Python网络爬虫(四):视频下载器
这一节实现一个下载 iqiyi VIP视频的爬虫。
需要的准备:旋风视频VIP解析网站或其他解析网站
原理理解:
在视频解析网站获取视频的过程中,首先会向视频服务器发送GET请求,获得服务器发来的信息;接到信息后,再向服务器POST数据,即将类似于密码的数据上传给服务器;服务器验证信息后,返回所请求的视频地址信息。视频网站根据该地址信息获得视频的资源地址(即在服务器上的缓存地址),打开该地址即可进行播放。
爬虫的实现:
一. 获得视频的资源地址
- 视频解析地址:http://api.xfsub.com/index.php?url=[播放地址或视频id];
- 利用fildder对该地址进行抓包;
- 找到 POST /xfsub_api/url.php HTTP/1.1 项,查看json中的内容:
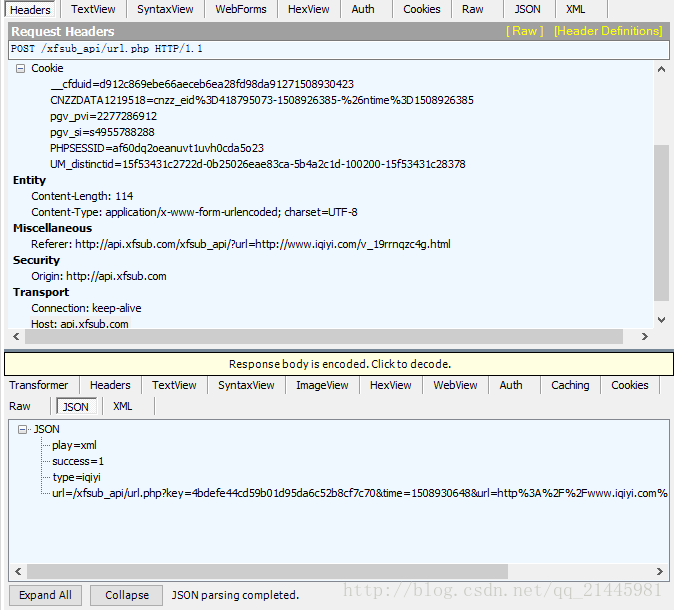
- 对3中所获得的地址进行处理:在前面加上域名;去掉转义内容,即%的内容,加上相应的分隔符;
如:
url=/xfsub_api/url.php?key=4bdefe44cd59b01d95da6c52b8cf7c70&time=1508930648&url=http%3A%2F%2Fwww.iqiyi.com%2Fv_19rrnqzc4g.html&type=iqiyi&xml=1
变成:
http://api.xfsub.com/xfsub_api/url.php?key=4bdefe44cd59b01d95da6c52b8cf7c70&time=1508930648&url=http://www.iqiyi.com/v_19rrnqzc4g.html&type=iqiyi&xml=1 - 打开4中所获的地址,得到了视频的缓存地址,即资源地址。
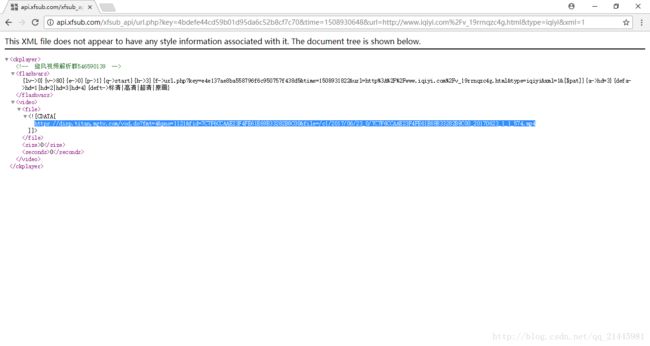
- 利用该资源地址就可以轻松下载视频了。
二、根据资源地址下载视频
这里采用urllib.request.urlretrieve()函数进行下载。
urlretrieve函数的使用方法:
(详见http://www.nowamagic.net/academy/detail/1302861)
urlretrieve() 函数用于直接将远程数据下载到本地。
urlretrieve(url, filename=None, reporthook=None, data=None)
参数说明:
*参数 finename 指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
*参数 reporthook 是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
*参数 data 指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
实例:
# urlretrieve_test.py
# encoding:utf-8
import urllib
import os
def Schedule(a,b,c):
'''
回调函数:用于显示下载进度
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100 :
per = 100
print '%.2f%%' % per
url = 'http://www.python.org/ftp/python/2.7.5/Python-2.7.5.tar.bz2'
#local = url.split('/')[-1]
local = os.path.join('/data/software','Python-2.7.5.tar.bz2')
urllib.urlretrieve(url,local,Schedule)
######output######
#0.00%
#0.07%
#0.13%
#0.20%
#....
