【若泽大数据实战第十九天】Hive 函数UDF开发以及永久注册udf函数
前言:
回顾上期课程,上次课我们讲了聚合函数,多进一出,
分组函数 group by,出现在select里面的字段除了分组函数之外,其他都要出现在group by里面,分组函数的过滤必须使用hiving,hiving是对分组以后的结果做过滤的,where是对进来的数据一条条做过滤,
case when then 报表里面经常实现,给你一个条件让你显示字段,
分区表:为了提高查询的性能,降低IO,分区表分为,静态分区表,动态分区表,单级分区,一个目录,多级分区,是有多个分区,分区表就理解为一个大表拆分成很多小表,一个目录拆分成多个目录,静态分区表单级和多级使用起来是一样的,
partitioined by,语法没有区别,有区别的是,静态分区表你要给它分区值指定好,动态分区动只要写在select之后,就可以了它会自动的进行操作,动态分区表在工作中使用的非常的多,不需要指定很多条件,
函数:function,可以通过show functions,具体的 desc xxx xxx
本期课程如下:
explode:
把数组转成多行的数据
-- 创建一个文本:
[hadoop@hadoop000 data]$ vi hive-wc.txt
hello,world,welcome
hello,welcome-- 创建表hive_wc,并且把数据上传到hdfs上,查看数据是否上传成功。
hive> create table hive_wc(sentence string);
OK
Time taken: 1.083 seconds
hive> load data local inpath '/home/hadoop/data/hive-wc.txt' into table hive_wc;
Loading data to table default.hive_wc
Table default.hive_wc stats: [numFiles=1, totalSize=35]
OK
Time taken: 1.539 seconds
hive> select * from hive_wc;
OK
hello,world,welcome
hello,welcome
Time taken: 0.536 seconds, Fetched: 3 row(s)求每个单词出现的个数:
1.获取每个单词
select split(sentence,",") from hive_wc;
实验发现可以获取每个单词
hive> select split(sentence,",") from hive_wc;
OK
["hello","world","welcome"]
["hello","welcome"]
[""]
Time taken: 0.161 seconds, Fetched: 3 row(s)我们的需求是变成,以下的格式,这样我们就可以做group by了
"hello"
"world"
"welcome"
"hello"
"welcome"
explode把数组转成多行的数据修改后的sql语句:
hive> select explode(split(sentence,",")) from hive_wc;
OK
hello
world
welcome
hello
welcome用一个SQL完成wordcount统计:
hive> select word, count(1) as c
> from (select explode(split(sentence,",")) as word from hive_wc) t
> group by word ;
Query ID = hadoop_20180613094545_920c2e72-5982-47eb-9a9c-5e5a30ebb1ae
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1528851144815_0001, Tracking URL = http://hadoop000:8088/proxy/application_1528851144815_0001/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin/hadoop job -kill job_1528851144815_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-06-13 10:18:53,155 Stage-1 map = 0%, reduce = 0%
2018-06-13 10:18:59,605 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.42 sec
2018-06-13 10:19:07,113 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.31 sec
MapReduce Total cumulative CPU time: 4 seconds 310 msec
Ended Job = job_1528851144815_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.31 sec HDFS Read: 7333 HDFS Write: 29 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 310 msec
OK
1
hello 2
welcome 2
world 1
Time taken: 26.859 seconds, Fetched: 4 row(s) json : 工作中经常要接触到的
使用到的文件: [hadoop@hadoop000 data]$ rating.json
创建一张表 rating_json,上传数据,并查看前十行数据信息
hive> create table rating_json(json string);
OK
hive> load data local inpath '/home/hadoop/data/rating.json' into table rating_json;
Loading data to table default.rating_json
Table default.rating_json stats: [numFiles=1, totalSize=34967552]
OK
hive> select * from rating_json limit 10;
OK
{"movie":"1193","rate":"5","time":"978300760","userid":"1"}
{"movie":"661","rate":"3","time":"978302109","userid":"1"}
{"movie":"914","rate":"3","time":"978301968","userid":"1"}
{"movie":"3408","rate":"4","time":"978300275","userid":"1"}
{"movie":"2355","rate":"5","time":"978824291","userid":"1"}
{"movie":"1197","rate":"3","time":"978302268","userid":"1"}
{"movie":"1287","rate":"5","time":"978302039","userid":"1"}
{"movie":"2804","rate":"5","time":"978300719","userid":"1"}
{"movie":"594","rate":"4","time":"978302268","userid":"1"}
{"movie":"919","rate":"4","time":"978301368","userid":"1"}
Time taken: 0.195 seconds, Fetched: 10 row(s)jason_tuple 是一个UDTF是 Hive0.7版本引进的
hive> select
> json_tuple(json,"movie","rate","time","userid") as (movie,rate,time,userid)
> from rating_json limit 10;
OK
1193 5 978300760 1
661 3 978302109 1
914 3 978301968 1
3408 4 978300275 1
2355 5 978824291 1
1197 3 978302268 1
1287 5 978302039 1
2804 5 978300719 1
594 4 978302268 1
919 4 978301368 1
Time taken: 0.189 seconds, Fetched: 10 row(s)-- 时间类型的转换

output(作业)
userid,movie,rate,time, year,month,day,hour,minute,ts
1 1193 5 2001 1 1 6 12 2001-01-01 06:12:40
-- 准备一份数据
[hadoop@hadoop000 data]$ more hive_row_number.txt
1,18,ruoze,M
2,19,jepson,M
3,22,wangwu,F
4,16,zhaoliu,F
5,30,tianqi,M
6,26,wangba,F
[hadoop@hadoop000 data]$ -- 创建一个表测试rownumber,插入数据,查看是否有数据
hive> create table hive_rownumber(id int,age int, name string, sex string)
> row format delimited fields terminated by ',';
OK
Time taken: 0.451 seconds
hive> load data local inpath '/home/hadoop/data/hive_row_number.txt' into table hive_rownumber;
Loading data to table hive3.hive_rownumber
Table hive3.hive_rownumber stats: [numFiles=1, totalSize=84]
OK
Time taken: 1.381 seconds
hive> select * from hive_rownumber ;
OK
1 18 ruoze M
2 19 jepson M
3 22 wangwu F
4 16 zhaoliu F
5 30 tianqi M
6 26 wangba F
Time taken: 0.455 seconds, Fetched: 6 row(s)-- 查询出每种性别中年龄最大的两条数据 -- > topn
order by 是全局的排序,是做不到分组内的排序的
组内进行排序,就要用到窗口函数or分析函数
分析函数:
select id,age,name.sex
from
(select id,age,name,sex, -- 按照性别进行分组,分组以后再性别里面按照年龄的降序排列
ruo_number()over(partition by sex order by age desc)
from hive_rownumber) t
where rank<=2;
hive> select id,age,name,sex
> from
> (select id,age,name,sex,
> row_number() over(partition by sex order by age desc) as rank
> from hive_rownumber) t
> where rank<=2;
Query ID = hadoop_20180614202525_9829dc42-3c37-4755-8b12-89c416589ebc
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=
In order to set a constant number of reducers:
set mapreduce.job.reduces=
Starting Job = job_1528975858636_0001, Tracking URL = http://hadoop000:8088/proxy/application_1528975858636_0001/
Kill Command = /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin/hadoop job -kill job_1528975858636_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-06-14 20:26:18,582 Stage-1 map = 0%, reduce = 0%
2018-06-14 20:26:24,010 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.48 sec
2018-06-14 20:26:31,370 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.86 sec
MapReduce Total cumulative CPU time: 3 seconds 860 msec
Ended Job = job_1528975858636_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.86 sec HDFS Read: 8586 HDFS Write: 56 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 860 msec
OK
6 26 wangba F
3 22 wangwu F
5 30 tianqi M
2 19 jepson M
Time taken: 29.262 seconds, Fetched: 4 row(s) UDF: 一进一出 upper lower substring(进来一条记录,出去还是一条记录)
UDAF:Aggregation(用户自定的聚合函数) 多进一出 count max min sum ...
UDTF: Table-Generation 一进多出
【若泽大数据项目】
IDEA+Maven
创建一个新的项目
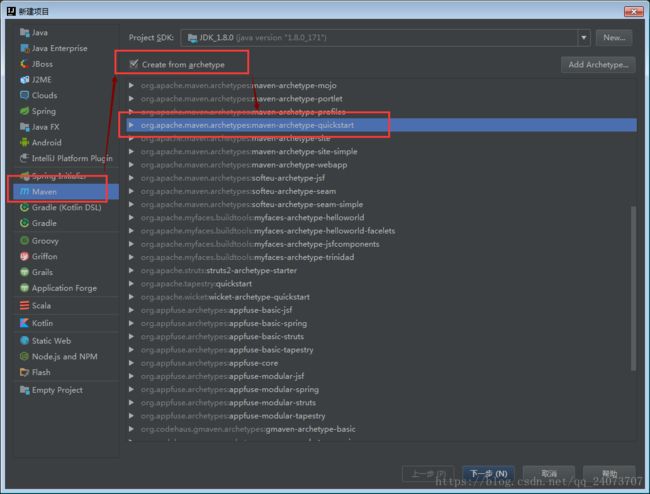
填写相关信息:
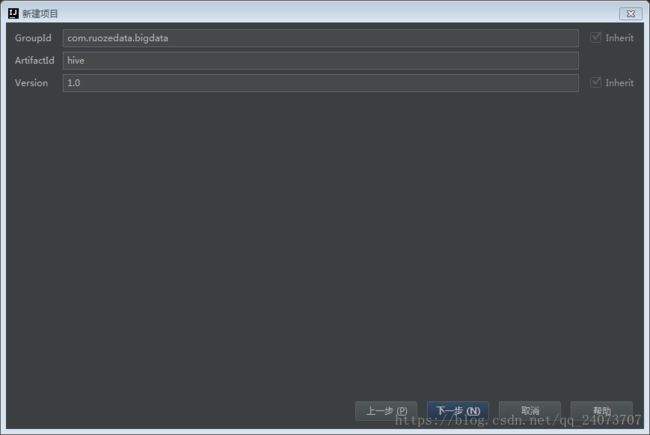
修改参数路径:
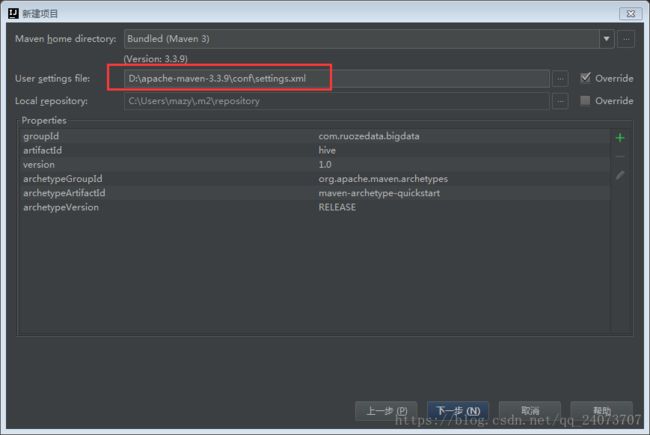
填写项目名称和保存路径:

更新完后删除:

修改:
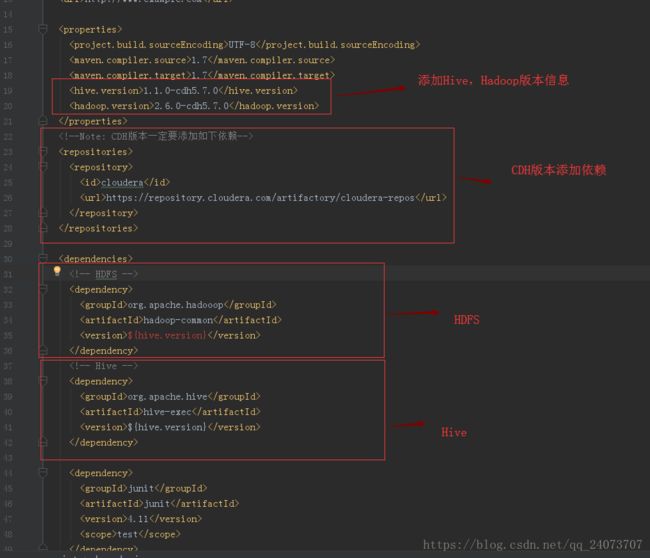
页面可以打开就行:
https://repository.cloudera.com/artifactory/cloudera-repos/

本次环境需要下载:
Index of cloudera-repos/org/apache/hadoop/hadoop-common
新建一个类:

功能:输入XXX,输出Hello xxx -> 输入一个东西,输出的时候前面带Hello
自定义UDF函数的步骤:
1)定义一个类 extends UDF (继承UDF)
导入继承UDF
-- 现在我们输出一个,Hello:若泽:Jepson
package com.RUOZEdata.bigdata;
import org.apache.hadoop.hive.ql.exec.UDF;
public class HelloUDF extends UDF {
public String evaluate(String input){
return "Hello:" + input;
}
public String evaluate(String input, String input2) {
return "Hello:" + input + ":" + input2;
}
public static void main(String[] args) {
HelloUDF udf = new HelloUDF();
System.out.println(udf.evaluate("若泽", "Jepson"));
}
}
打包:
打包成功:

上传jar包到 /home/hadoop/lib目录下:

第一种:创建临时函数。如在hive CLI执行下面命令:
-- 以下命令Hive执行,创建 sayHello
add jar /home/hadoop/lib/hive-1.0.jar;
CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
这里的红色字体是从UDF这里 复制 reference,注意红色字体旁边需要有引号

-- 执行语句
[hadoop@hadoop000 ~]$ hive
which: no hbase in (/home/hadoop/app/hive-1.1.0-cdh5.7.0/bin:/home/hadoop/app/apache-maven-3.3.9/bin:/usr/java/jdk1.8.0_45/bin:/home/hadoop/app/findbugs-1.3.9/bin:/home/hadoop/app/apache-maven-3.3.9/bin:/home/hadoop/bin:/usr/java/jdk1.8.0_45/bin:/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/hadoop/bin:/home/hadoop/bin:/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/bin)
Logging initialized using configuration in file:/home/hadoop/app/hive-1.1.0-cdh5.7.0/conf/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> use hive3;
OK
Time taken: 0.542 seconds
hive> add jar /home/hadoop/lib/hive-1.0.jar;
Added [/home/hadoop/lib/hive-1.0.jar] to class path
Added resources: [/home/hadoop/lib/hive-1.0.jar]
hive>
> CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
OK
Time taken: 0.014 seconds-- show functions 查找是否存在:
转成了小写
hive> show functions
> ;
OK
!
!=
%
&
*
+
-
/
<
<=
<=>
<>
=
==
>
>=
^
sort_array
soundex
space
sayhello
sqrt
stack
std
stddev-- 查看是否语句存到Hive里面了,用上次的dual表测试
hive> select sayhello("ruoze") from dual;
OK
Hello:ruoze
Time taken: 0.917 seconds, Fetched: 1 row(s)
hive> select sayhello("ruoze","jepson") from dual;
OK
Hello:ruoze : jepson
Time taken: 0.08 seconds, Fetched: 1 row(s)
-- 从新开一个窗口启动 Hive -- > show functions -->发现没有sayhello
我们使用的是TEMPORARY:仅对当前session(黑窗口)有效,所以在其他窗口打开是没用的
CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
-- 在第一个窗口使用 list jars可以查看到刚刚添加的jar包
hive> list jars;
/home/hadoop/lib/hive-1.0.jar
hive>-- Drop 刚刚创建的临时的function
删除后发现找不到相关的 function
hive> DROP TEMPORARY FUNCTION sayhello;
OK
Time taken: 0.005 seconds
hive> select sayhello("ruoze","jepson") from dual;
FAILED: SemanticException [Error 10011]: Line 1:7 Invalid function 'sayhello'
hive> -- 如果从新开一个窗口,会有要去add jar比较麻烦,我们需要在Hive的目录底下创建一个文件,把jar包拷贝过去
然后再创建新的表测试,是否正确,临时的创建,从启后都会失效。
-- 拷贝
[hadoop@hadoop000 hive-1.1.0-cdh5.7.0]$ mkdir auxlib
[hadoop@hadoop000 hive-1.1.0-cdh5.7.0]$ cd auxlib/
[hadoop@hadoop000 auxlib]$ cp ~/lib/hive-1.0.jar .
[hadoop@hadoop000 auxlib]$ ll
total 4
-rw-r--r--. 1 hadoop hadoop 3214 Jun 16 23:45 hive-1.0.jar
-- 创建新的临时表,不需要 add jar
hive> CREATE TEMPORARY FUNCTION sayHello AS 'com.ruozedata.bigdata.HelloUDF';
OK
Time taken: 0.013 seconds
hive> select sayhello("ruozedata") from dual;
OK
Hello:ruozedata
Time taken: 0.651 seconds, Fetched: 1 row(s)第二种:修改源代码,重编译,注册函数。这种方法可以永久性的保存udf函数,但是风险很大
-- 首先需要把本地文件hive-1.0.jar放到HDFS上,然后在创建永久的函数的时候需要指定HDFS目录
-- 文件上传
[hadoop@hadoop000 auxlib]$ hadoop fs -ls /
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2018-06-05 23:38 /ruozedata
drwx-wx-wx - hadoop supergroup 0 2018-06-05 22:36 /tmp
drwxr-xr-x - hadoop supergroup 0 2018-06-05 09:55 /user
[hadoop@hadoop000 auxlib]$ hadoop fs -mkdir /lib
[hadoop@hadoop000 auxlib]$ hadoop fs -put /home/hadoop/lib/hive-1.0.jar /lib/
[hadoop@hadoop000 auxlib]$ hadoop fs -ls /lib
Found 1 items
-rw-r--r-- 1 hadoop supergroup 3214 2018-06-16 23:52 /lib/hive-1.0.jar-- 创建函数,我这里和若泽的端口号可能不同我这里是9000,他这里是8020
hive> CREATE FUNCTION sayRuozeHello AS 'com.ruozedata.bigdata.HelloUDF'
> USING JAR 'hdfs://hadoop000:9000/lib/hive-1.0.jar';
converting to local hdfs://hadoop000:9000/lib/hive-1.0.jar
Added [/tmp/511023ea-b9d8-46d3-aff8-c1e3613f61c9_resources/hive-1.0.jar] to class path
Added resources: [hdfs://hadoop000:9000/lib/hive-1.0.jar]
OK
Time taken: 0.192 seconds不确定端口号的 hive > desc formatted 一张表,

