基于kubernetes的efk日志系统架构
EFK由ElasticSearch、Fluentd和Kiabana三个开源工具组成。其中Elasticsearch是一款分布式搜索引擎,能够用于日志的检索,Fluentd是一个实时开源的数据收集器,而Kibana 是一款能够为Elasticsearch 提供分析和可视化的 Web 平台。这三款开源工具的组合为日志数据提供了分布式的实时搜集与分析的监控系统。
而在此之前,业界是采用ELK(Elasticsearch + Logstash + Kibana)来管理日志。Logstash是一个具有实时渠道能力的数据收集引擎,但和fluentd相比,它在效能上表现略逊一筹,性能较差,JVM容易导致内存使用量高,故而逐渐被fluentd取代,ELK也随之变成EFK。
EFK架构
Fluentd是一个开源的数据收集器,专为处理数据流设计,使用JSON作为数据格式。它采用了插件式的架构,具有高可扩展性高可用性,同时还实现了高可靠的信息转发。
因此,我们加入Fluentd来收集日志。
fluentd的使用
最常见的方式就是 source 收集日志,然后由串联的 filter 做流式的处理,最后交给 match 进行分发。
同时你还可以用 label 将任务分组,用 error 处理异常,用 system 修改运行参数。
1、source
source 是 fluentd 的一切数据的来源,每一个 source 内都包含一个输入模块,比如原生集成的包含 http 和 forward 两个模块,分别用来接收 HTTP 请求和 TCP 请求:
当然,除了这两个外,fluentd 还有大量的支持各种协议或方式的 source 插件,比如最常用的 tail 就可以帮你追踪文件。
每一个具体的插件都包含其特有的参数,比如上例中 port 就是一个参数,当你要使用一个 source 插件的时候,注意看看有哪些参数是需要配置的,然后将其写到 source directive 内。
source dirctive 在获取到输入后,会向 fluent 的路由抛出一个事件,这个事件包含三个要素:
- tag
- time
- record
例如 我的source:
@type tail
@id ofs
format json
path /var/log/containers/ofs-pre*.log
pos_file /var/log/ofs.posg
tag ofs
time_format %Y-%m-%dT%H:%M:%S.%NZ
read_from_head true
- @type:用于指定插件类型;
- @id:指定插件 id,在输出监控信息的时候有用;
- format : 使用json进行格式化输入
- path : 监控的日志路径(因docker产生的日志都是json格式的故format使用json)
- pos_file :记录上次读取的位置记录到此文件中
- read_from_head:从头部开始读取日志
- tag :指定tag 用于后续filter match
因为日志都是以行的形式被分成多个json 如果直接将source的日志输入到ElasticSearch,通过kibana去展示的时候 不便于查看日志,实用性不高。例如java的堆栈信息都是多行的,所以这里我们要用concat这个插件将多个json合并在一起之后输入到ElasticSearch,并且通过查看日志的格式,我们可以知道所有日志的开头都是日期开头的,所以我们只要保证日期开头的日志是同一条日志,那么问题就解决了
将source收到的json日志做以下处理:
@type concat
timeout_label @NORMAL
flush_interval 120s #这里需要处理好超时时间,也就是当匹配开始之后到匹配结束的时间
key log #收到 的json格式的key为log的value值
stream_identity_key container_id
multiline_start_regexp /\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}(.|,)\d{3}/ #匹配多行的开始 这里没有multiline_end_regexp 的规则是英文 结束的时候没有很好的匹配规则,所以只当开始的规则匹配才会生成一条完整的日志,如果没有出现下一条开始规则的日志 那么当120s后自动丢弃改日志
@type copy #copy插件
@type forward #转发插件 将匹配到的内容转发到本机的fluentd端口 做第二层解析
send_timeout 30s #发送日志超时时间
recover_wait 10s #服务器故障恢复等待时间
hard_timeout 60s #用于检测服务器故障硬等待时间
heartbeat_type tcp #心跳类型 必须设置为tcp 不然当出现大量数据的时候会出现丢失数据的问题
heartbeat_interval 1s
phi_threshold 8 #用于检测服务器故障的阀值参数 这个参数和heartbeat_interval 密切相关 如果使用更大的phi_threshold 必须设置 更大的heartbeat_interval
host 0.0.0.0
port 24225
weight 60
第二层解析(主要用于解析java日志):
@type parser
key_name log
reserve_data true
@type multiline #多行插件
format_firstline /\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}(,|.)\d{3}/ #匹配开头 解决多行匹配
format1 /^(?
