深度学习笔记(1)——神经网络(neural network)
神经网络是机器学习中的一种经典模型,也是现在深度学习的前身和基础,因此如果要想掌握深度学习,必须通透地了解神经网络。关于神经网络需要做到以下几点:了解神经网络的线性结构,了解非线性激活函数,掌握参数训练的反向传播算法(BP, backpropagation),了解多层神经网路的梯度弥散问题。
神经元和感知机
神经网络是由一个个基本的神经元组合而成的,而这些神经元模拟人脑中神经细胞,拥有若干个输入和输出(对应树突和轴突),通常在学术界我们将其称为感知机。下面是神经元的图片

对于一个神经元细胞,拥有接受信号的树突和输出信号的轴突,根据这种模式,学者设计一个输入输出模式的单元,并命名为感知机:
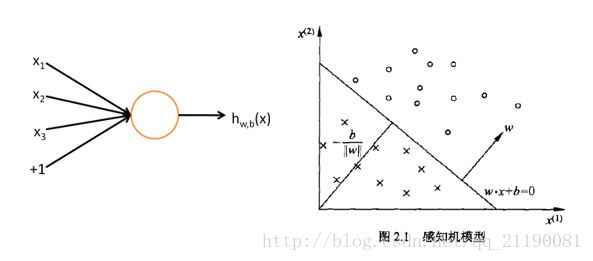
输入表示为 X=[x1,x2,x3,...,xi]T ,对于输入 xi 有一个权重系数 wi ,表示为 W=[w1,w2,w3,...,wi] ,另外加一个常数偏置 b ,为了实现二分类,最后的输出写作:
其中sign表示符号函数,这是一个很典型的线性分类方式。如上图的右侧,假如在二维平面,存在一条直线 y=WX+b ,那么这条直线就可以把空间分为两部分,分别对应 WX+b>0 和 WX+b<0 两部分。而对于高维空间,这条直线就变成了一个超平面,将空间同样分为大于0和小于0两部分。但是仍然只能实现线性分类,为了实现非线性分类,学者在感知机后面加入一个非线性单元——激活函数。在神经网络刚出来的时候,常用的激活函数有sigmoid函数和tanh,它们的公式为:
他们的曲线表示为
左边为sigmoid函数,值域范围为[0,1],右边为tanh函数,值域范围[-1,1],通过多个这样的非线性感知机,那么理论上我们最终可以逼近任意一个超曲面,如果这个非线性的激活函数我们只能得到一个由若干个超平面组合而成多边形超平面。那么为什么选择这些激活函数了,我们不妨以sigmoid函数为例,求一下sigmoid的导数:
所以sigmoid函数的导数可以用自身来表示,有兴趣的读者不妨自己推导tanh的导数,是否也满足这一个规律。这一点对于编程实现非常重要,可以得到导数的解析解而不是数值解,因为神经网络的训练都是基于梯度(导数)实现的。
多层前馈神经网络
之前我们已经介绍了单个神经元(感知机),我们仿照人脑神经系统,把这些神经元给全连接起来,便可以得到一个多层感知机 (Multi-layer Perceptron, MLP),也叫做多层神经网络。在多层神经网络中,第一层叫做输入层(input layer),最后一层叫做输出层(output layer),中间的都叫做隐层(hidden layer),下面是一个单隐层神经网络的教材例子

从输入到输出的过程是把数值从低层传向高层,这个过程叫做前馈传播。两层神经元之间都有一条线连接,这条线代表着这两个神经元之间的权重系数。 w(1)ij 表示输入层第 i 个神经元到隐层第 j 个神经元的权重系数, b(1) 代表输入层到隐层的偏置, w(2)ij 表示隐层第 i 个神经元到输出层第 j 个神经元的权重系数, b(2) 代表隐层到输出层的偏置,上图的输出层只有一个神经元。其中 w(1)ij 的所有集用 w1 表示,是个二维矩阵,同理 w(2)ij 的所有集用 w2 ,最终待训练的参数集 (W,b)=(w(1),b(1),w(2),b(2)) ,隐层的神经元先接受来自输入层的数值:
然后经过激活函数 f() 得到该神经元的隐含值:
同理,输出层神经元的输出也可以得到:
单隐层单输出的神经网络拓展到更一般的形式,输入层和输出层也可以当做第一层和最后一层来看待,和上面类似,我们有权重系数 w(l)ij ,其中 l 代表第 l 到 l+1 层, i 代表第 l+1 的第 i 个神经元, j 代表第 l 的第 j 个神经元,另外 b(l) 表示第 l 到 l+1 层的偏置。最后前馈传播的公式可以表示为:
利用这个传播公式,我们就可以从输入x得到输出的值了,那么接下来的问题就是如何去训练得到最优的参数集 (W,b) 。
反向传播算法(back propagation, BP)
前面我们已经介绍了神经网络的正向传播,现在我们给神经网络输入一个 x ,便可以得到一个预测值 hw,b(x) ,但是我们现在面对的问题便是要如何训练参数集 (W,b) ,解决这个问题的方法就是反向传播算法,简写为BP算法。BP算法是一种基于梯度下降的优化方法,基本原理有点向下山,我们的目标是找到目标函数的最小值。目标函数的分布曲面就好像一个山脉,我们想要去山脉的最低点,最简单的做法就是沿着下山的方向不停走,梯度下降法就是基于这种原理,函数的梯度方向的反方向就是下山最快的方向,所以只要求出函数的梯度,我们就可以渐渐向函数的最小值逼近。为了训练神经网络,首先我们要定义一个损失函数
其中
这里我们把神经网络的输出层看作网络的第 l+1 层, y 是输入样本 x 的真实标签, f() 是激活函数。之后我们便可以损失函数 J 求第 l 层到输出层的参数集 (W(l),b(l)) 的梯度
同理
其中
前面已经介绍,如果 f() 是sigmoid函数的话,那么
至此损失函数 J 关于 w(l)ij 和 b(l) 的梯度解析解全部可以求出来,并且不需要“求导”,这主要得益于激活函数导数可以用自身表达的这种性质,可以发现即使到了深度学习的各种激活函数,其导数可以简单的计算这种特性依然保留。根据导数的链式法则,我们可以得到递推公式
用这个公式一路递推过去便可以求得每一层的梯度,之后利用更新公式便可以不停地更新参数
其中 α 表示学习率,属于人工设定的参数,来控制学习的步长(一次下山的幅度)。在现在流行的bp算法中,已经有很多自适应学习率的算法产生。
实际程序
如今神经网络的程序API已经非常多了,python、matlab和C等主流语言都有许多库包,用户只要设定神经网络的层数、每层网络的神经元数、激活函数、优化函数、学习率等参数便可以很方便地使用,下面给出一个基于深度学习框架keras的程序
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('sigmoid'))
model.add(Dense(10))
model.add(Activation('softmax'))上面便是一个两层神经网络的例子,Dense层即神经网络层,只要指定数据输入的维度和神经元个数即可,第一层输入784,输出32,说明第一层为784个神经元,第二层为32个神经元,同理第三层输出层为10个神经元,激活函数分别为sigmoid何softmax函数(输入层是不需要激活函数的)。具体细节可以去查阅keras官方文档。