《KyLin学习理解》-01-KyLin麒麟的简介及其思想
1。诞生背景
HIVE是数据仓库,是把存储在HDFS分布式文件系统的存储文件映射到类似于关系型数据库的东西。
举个例子:
假设有一个文件存储在本地/opt/hzjs/lcc_work/pro.txt文件,文件的格式为
1 产品120 23 5 115 358 2069-03-27
2 产品16 63 3 189 9 2045-04-27
3 产品924 22 8 176 25 2067-08-26
4 产品956 86 6 516 24 2073-02-28
5 产品254 41 5 205 802 2038-06-23
6 产品170 97 2 194 573 2096-07-22
7 产品814 21 8 168 841 2096-07-27
8 产品426 80 5 400 935 2076-05-27
9 产品463 51 2 102 735 2026-03-27上面的字段分别的意思是
ID 商品名称 价格 购买数量 付款 类别ID 时间
假设有另外一个文件存储在本地/opt/hzjs/lcc_work/cate.txt文件,文件的格式为
1 类别1
2 类别2
3 类别3
4 类别4
5 类别5
6 类别6
7 类别7
8 类别8
9 类别9
10 类别10上面的字段分别的意思是
ID 类别名称
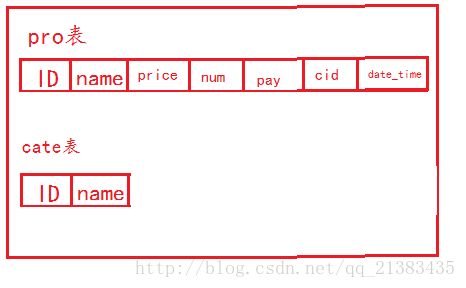
现在HIVE中建立一个表名字叫user,里面有这些字段。
drop table pro;
create table pro(
id bigint,
name string,
price int,
num int,
pay int,
cid bigint,
date_time string)
row format delimited fields terminated by '\t' stored as textfile;
create table cate(
id bigint,
name string)
row format delimited fields terminated by '\t' stored as textfile;
然后在HIVE里生成了两个表,分别是cate,pro。
HIVE表中存储的是这样的:只是存储元数据,也就是表结构。表的字段名称和字段类型。
现在我们要往HIVE里存储数据。
load data local inpath '/opt/hzjs/lcc_work/pro.txt' overwrite into table pro;
load data local inpath '/opt/hzjs/lcc_work/cate.txt' overwrite into table cate;这个时候数据存储就类似于这样了
所以从这里可以看到。hive实际上操作的是HDFS上的文件,既然是文件,打开文件的操作是很慢的。而且你一定有这样的经历,打开一个很大的文件可能会卡死机器,而大数据操作更是很多的数据。因此我们需要一个能即时查询的系统。而KyLin就应用而生。
KyLin可以以很以亚秒查询数据。因此很适合查询分析。
2.KyLin是什么?
Kylin是一个大数据平台的类似的BI大数据分析的一个东西。主要是提供亚秒级查询的一个大数据平台。
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
3.KyLin的核心思想是什么?
KyLin的核心思想是以空间换时间。核心技术是预计算。
那么我们先讲讲什么是预计算,预计算顾名思义就是预先计算。
比方说我们一个系统分析所有的用户操作后,一共有这么多查询语句
《1》select count(*) from pro;
《2》select name,count(name),sum(num) as shuliang ,sum(pay) from pro as newpropro group by name order by shuliang desc;
《3》select cid,cate.name,sum(num) as amount from pro inner join cate on pro.cid=cate.id group by pro.cid,cate.name order by amount desc;
《4》select cid, cate.name, sum(pay) as paysum from pro inner join cate on pro.cid=cate.id group by cid,cate.name order by paysum desc;
《5》select name,sum(num) as c_num,date_time from pro group by name,date_time order by c_num desc limit 20;这些语句如果在HIVE里查询会需要很久。(最下面有我做的一个1000条数据和10000条数据测试的文档)
我们能不能这样想,如果我们事先把所有这些要查询SQL语句的结果都保存起来,那么以后查询的时候直接不去查询原始HIVE里的数据,直接去查询预计算的结果,这样的话本来要查询几亿条数据,现在只需要查询一两条就可以了,速度会非常快。
那么第二个问题来了。一个系统我们不可能只有这些查询语句,可能会很多,各种查询都可能会出现。如果预计算事先没有做预查询,那么久查询不到结果,为了解决这个问题,我们必须引入以空间换时间的概念,既然我们不知道要查询什么,我们可以把所有的查询语句都事先查询出结果,保存起来。但是如果是查询出的是LIST集合,那么数据会急剧增长。所以是以空间换区查询时间。
4。kylin的Model和CUBE理解
首先要理解两个概念,第一个是Model的概念,第二个是CUBE的概念。
Mode的概念:
Model就是筛选的概念。数学上概念是数据模型。如何理解呢?