-- 如果看到这一串不认识的东西 511023ea-b9d8-46d3-aff8-c1e3613f61c9 就是HDFS上的
hive> list jars;
/tmp/511023ea-b9d8-46d3-aff8-c1e3613f61c9_resources/hive-1.0.jar-- show functions 查看是否有sayruozehello,我这里使用的hive3数据库,所以开头是hive3
hive> use hive3;
OK
Time taken: 0.019 seconds
hive> show functions;
OK
!
!=
%
&
*
+
-
/
<
<=
<=>
<>
=
==
>
>=
^
abs
acos
add_months
and
array
array_contains
ascii
asin
assert_true
atan
avg
base64
between
bin
case
cbrt
ceil
ceiling
coalesce
collect_list
collect_set
compute_stats
concat
concat_ws
context_ngrams
conv
corr
cos
count
covar_pop
covar_samp
create_union
cume_dist
current_database
current_date
current_timestamp
current_user
date_add
date_sub
datediff
day
dayofmonth
decode
degrees
dense_rank
div
e
elt
encode
ewah_bitmap
ewah_bitmap_and
ewah_bitmap_empty
ewah_bitmap_or
exp
explode
field
find_in_set
first_value
floor
format_number
from_unixtime
from_utc_timestamp
get_json_object
greatest
hash
hex
histogram_numeric
hive3.sayruozehello-- 查询是否存在:
hive> select sayruozehello("ruoze") from dual;
OK
Hello:ruoze
Time taken: 0.395 seconds, Fetched: 1 row(s)-- 再打开一个窗口,查看是否能查询的到 show functions

-- 再查询,这次查询不连接hive3库,直接查询,查询的时候要在信息前面加hive3的库名,第一次会转换,从HDFS上加载进来
hive> select hive3.sayruozehello("ruoze") from hive3.dual;
converting to local hdfs://hadoop000:9000/lib/hive-1.0.jar
Added [/tmp/1b591e5e-879b-4539-ab9b-634a125042c1_resources/hive-1.0.jar] to class path
Added resources: [hdfs://hadoop000:9000/lib/hive-1.0.jar]
OK
Hello:ruoze
Time taken: 0.831 seconds, Fetched: 1 row(s)-- 永久注册,会注册到元数据内,我们进行元数据查询。
[root@hadoop000 ~]# su - mysqladmin
[mysqladmin@hadoop000 ~]$ mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 33
Server version: 5.6.23-log MySQL Community Server (GPL)
Copyright (c) 2000, 2015, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| ruozedata_basic03 |
| test |
+--------------------+
5 rows in set (0.05 sec)
mysql> use ruozedata_basic03;
Database changedmysql> select * from FUNCS\G;
*************************** 1. row ***************************
FUNC_ID: 6
CLASS_NAME: com.ruozedata.bigdata.HelloUDF
CREATE_TIME: 1529165077 (创建的时间)
DB_ID: 11
FUNC_NAME: sayruozehello (函数名)
FUNC_TYPE: 1
OWNER_NAME: NULL
OWNER_TYPE: USER
1 row in set (0.01 sec)-- 查看时间戳,这个时间是刚刚创建的时间

-- 我们启动Hive会有很多函数,都是怎么来的呢

-- 点击UDF,了解底层的机制

-- 如果你要创建一个UDF,必须要继承UDF,然后去从写里面的方法,就完成了UDF的功能了。
源码面前,了无秘密

总结:
对比分析上面两种方法,你会发现,第一种方法无法满足现实开发需要,因为实际业务中需要一些稳定的公共udf函数;第二种方法虽然满足了第一种的需求,但是风险太大,容易造成hive异常。
大数据课课程推荐:
