CDH集群中关于HBase的优化
1. 垃圾回收优化
1)首先是设置新生代大小的参数,不能过小,过小则导致年轻代过快成为老生代,引起老生代产生内存随便。同样不能过大,过大导致所有的JAVA进程停止时间长。-XX:MaxNewSize=256m-XX:NewSize=256m这两个可以合并成为-Xmn256m这一个配置来完成。
2)其次是设置垃圾回收策略:-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
3)设置CMS的值,占比多少时,开始并发标记和清扫检查。-XX:CMSInitiatingOccupancyFraction=70
以上三个参数cdh配置位置如下图:(其中也包括 Thrift Server的java参数配置同理
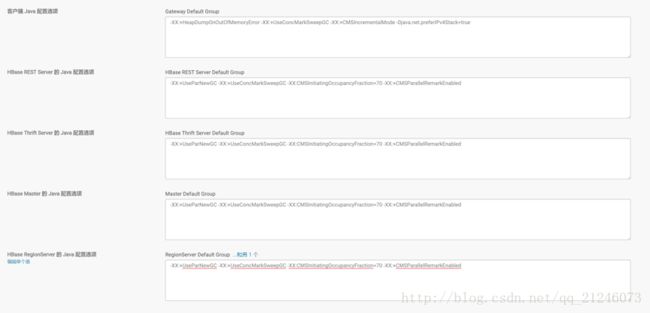
4)hbase.hregion.memstore.mslab.enabled默认值:true,这个是在hbase-site.xml中进行配置的值。
说明:减少因内存碎片导致的Full GC,提高整体性能。
备注:避免频繁的内存碎片化导致的新生代GC到老年代GC,到最终导致的oom
2. 启用压缩
目前hbase默认支持的压缩算法包括GZ,LZO以及snappy(0.92版本已经支持,BSD license)
Algorithm % remaining Encoding Decoding
GZIP 13.4% 21 MB/s 118 MB/s
LZO 20.5% 135 MB/s 410 MB/s
Zippy/Snappy 22.2% 172 MB/s 409MB/s
根据你产品的情况选取这里压缩算法或是使用其他压缩算法。
配置方法:(以配置LZO为例)
参照以下步骤:
1 首先要让系统支持lzo动态库,安装lzo-2.00以上版本:http://www.oberhumer.com/opensource/lzo/download/
2 默认安装完后应该在系统的/usr/local/lib/找到liblzo*等几个so
3 到http://code.google.com/p/hadoop-gpl-compression/下载lzo相关的native库
4 拷贝3中下载的 hadoop-gpl-compression-0.1.0-dev.jar或hadoop-gpl-compression-0.1.0.jar 到 hbase/lib以及hadoop/lib 中
5 拷贝3中下载的 lib/native/*到hadoop/lib/native 及 hbase/lib/native
6 确保以上4/5中的文件同步到了每台regionserver上
7 在core-site.xml中加上:
3. 优化Region拆分合并以及与拆分Region
(1) hbase.hregion.max.filesize默认为256M(在hbase-site.xml中进行配置),当region达到这个阈值时,会自动拆分。
(2) 手动打散region,主要通过对数据的分析,自定义region的分割规则,例:
creat 'xxxx','info',SPLITS=> ['01xxxxx','1xxxxxxx','2xxxxxx','3xxxxxxx']
4. 客户端入库调优
(1) 用户在编写程序入库时,HBase的自动刷写是默认开启的,即用户每一次put都会提交到HBase server进行一次刷写,如果需要高速插入数据,则会造成I/O负载过重。在这里可以关闭自动刷写功能,setAutoFlush(false)。如此,put实例会先写到一个缓存中,这个缓存的大小通过hbase.client.write.buffer这个值来设定缓存区,当缓存区被填满之后才会被送出。
(2) 第二个方法,是关闭每次put上的WAL(writeToWAL(flase))这样可以刷写数据前,不需要预写日志,但是如果数据重要的话建议不要关闭。
(3) base.client.scanner.caching:默认为10000
这是设计客户端读取数据的配置调优,在hbase-site.xml中进行配置,代表scanner一次缓存多少数据(从服务器一次抓取多少数据来scan)默认的太小,但是对于大文件,值不应太大。
(4) hbase.regionserver.lease.period默认值:60000
说明:客户端租用HRegion server 期限,即超时阀值。
调优:这个配合hbase.client.scanner.caching使用,如果内存够大,但是取出较多数据后计算过程较长,可能超过这个阈值,适当可设置较长的响应时间以防被认为宕机
5. HBase配置文件
(1) zookeeper.session.timeout(默认3分钟)
ZK的超期参数,默认配置为3分钟,在生产环境上建议减小这个值在1分钟或更小。
设置原则:这个值越小,当RS故障时Hmaster获知越快,Hlog分裂和region 部署越快,集群恢复时间越短。 但是,设置这个值得原则是留足够的时间进行GC回收,否则会导致频繁的RS宕机。一般就做默认即可
(2) hbase.regionserver.handler.count(默认25)
对于大负载的put(达到了M范围)或是大范围的Scan操作,handler数目不易过大,易造成OOM。 对于小负载的put或是get,delete等操作,handler数要适当调大。根据上面的原则,要看我们的业务的情况来设置。(具体情况具体分析)。
(3) hbase.hregion.memstore.flush.size
单个region内所有的memstore大小总和超过指定值时,flush该region的所有memstore
(4) hbase.hstore.blockingStoreFiles 默认值:7
说明:在flush时,当一个region中的Store(CoulmnFamily)内有超过7个storefile时,则block所有的写请求进行compaction,以减少storefile数量。
调优:block写请求会严重影响当前regionServer的响应时间,但过多的storefile也会影响读性能。从实际应用来看,为了获取较平滑的响应时间,可将值设为无限大。如果能容忍响应时间出现较大的波峰波谷,那么默认或根据自身场景调整即可。
(5) hbase.hregion.memstore.block.multiplier默认值:2
说明:当一个region里总的memstore占用内存大小超过hbase.hregion.memstore.flush.size两倍的大小时,block该region的所有请求,进行flush,释放内存。
虽然我们设置了region所占用的memstores总内存大小,比如64M,但想象一下,在最后63.9M的时候,我Put了一个200M的数据,此时memstore的大小会瞬间暴涨到超过预期的hbase.hregion.memstore.flush.size的几倍。这个参数的作用是当memstore的大小增至超过hbase.hregion.memstore.flush.size2倍时,block所有请求,遏制风险进一步扩大。
调优: 这个参数的默认值还是比较靠谱的。如果你预估你的正常应用场景(不包括异常)不会出现突发写或写的量可控,那么保持默认值即可。如果正常情况下,你的写请求量就会经常暴长到正常的几倍,那么你应该调大这个倍数并调整其他参数值,比如hfile.block.cache.size和hbase.regionserver.global.memstore.upperLimit/lowerLimit,以预留更多内存,防止HBase serverOOM。
Block块大小设置
hbase.hregion.memstore.block.multiplier(内存充足确保不会产生OOM的情况下,调大此值 )
hbase.hstore.blockingStoreFiles(HStore的storeFile的文件数大于配置值,则在flushmemstore前先进行split或者compact,除非超过hbase.hstore.blockingWaitTime配置的时间,默认为7,可调大,比如:100,避免memstore不及时flush,当写入量大时,触发memstore的block,从而阻塞写操作。)