为什么会有Model数据模型的概念呢?
假设一个系统,查询一些数据,可能在数据库里一个表有100个字段,如果另外一个表也有80个字段,但是我们要计算的时候,只有其中一两个字段,但是我们却把所有的字段都参与查询中,这是不划算的。
比如说原始数据HIVE中的存储格式为。
1 产品120 23 5 115 358 2069-03-27
2 产品16 63 3 189 9 2045-04-27
3 产品924 22 8 176 25 2067-08-26
4 产品956 86 6 516 24 2073-02-28
5 产品254 41 5 205 802 2038-06-23
6 产品170 97 2 194 573 2096-07-22
7 产品814 21 8 168 841 2096-07-27
8 产品426 80 5 400 935 2076-05-27
9 产品463 51 2 102 735 2026-03-27 这是原始数据。但是在计算的时候,比方说我们想要知道某个类别下的商品买的最多。这里只涉及了 购买数量 类别ID 两个字段。我们要查询的时候如果只使用这两个字段会节省很多存储空间。
比如Model设计为
ID 商品名称 价格 购买数量 付款 类别ID不要了时间。那么看下面
再来看看如何Model的的作用。model的作用就是,在设计好Model后。Kylin会首先根据Model抽取数据,格式如下
1 产品120 23 5 115 358
2 产品16 63 3 189 9
3 产品924 22 8 176 25
4 产品956 86 6 516 24
5 产品254 41 5 205 802
6 产品170 97 2 194 573
7 产品814 21 8 168 841
8 产品426 80 5 400 935
9 产品463 51 2 102 735 这就根据Model筛选出来需要参加业务处理的数据,而不参加的会被去除,这些数据抽取出来的数据我也不知道是否存储到HBASE中了没。
然后下面来看看CUBE的概念,在Model的前提下,假设有这些查询语句
《1》select count(*) from pro;
《2》select name,count(name),sum(num) as shuliang ,sum(pay) from pro as newpropro group by name order by shuliang desc;
《3》select cid,cate.name,sum(num) as amount from pro inner join cate on pro.cid=cate.id group by pro.cid,cate.name order by amount desc;
《4》select cid, cate.name, sum(pay) as paysum from pro inner join cate on pro.cid=cate.id group by cid,cate.name order by paysum desc;
《5》select name,sum(num) as c_num,date_time from pro group by name,date_time order by c_num desc limit 20;五个查询语句,每个都会产生一个结果,可能只是一个数,也可能是一个集合,但是每个都是一个cubeid.把所有的查询结果都合并在一起就是一个CUBE。包含了尽可能的查询语句的结果。
Model和CUBE的设计,如何设计呢?
设计Model和CUBE的时候,不是瞎设计的,这个需要看业务。比方说有以下几个业务处理。
(1)查询总共有多少条商品数据?
(2)查询 每种商品 卖了多少单,多少件,卖了多少钱?
(3)查看哪一类商品买的数量最多?
(4)查看某类商品 一共买了多少钱?
(5) 查看某天买的商品最多?那么我们看看业务处理。
(1)查询总共有多少条商品数据?
SQL:select count(*) from pro;
分析:这条语句只要有任何一个字段都可以查询到。
(2)查询 每种商品 卖了多少单,多少件,卖了多少钱?
SQL:select name,sum(num) as shuliang ,sum(pay) from pro as newpropro group by name order by shuliang desc;
分析:这里涉及到字段name,num,pay三个字段
涉及函数有:sum(num) ,sum(pay)
(3)查看哪一类商品买的数量最多?
SQL:select cid,cate.name,sum(num) as amount from pro inner join cate on pro.cid=cate.id group by pro.cid,cate.name order by amount desc;
分析:这里涉及到字段cid,cate.name,num,cate.id三个字段
涉及函数有:sum(num)
(4)查看某类商品 一共买了多少钱?
SQL:select cid, cate.name, sum(pay) as paysum from pro inner join cate on pro.cid=cate.id group by cid,cate.name order by paysum desc;
分析:这里涉及到字段cid,cate.name,pay,cate.id三个字段
涉及函数有:sum(pay)
(5)查看某天买的商品最多?
SQL:select name,sum(num) as c_num,date_time from pro group by name,date_time order by c_num desc limit 20;
分析:这里涉及到字段name,num,pay,date_time 三个字段
涉及函数有:sum(num)
因此从上面解释下来就是:
涉及到的字段是
pro表的
字段: ID 商品名称 价格 购买数量 付款 类别ID 时间
聚合函数:sum(num) ,sum(pay)
cate表的
字段:ID 类别名称
聚合函数:无
因此设计Model的时候,要全部都添加进入。设计CUBE的时候,添加聚合函数sum(num) ,sum(pay)
下一章是界面截图设计Model和CUBE.
http://blog.csdn.net/qq_21383435/article/details/75221127