忘记时间戳的存在——Yii2超实用的自动更新时间戳的Behavior(改进版)
本文改进了Yii2中内置行为类
TimestampBehavior,使得时间戳字段(如created_at,updated_at)完全自己更新,方便得让你忘记它们的存在。
Yii2的内置行为类TimestampBehavior几乎成了各种介绍Yii2行为的常客。各种讲解行为的文章中都少不了它的身影,它甚至登堂入室,被Yii2官方文档采用了。它的标准用法——虽然大家都知道——但我也贴出来:
class User extends ActiveRecord
{
// ...
public function behaviors()
{
return [
[
'class' => TimestampBehavior::className(),
'attributes' => [
ActiveRecord::EVENT_BEFORE_INSERT => ['created_at', 'updated_at'],
ActiveRecord::EVENT_BEFORE_UPDATE => ['updated_at'],
],
// if you're using datetime instead of UNIX timestamp:
// 'value' => new Expression('NOW()'),
],
];
}
}
但是这样做,有两个问题
- 如果你放上不存在的字段(比如将
created_at拼写成create_at,或者多写了个字段logined_at),立即会报错,不信邪的可以试试 - 因为上一个原因的存在,你必须谨慎填写两个字段列表,不能多也不能错;而且不能放到公共的Model里面,因为可能User有
updated_at而Comment里面就没有,那么岂不是每个Model都要去重载一遍behaviors()咯?
分析TimestampBehavior的源码确实可以印证我们说的两个问题,那么有解决办法吗?如何让时间戳字段智能起来,完全自动更新不用我们管?办法有的!请看下面,直接上改进后的源码:
/**
* 改进后的时间戳行为类
*
* 可以放到比如说common/behaviors/下面
*/
class TimestampBehavior extends AttributeBehavior
{
//创建时要更新的字段(填写不存在的字段也无碍)
public $onCreate = [];
//更新时需要更新的字段
public $onUpdate = [];
public $value;
/**
* @inheritdoc
*/
public function init()
{
parent::init();
$this->onCreate = (array) $this->onCreate;
$this->onUpdate = (array) $this->onUpdate;
if (empty($this->attributes)) {
//合并,去重复
$this->attributes = [
//创建时要更新的字段,需要去重复
BaseActiveRecord::EVENT_BEFORE_INSERT => array_unique(array_merge($this->onCreate, $this->onUpdate)),
//更新时要更新的字段
BaseActiveRecord::EVENT_BEFORE_UPDATE => $this->onUpdate,
];
}
}
// 关键就在这里——剔除不存在的字段
public function evaluateAttributes($event)
{
if (!empty($this->attributes[$event->name])) {
//删掉不存在的字段
$this->attributes[$event->name] = array_intersect($this->owner->attributes(), $this->attributes[$event->name]);
}
parent::evaluateAttributes($event);
}
// 这里没做改变
protected function getValue($event)
{
if ($this->value === null) {
return time();
}
return parent::getValue($event);
}
// 这里也没做改变
public function touch($attribute)
{
$this->owner->updateAttributes(array_fill_keys((array) $attribute, $this->getValue(null)));
}
}
那么在使用的时候,便可以这样来用:
public function behaviors()
{
return [
'timeStamp' => [
'class' => TimestampBehavior::class,
'onCreate' => 'create_at',//写成['create_at']也可以的
'onUpdate' => ['update_at', 'login_at'],
]
];
}
看起来好像简洁了很多,然而这不是最大优点,更精彩的在后面。
假如我们有张评论表comments,只有五个字段(id,content,status,create_at,update_at)一看就懂的,无需解释。现在创建一个新记录:
$comment = new Comment();
