSUBL.U8 q4, d9, d15
# vacc0x0123 += vb0123 * va0[4]
VMLAL.S16 q8, d8, d1[0]
# vacc0x4567 += vb4567 * va0[4]
VMLAL.S16 q9, d9, d1[0]
# vacc1x0123 += vb0123 * va1[4]
VMLAL.S16 q10, d8, d3[0]
# vacc1x4567 += vb4567 * va1[4]
VMLAL.S16 q11, d9, d3[0]
# vacc2x0123 += vb0123 * va2[4]
VMLAL.S16 q12, d8, d5[0]
# vacc2x4567 += vb4567 * va2[4]
VMLAL.S16 q13, d9, d5[0]
# vacc3x0123 += vb0123 * va3[4]
VMLAL.S16 q14, d8, d7[0]
# vacc3x4567 += vb4567 * va3[4]
VMLAL.S16 q15, d9, d7[0]
### Channel 5 ###
CMP r10, -16
BLO 3f
# Load b0-b7 (channel 5)
# - d13 = b0-b7
VLD1.8 {d11}, [ip:64]!
# q5 = b0:7 - vb_zero_point
# - d10 = vb0123 (channel 5)
# - d11 = vb4567 (channel 5)
VSUBL.U8 q5, d11, d15
# vacc0x0123 += vb0123 * va0[5]
VMLAL.S16 q8, d10, d1[1]
# vacc0x4567 += vb4567 * va0[5]
VMLAL.S16 q9, d11, d1[1]
# vacc1x0123 += vb0123 * va1[5]
VMLAL.S16 q10, d10, d3[1]
# vacc1x4567 += vb4567 * va1[5]
VMLAL.S16 q11, d11, d3[1]
# vacc2x0123 += vb0123 * va2[5]
VMLAL.S16 q12, d10, d5[1]
# vacc2x4567 += vb4567 * va2[5]
VMLAL.S16 q13, d11, d5[1]
# vacc3x0123 += vb0123 * va3[5]
VMLAL.S16 q14, d10, d7[1]
# vacc3x4567 += vb4567 * va3[5]
VMLAL.S16 q15, d11, d7[1]
### Channel 6 ###
BLS 3f
# Load b0-b7 (channel 6)
# - d9 = b0-b7
VLD1.8 {d9}, [ip:64]!
# q4 = b0:7 - vb_zero_point
# - d8 = vb0123 (channel 6)
# - d9 = vb4567 (channel 6)
VSUBL.U8 q4, d9, d15
# vacc0x0123 += vb0123 * va0[6]
VMLAL.S16 q8, d8, d1[2]
# vacc0x4567 += vb4567 * va0[6]
VMLAL.S16 q9, d9, d1[2]
# vacc1x0123 += vb0123 * va1[6]
VMLAL.S16 q10, d8, d3[2]
# vacc1x4567 += vb4567 * va1[6]
VMLAL.S16 q11, d9, d3[2]
# vacc2x0123 += vb0123 * va2[6]
VMLAL.S16 q12, d8, d5[2]
# vacc2x4567 += vb4567 * va2[6]
VMLAL.S16 q13, d9, d5[2]
# vacc3x0123 += vb0123 * va3[6]
VMLAL.S16 q14, d8, d7[2]
# vacc3x4567 += vb4567 * va3[6]
VMLAL.S16 q15, d9, d7[2]
.p2align 4
3:
SUBS r3, r3, 1
BNE 0b
# Load c, c_stride:
# - r2 = c
# - r3 = c_stride
LDRD r2, r3, [sp, 104]
# r3 = c_stride*4;
MOV r3, r3, LSL 2
ADD r4, r2, r3
CMP r0, 2
#if r0<2 r4=r2
MOVLO r4, r2
ADD r5, r4, r3
#if r0==2 r5=r4
MOVLS r5, r4
CMP r0, 4
ADD r3, r5, r3
#if r0!=4 r3=r5
MOVNE r3, r5
CMP r1, 8
BNE 5f
VST1.I32 {d16-d19}, [r2]
VST1.I32 {d20-d23}, [r4]
VST1.I32 {d24-d27}, [r5]
VST1.I32 {d28-d31}, [r3]
VPOP {d8-d15}
POP {r4, r5, r6, r7, r8, r9, r10, r11}
BX lr
.p2align 3
5:
CMP r1, 4
BLO 6f
VST1.32 {d16-d17}, [r2:128]!
VST1.32 {d20-d21}, [r4:128]!
VST1.32 {d24-d25}, [r5:128]!
VST1.32 {d28-d29}, [r3:128]!
SUB r1, 4
VMOV.I32 q8, q9
VMOV.I32 q10, q11
VMOV.I32 q12, q13
VMOV.I32 q14, q15
6:
CMP r1, 2
BLO 7f
VST1.32 {d16}, [r2:64]!
VST1.32 {d20}, [r4:64]!
VST1.32 {d24}, [r5:64]!
VST1.32 {d28}, [r3:64]!
SUB r1, 2
VEXT.32 q8, q8, q8, 2
VEXT.32 q10, q10, q10, 2
VEXT.32 q12, q12, q12, 2
VEXT.32 q14, q14, q14, 2
7:
TEQ r1, 0
BEQ 8f
VST1.32 {d16}, [r2]
VST1.32 {d20}, [r4]
VST1.32 {d24}, [r5]
VST1.32 {d28}, [r3]
8:
VPOP {d8-d15}
POP {r4, r5, r6, r7, r8, r9, r10, r11}
BX lr #bx lr 的作用等同于 mov pc,lr 即跳转到lr中存放的地址处
END_FUNCTION q8conv_ukernel_4x8__aarch32_neon
#ifdef __ELF__
.section ".note.GNU-stack","",%progbits
#endif