#99.94%
#100.00%
split()函数和os.path.split()
split():拆分字符串。通过指定分隔符对字符串进行切片,并返回分割后的字符串列表(list)
os.path.split():按照路径将文件名和路径分割开
1、split()函数
str.split(str=”“,num=string.count(str))[n]
参数说明:
str: 表示为分隔符,默认为空格,但是不能为空(”)。若字符串中没有分隔符,则把整个字符串作为列表的一个元素
num:表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量
[n]: 表示选取第n个分片
注意:当使用空格作为分隔符时,对于中间为空的项会自动忽略
2、os.path.split()函数
os.path.split(‘PATH’)
参数说明:
PATH指一个文件的全路径作为参数:
如果给出的是一个目录和文件名,则输出路径和文件名
如果给出的是一个目录名,则输出路径和为空文件名
代码整理:
参考文章:http://blog.csdn.net/c406495762/article/details/78123502
# video_downloader.py
import requests,re, json, sys
from bs4 import BeautifulSoup
from urllib import request
class video_downloader():
def __init__(self, url):
#*****这些url是从抓包软件中获得的*****
self.server = 'http://api.xfsub.com' #解析网站域名
self.api = 'http://api.xfsub.com/xfsub_api/?url='
self.get_url_api = 'http://api.xfsub.com/xfsub_api/url.php'#post信息发往的服务器
self.url = url.split('#')[0] #去掉多余的字符串
self.target = self.api + url
self.s = requests.session() #身份证,用来持续访问服务器
"""
函数说明:获取key、time、url等参数(POST给服务器)
"""
def get_key(self):
req = self.s.get(url=self.target) #获得解析网站发送的key等信息
req.encoding = 'utf-8' #编码
self.info = json.loads(re.findall('"url.php",\ (.+),', req.text)[0]) #json.loads用于将json格式数据转换为python格式,是个字典
"""
函数说明:获取视频地址
"""
def get_url(self):
data = {'time':self.info['time'],
'key':self.info['key'],
'url':self.info['url'],
'type':''}
req = self.s.post(url=self.get_url_api,data=data) #将key等发送给另外一个服务器
url = self.server + json.loads(req.text)['url'] #服务器返回一个json文件
req = self.s.get(url) #再对新网址发送请求命令
bf = BeautifulSoup(req.text,'xml') #返回xml文件 #因为文件是xml格式的,所以要进行xml解析。
video_url = bf.find('file').string #获得视频地址 #匹配到视频地址
return video_url
#**********以上两步相当于把解析网址申请视频的过程用代码进行了一遍********
"""
函数说明:回调函数,打印下载进度
"""
def Schedule(self, a, b, c):
per = 100.0*a*b/c
if per > 100 :
per = 1
sys.stdout.write(" " + "%.2f%% 已经下载的大小:%ld 文件大小:%ld" % (per,a*b,c) + '\r')
sys.stdout.flush()
"""
函数说明:视频下载
"""
def video_download(self, url, filename):
request.urlretrieve(url=url,filename=filename,reporthook=self.Schedule)
if __name__ == '__main__':
url = 'http://www.iqiyi.com/v_19rrnqzc4g.html#vfrm=19-9-0-1'
filename = '王牌特工:特工学院'
vd = video_downloader(url)
print('%s下载中:' % filename)
vd.get_key()
video_url = vd.get_url()
print(' 获取地址成功:%s' % video_url)
vd.video_download(video_url, filename+'.mp4')
print('\n下载完成!')
注:
程序在idle中运行时,下载速度很慢很慢;而在windows命令行中运行,则下载的较快,500多M大概几分钟下完。