Dropout:A Simple Way to Prevent Neural Networks from Overfitting
原文:Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. Journal of Machine Learning Research, 2014, 15(1):1929-1958.
这是一篇深度学习领域引用量目前达到1779的文章,在学习深度学习必读文章之列,下面理解下作者们的主要思想
深度神经网络包含multiple非线性隐藏层,这使得深度神经网络是一个具有非常强的表达能力的模型,他们可以到学习网络输入到输出之间非常复杂的关系。但是由于有限的训练数据,这些复杂的关系中有有许多是受到采样噪声影响的结果,这部分关系只出现在训练集,但在实际的测试集中并不存在,即使训练集和测试集是从同一个分布产生。这会导致过拟合,许多方法被发展用于减少这种问题。这些方法包括如当网络在验证集的表现出现下降时终止训练,引入多种权值惩罚如L1和L2正则化,软权重共享。
有无限运算的前提下,调整一个固定大小模型的最好方法,是对所有可能的参数设置所得到的预测结果取加权平均,依据训练集的后验概率对各种参数设置给定权重。这对于简单或者小的模型有时候可以取得相当好的逼近效果,但是,我们想使用少量的计算得到贝叶斯黄金标准的模型表现。我们打算通过逼近一个同样的多个预测进行的加权几何平均,这些预测由指数数量的共享参数的学习模型所得到。
模型结合一般可以提升机器学习方法的表现。但是对于巨大的神经网络而言,对许多分离的训练好的网络的输出取平均的想法是过分的昂贵。当单个模型之间各不相同时,结合几个模型是几乎有效的方法,这些模型的不同体现在不同的结构或者使用不同的训练样本进行训练。训练许多不同结构的模型是非常困难的,因为要找到每个结构所对应的超参数是一个令人沮丧的任务,而且训练不同结构的模型需要许多的运算资源。再且,巨大的网络一般需要大量的训练数据,但实际可能没有足够的训练数据得到不同的子集用于训练不同的网络。即使可以训练到许多不同的大型网络,在快速响应是很重要的场景,实际应用测试时候同时使用全部大型网络是不实际的。
Dropout是一个解决这些问题的技术,它可以防止过拟合并且提供一种结合指数数量不同神经网络结构的近似的方法。Dropout指在神经网络当中丢弃一些单元。丢弃一个单元指暂时地把该单元从网络中移除,连带它全部的输入输出连接,如下图所示。对于哪个单元该被丢弃,选择是随机的。在最简单的情况里每个单元都有一个固定的相互独立的概率p。p可以通过验证集得到或者简单得设置为0.5。
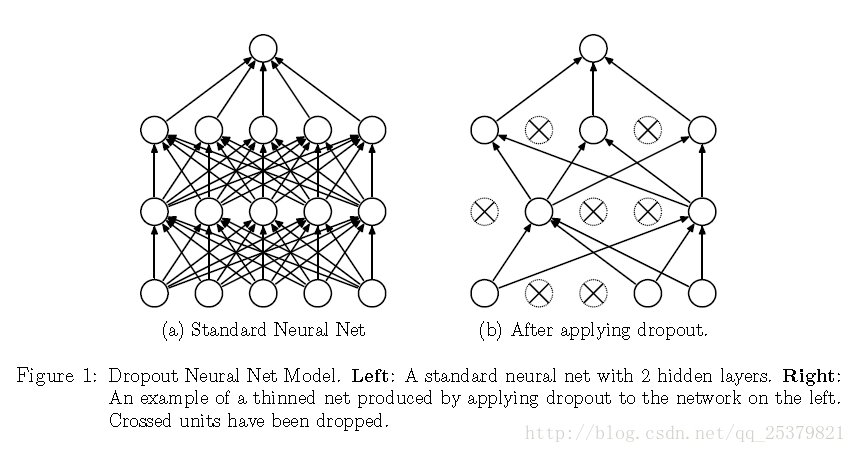
对神经网络使用Dropout相当于获得该网络的一个简化版本。简化网络由没有被丢弃的单元所组成。一个有n个单元的神经网络有 2n 个简化版本网络。这些简化版的网络共享权值使得权值参数总数依然是 O(n2) 或者更少。
在测试时,对由指数级别数量简约模型所得到的预测进行平均是不可行的。但是一个非常简单的近似平均方法在实际应用中有很好的效果。想法是在测试时使用一个单一的没有经过Dropout的网络。该网络单元的输出权重等于该单元在训练时没有被Dropout的概率。这样使得指数级别数量的简化网络在测试时得到结合,实验证明这样可以有效的降低泛化误差。
Dropout的概念不仅仅局限于神经网络,在玻尔兹曼机等图形模型也可以被广泛应用。