在Linux集群下的单节点下安装hadoop伪分布式集群
参考文章:http://www.powerxing.com/install-hadoop-in-centos/
1.安装环境介绍:
本次安装是在集群中的某个单节点下安装的,我负责的实验室集群有83个节点,主节点为node100,负责管理其余的node1—node82节点,集群中只有node100可以联网,因为后面的5个节点长时间没有人使用,所有拿来自己学习下,安装的目录也与所有节点的公共存储文件分开,在对应节点的/下面操做,所以丝毫不会对集群造成影响
Centos6.5+Hadoop2.8.2+Jdk1.8 在节点node82上安装
2.首先运行 java –version 看Java是否安装成功,安装方式见另一篇博客点击打开链接。

3.以上jdk安装目录是
4.下载hadoop(因为主节点node100可以联网,所以通过主节点下载)
wget http://ftp.twaren.net/Unix/Web/apache/hadoop/common/hadoop-2.8.2/hadoop-2.8.2.tar.gz
可能由于版本更新无法下载,可以取官网下载:http://ftp.twaren.net/Unix/Web/apache/hadoop/common/ 选择合适的版本手动下载
5.将下载好的hadoop-2.8.3.tar.gz 通过scp hadoop-2.8.3.tar.gz [email protected]:/home/username/
将当前目录下的 hadoop-2.8.3.tar.gz拷贝到节点node82下的/home/username目录下,注意10.10.10.82是集群内网IP。
![]()
6.切换到node82 进入/home/username
ssh node82 (这里之所以可以ssh node82,是因为集群已经安装了免密钥登陆,具体技术和原理以及实现方式今后再出)
7.解压 tar –zxvf hadoop-2.8.3.tar.gz 得到hadoop-2.8.3文件
8.将hadoop-2.8.3移动到/usr/local/hadoop
mv hadoop-2.8.3 /usr/local/hadoop
改变文件所属者和所属组 sudo chown yexin:nimrod -R hadoop (这里改成自己的用户名和组)
9.进入到用户目录修改 .bashrc
cd ~(波浪线)
sudo vim ~/.bashrc
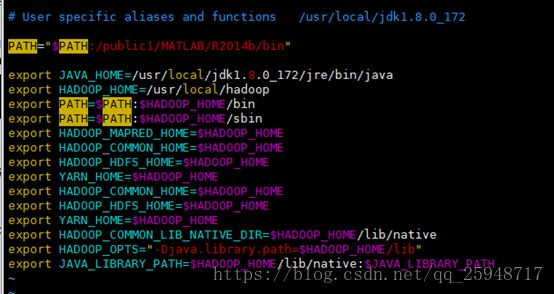
输入以下内容:
exportJAVA_HOME=/usr/local/jdk1.8.0_172/jre/bin/java ---设置JDK安装路径
exportHADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
exportPATH=$PATH:$HADOOP_HOME/sbin
exportHADOOP_MAPRED_HOME=$HADOOP_HOME
exportHADOOP_COMMON_HOME=$HADOOP_HOME
exportHADOOP_HDFS_HOME=$HADOOP_HOME
exportYARN_HOME=$HADOOP_HOME
exportHADOOP_COMMON_HOME=$HADOOP_HOME
exportHADOOP_HDFS_HOME=$HADOOP_HOME
exportYARN_HOME=$HADOOP_HOME
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
exportHADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
exportJAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
截图如下:
10.使配置文件生效 source ~/.bashrc
11.修改Hadoop的配置文件
首先进入到 /usr/local/hadoop/etc/hadoop
(1) Step1 修改hadoop-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
修改 export JAVA_HOME=/usr/local/jdk1.8.0_172

按esc, 输入:wq 回车 保存退出
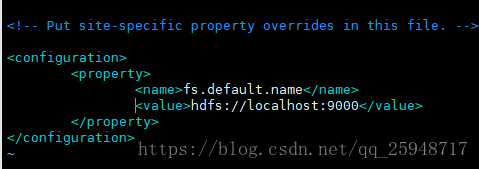
(2) Step2 修改core-site.xml,设置HDFS的默认名称
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
做如下修改
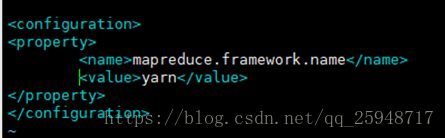
(3) Step3 修改yarn-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
做如下修改
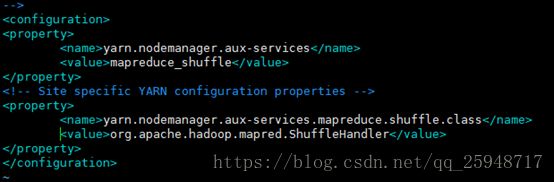
(4)Step4 修改mapred-site.xml,设置mapreduce的框架为yarn,该配置文件设置监控
Map和Reduce程序的JobTracker的任务分配情况和TaskTracker的任务运行情况。
sudocp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template
/usr/local/hadoop/etc/hadoop/mapred-site.xml
sudo vim/usr/local/hadoop/etc/hadoop/mapred-site.xml
做如下修改
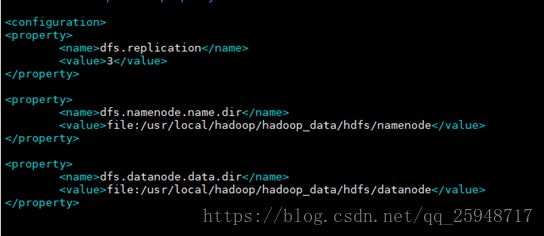
(5) Step5 修改hdfs-site.xml,设置namenode和datanode的存储目录,以及blocks副本
的备份数量
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
做如下修改
11.建立与格式化HDFS 目录
建立HDFS目录sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
sudo mkdir -p/usr/local/hadoop/hadoop_data/hdfs/datanode
修改所有者和所属组sudo chown yexin:nimrod -R /usr/local/hadoop
格式化HDFS 目录 hadoop namenode –format
12.启动Hadoop
启动start-dfs.sh,再启动 start-yarn.sh 在终端依次输入下面两条命令
start-dfs.sh
start-yarn.sh
或者
启动全部
start-all.sh
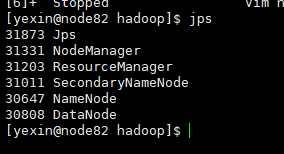
查看目前所执行的行程,输入以下命令
jps
看到以下表明成功(以上的执行文件都可以再hadoop/etc/sbin里面找到)
13.开启Hadoop ResourceManager Web接口
HadoopResourceManager Web接口网址
http://localhost:8088/
. NameNode HDFSWeb接口
开启HDFS Web UI网址
http://localhost:50070/
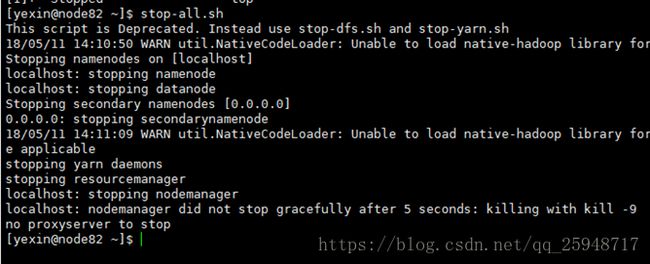
14.输入 stop-all.sh即可关闭服务