keep_time_key true #保留时间字段
之后需要将结果输出到ElasticSearch 以下配置就很简单了 不需要讲解了
@type elasticsearch
@id out_es
@log_level info
include_tag_key true
host "elasticsearch-api"
port "9200"
scheme "http"
ssl_verify "false"
reload_connections "true"
logstash_prefix "java"
logstash_format true
type_name fluentd
flush_thread_count "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_THREAD_COUNT'] || '8'}"
flush_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_INTERVAL'] || '5s'}"
chunk_limit_size "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_CHUNK_LIMIT_SIZE'] || '2M'}"
queue_limit_length "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_QUEUE_LIMIT_LENGTH'] || '32'}"
retry_max_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_RETRY_MAX_INTERVAL'] || '30'}"
retry_forever true
3.之后docker化 并以DaemonSet的形式部署到kubernetes集群中
在git地址:https://github.com/trinity-project/fluentd-kubernetes-daemonset.git
cd /tmp && git clone https://github.com/trinity-project/fluentd-kubernetes-daemonset.git
cd /tmp/fluentd-kubernetes-daemonset/docker-image/v1.3/debian-elasticsearch
需要增加几个插件fluent-plugin-grepcounter fluent-plugin-mail(mail插件主要用来做报警用的 这个后续更新) fluent-plugin-concat
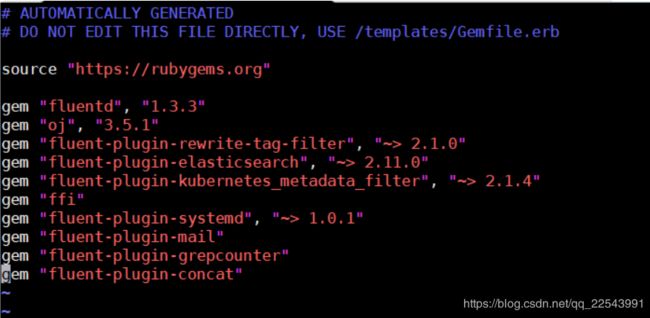
配置文件可以在编译之前就修改配置 也可以在kubernetes中以映射的形式更改配置文件 我这里直接更改
cd /tmp/fluentd-kubernetes-daemonset/docker-image/v1.3/debian-elasticsearch/conf
将上面我的配置放到里面就可以了
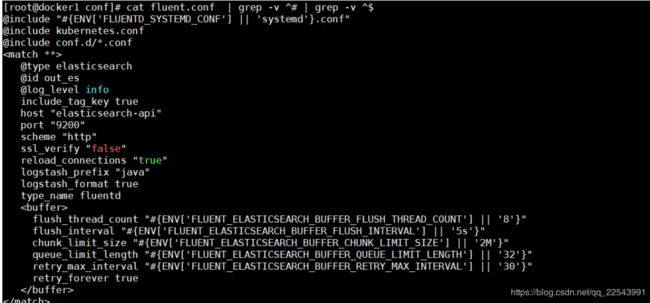
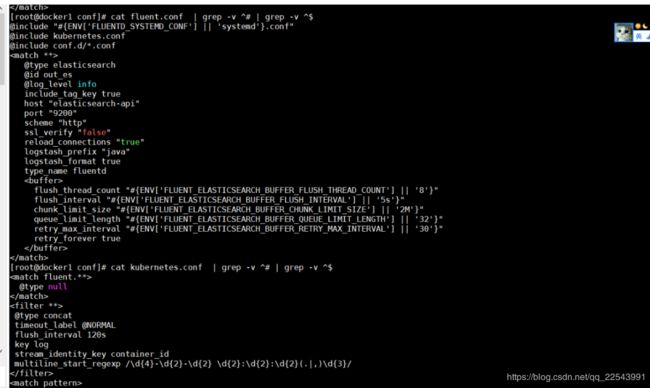
之后进行编译docker build -t fluentd:v1 .
编译好之后
修改/tmp/fluentd-kubernetes-daemonset/fluentd-daemonset-elasticsearch.yaml
更改images就好,其他的env参数如果你的fluentd是以变量的形式传递的话需要在这里改如果不是直接在fluentd直接常量的形式就可以直接删除掉配置
这里要注意的是我们日志定位的文件是存放在/var/log里的所以我要将该文件映射出来做持久化,不然删除容器定位的位置就不存在了
最后kibana里显示的样子应该是:
