Hive文件格式
文章目录
- 1.概述
- 1.1 行存储 列存储
- 2. TEXTFILE
- 3. SEQUENCEFILE
- 3. RCFILE
- 4. ORCFILE
- 5. Parquet
- 8.区别
- 8.1 空间对比,磁盘空间占用大小比较
- 8.2 查询语句运行时间大小比较
- 9 总结:
1.概述
hive文件存储格式包括以下几类:
| 名称 | 出现的版本 | 特点 |
|---|---|---|
| TEXTFILE | 文本,默认值 | |
| SEQUENCEFILE | 二进制序列文件 | |
| RCFILE | Hive0.6以后开始支持 | 列式存储格式文件 |
| ORCFILE | 0.11以后出现 | 列式存储格式文件,比RCFILE有更高的压缩比和读写效率 |
| Parquet | Hive0.13以后开始支持 | 列出存储格式文件 |
| 自定义格式 |
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入SequenceFile,RCFile,ORCFile表中。
1.1 行存储 列存储

行存储的特点查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
2. TEXTFILE
textfile为默认格式,存储方式为行存储。
案例
create table mergrez4 (id int,name string ) ;
或者
create table if not exists testfile_table( site string, url string, pv bigint, label string) row format delimited fields terminated by '\t' stored as textfile;
load data local inpath '/app/weibo.txt' overwrite into table textfile_table;
缺点:
- 默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
- 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
create table if not exists textfile_table(
site string,
url string,
pv bigint,
label string
)
row format delimited
fields terminated by '\t'
stored as textfile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table textfile_table select * from textfile_table;
查看占用的磁盘空间
hadoop dfs -du -h hdfs://localhost:9002/user/hive/warehouse/yyz_workdb.db/textfile
3. SEQUENCEFILE
- SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
- SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。
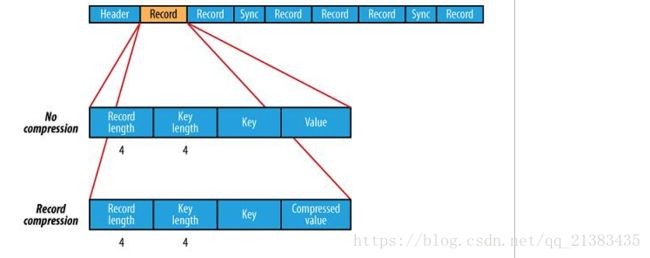
Header通用头文件格式:
| SEQ | 3BYTE |
| Nun | 1byte数字 |
| keyClassName | |
| ValueClassName | |
| compression | (boolean)指明了在文件中是否启用压缩 |
| blockCompression | (boolean,指明是否是block压缩) |
| compression | codec |
| Metadata | 文件元数据 |
| Sync | 头文件结束标志 |
create table if not exists seqfile_table(
site string,
url string,
pv bigint,
label string)
row format delimited
fields terminated by '\t'
stored as sequencefile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
SET mapred.output.compression.type=BLOCK;
insert overwrite table seqfile_table select * from textfile_table;
3. RCFILE
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
hive/spark都支持这种存储格式,它存储的方式是采用数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。特点是数据压缩率非常高。

RCFILE文件示例:
create table if not exists rcfile_table(
site string,
url string,
pv bigint,
label string
)
row format delimited
fields terminated by '\t'
stored as rcfile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from textfile_table;
4. ORCFILE
注意:ORCFILE(0.11以后出现),而且星环版本的0.12也是不支持的
但是开源版本,0.12也是不支持的
lcc@lcc hive-0.12.0-bin$ hive
Logging initialized using configuration in jar:file:/Users/lcc/soft/hive/hive-0.12.0-bin/lib/hive-common-0.12.0.jar!/hive-log4j.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/Users/lcc/soft/hadoop/hadoop-2.7.4/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/Users/lcc/soft/hive/hive-0.12.0-bin/lib/slf4j-log4j12-1.6.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
hive> show databases;
OK
default
Time taken: 8.081 seconds, Fetched: 1 row(s)
hive> CREATE TABLE IF NOT EXISTS rubin_demo2 ( userid BIGINT, context STRING, time STRING) PARTITIONED BY ( ds STRING )STORED AS ORCFILE;
FAILED: SemanticException Unrecognized file format in STORED AS clause: ORCFILE
hive>
星环的hive-0.12(以及开源版本) 支持这样的
create table if not exists test_orc(
advertiser_id string,
ad_plan_id string,
cnt BIGINT
) partitioned by (day string, type TINYINT COMMENT '0 as bid, 1 as win, 2 as ck', hour TINYINT)
STORED AS ORC;
hive 2.1.0是支持ORCFILE的
0: jdbc:hive2://localhost:10014/default> CREATE TABLE IF NOT EXISTS rubin_demo1 ( userid BIGINT, context STRING, time STRING) PARTITIONED BY ( ds STRING )STORED AS ORCFILE;
No rows affected (2.59 seconds)
0: jdbc:hive2://localhost:10014/default> show tables;
+--------------+--+
| tab_name |
+--------------+--+
| rubin_demo1 |
+--------------+--+
1 row selected (0.843 seconds)
0: jdbc:hive2://localhost:10014/default>
5. Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
create table orders (id int,name string,version int,year string,month string,day string)
row format delimited fields terminated by ',' stored as parquet
8.区别
8.1 空间对比,磁盘空间占用大小比较

orc8.2 查询语句运行时间大小比较
语句:select id from parquet limit 30;
结果:orc
这个大小趋势适用于较大的数据,在数据量较小的情况下,可能会出现与之相悖的结论
9 总结:
textfile是默认格式,加载速度最快,存储空间消耗比较大,可以采用Gzip进行压缩,并且压缩的text 无法分割和合并 查询的效率最低,可以直接存储,加载数据的速度最高sequencefile压缩率最低,查询速度一般, 存储空间消耗最大,压缩的文件可以分割和合并 查询效率高,需要通过text文件转化来加载,三种压缩格式NONE,RECORD,BLOCK。是可分割的文件格式。rcfile存储空间最小,查询的效率最高,数据加载最慢。 需要通过text文件转化来加载。相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
在hive中使用压缩需要灵活的方式,如果是数据源的话,采用RCFile+bz或RCFile+gz的方式,这样可以很大程度上节省磁盘空间;而在计算的过程中,为了不影响执行的速度,可以浪费一点磁盘空间,建议采用RCFile+snappy的方式,这样可以整体提升hive的执行速度。至于lzo的方式,也可以在计算过程中使用,只不过综合考虑(速度和压缩比)还是考虑snappy适宜。