$comment->content = 'xiaomili';
$comment->save();
//打印结果
VarDumper::dump(comment, 10, true);
可以看到:
[
'id' => 129
'content' => 'xiaomili'
'status' => 1
'create_at' => 1520436115
'update_at' => 1520436115
]
再看更新
$comment = Comment::findOne(129);
$comment->content = 'this comment is updated';
$comment->status = 2;
$comment->save();
//打印结果
VarDumper::dump(comment, 10, true);
可以看到:
[
'id' => 129
'content' => 'this comment is updated'
'status' => 2
'create_at' => 1520436115
'update_at' => 1520436209
]
我们注意到behaviors()中onUpdate指定的的login_at是不存在的,然而并没有错误被抛出,两个字段create_at和update_at无论在创建还是在修改中都正常更新为最新时间戳。而如果comments表有login_at字段,它将会随着update_at一同被更新。
再看一种情况,我们拼写错误,在behaviors()中指定了一个不存在的时间戳字段:
public function behaviors()
{
return [
'timeStamp' => [
'class' => TimestampBehavior::class,
'onCreate' => 'craeted_at',//注意这里拼写错误
'onUpdate' => ['update_at', 'login_at'],
]
];
}
再创建一条新纪录看看:
[
'id' => 130
'content' => 'xiaomili'
'status' => 1
'create_at' => 0
'update_at' => 1520436603
]
仍然可以成功创建,然而正确的字段create_at却没有被更新,顶多取个默认值而已。
上面几个例子说明我们改进的TimestampBehavior行为是有益无害的。因为它的人畜无害,好了,现在我们可以放到BaseModel里面供所有Model膜拜了:
class BaseModel extends ActiveRecord
{
public function behaviors()
{
return [
'timeStamp' => [
'class' => TimestampBehavior::class,
'onCreate' => 'create_at'
'onUpdate' => ['update_at', 'login_at'],
]
];
}
}
原谅我更喜欢命名行为,因为容易解绑。
从此,你解放了大脑,不用再考虑每个表字段的不同而差异化的去设置onCreate和onUpdate的不同字段了:comments表有create_at
和update_at,而users表还有个login_at字段,但是category什么xxx_at字段也没有。它们的Model在创建/修改时也不会出半点幺蛾子。
当然,官方TimestampBehavior的touch()方法还是保留的,因为确实很方便:
$user->touch('login_at');
有了这个改进的行为类,我们在开发时基本就不用去关心这些时间戳字段,只需要在用的时候拿来用就行。
笔者在开发的时候已经在多个项目中使用我们这个改进版的TimestampBehavior了,被证明是高效的,大家可以放心无虞的使用。
使用TimestampBehavior有多方便,我们来算一笔账:假如有一张非常普通的report表
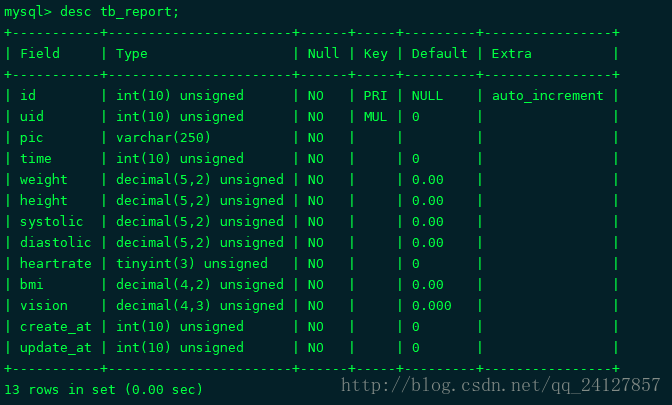
13个字段——算中等水平。我们来分析下这些字段相对“关注程度”
- 几乎不用关注的字段
id,create_at,update_at,它们自己创建自动更新,一共3个,占23% - 需要一般关注的字段
time,weight,height,systolic,diastolic,heartrate,bmi,vision,一般是和这个表内容字段,需要注意校验,一共8个,占62% - 需要重点关注的字段
uid,pid因为它们是逻辑外键,是关联表的连接字段,在获取关联模型时是尤其要注意的,一共2个,占15%
这样,13个字段中,有3个字段你不用去考虑它们的赋值、校验;而weight,height等字段一般只会出现在自己的Model中,只需要在校验时注意下范围、大小、唯一性等特性,插入和修改关心下,查询时无需关心;而唯独uid,pid这个两个关联字段就比较麻烦,会出现在增删改以及关联查询中,想保持数据一致性就得特别小心。
先做这样的分析,然后就有的放矢。你的主要精力就放在那第二类和第三类上,并由其注意第三类。如果不是我们的TimestampBehavior,我们还得在第二类上再加上两个字段一共10个,要分析的字段从10个变成12个,多了20%。如果数据表的字段少这更加明显。鉴于几乎每张表都会有create_at,update_at这两个字段,假设我们有10张表,那我们就可以少分析20个字段,少花20份精力。减少重复工作才是高效之道啊!