Hadoop的jobhistoryserver配置
简介
本文介绍hadoop的jobhistoryserver如何进行配置.在MRv2中我们要出查看job的log信息,需要启动jobhistory服务.
配置
jobhistory的配置信息在$HADOOP_HOME/etc/hadoop/mapred-site.xml中进行配置.
我们在该文件下加入如下信息:
<property>
<name>mapreduce.jobhistory.addressname>
<value>master:10020value>
<description>MapReduce
JobHistory Server IPC host:portdescription>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>master:19888value>
<description>MapReduce
JobHistory Server Web UI host:portdescription>
property>当我们启动jobhistoryserver服务之后,在我们的hdfs上的/tmp/hadoop-yarn/staging/history路径下会生成两个文件夹:done和done_intermediate,done文件夹下存放已经完成的job,done_intermediate文件夹下存放正在进行的job信息.
启动jobhistoryserver
启动jobhistoryserver需要在sbin目录下执行如下指令:
mr-jobhistory-daemon.sh
start historyserver然后我们执行jps,发现已经多出了JobHistoryServer这么一个进程.
同理,关闭jobhistoryserver指令如下:
mr-jobhistory-daemon.sh
start historyserver查看log
如上我们配置的jobhistoryserver的webUI的地址为19888,我们可以去web上查看我们的job执行情况以及log信息.
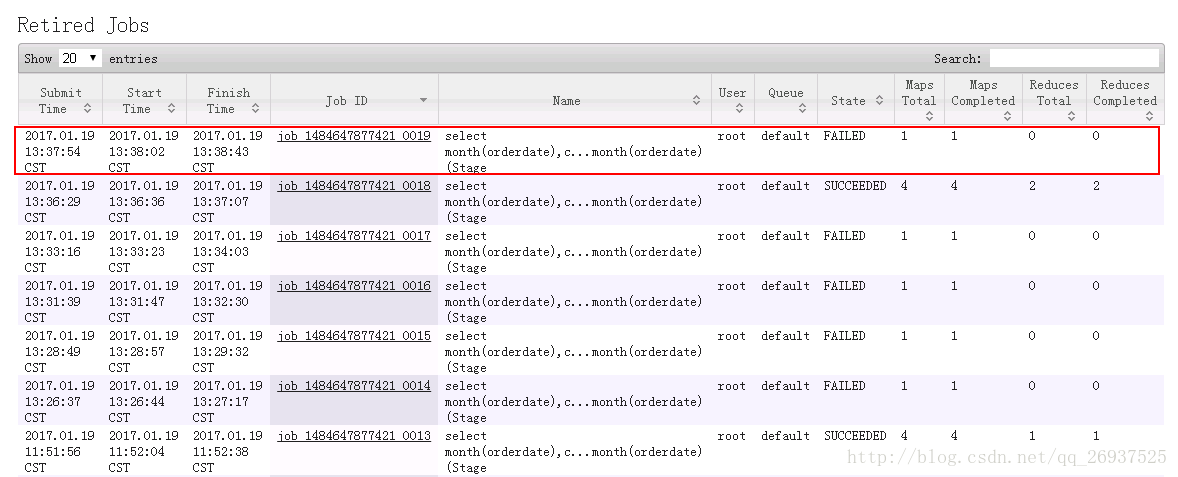
选择某个job之后可以去查看log信息
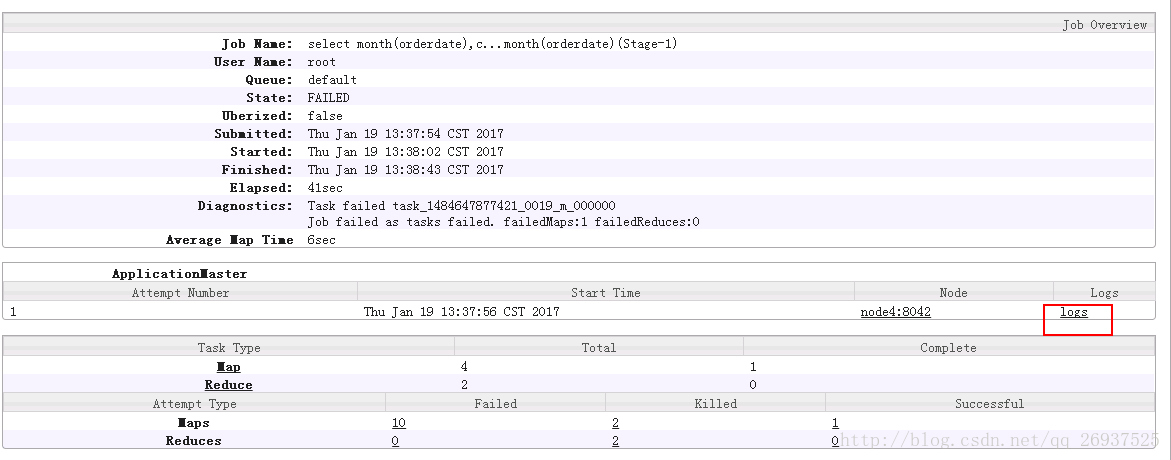 .想要实现这个功能,需要配置yarn的log aggregation功能.
.想要实现这个功能,需要配置yarn的log aggregation功能.
日志聚集
日志聚集是YARN提供的日志中央化管理功能,它能将运行完成的Container/任务日志上传到HDFS上,从而减轻NodeManager负载,且提供一个中央化存储和分析机制。默认情况下,Container/任务日志存在在各个NodeManager上,如果启用日志聚集功能需要额外的配置。
- yarn.log-aggregation-enable
参数解释:是否启用日志聚集功能。
默认值:false
- yarn.log-aggregation.retain-seconds
参数解释:在HDFS上聚集的日志最多保存多长时间。
默认值:-1
- yarn.log-aggregation.retain-check-interval-seconds
参数解释:多长时间检查一次日志,并将满足条件的删除,如果是0或者负数,则为上yarn.log-aggregation.retain-seconds值的1/10。
默认值:-1
- yarn.nodemanager.remote-app-log-dir
参数解释:当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效)
默认值:/tmp/logs
- yarn.nodemanager.remote-app-log-dir-suffix
参数解释:远程日志目录子目录名称(启用日志聚集功能时有效)。
默认值:日志将被转移到目录 yarn.nodemanager.remote−app−log−dir/ {user}/${thisParam}下
- yarn.nodemanager.log.retain-seconds
可如此设置<
name>yarn.log-aggregation.retain-seconds
<value>864000value>参数解释:log-aggregation为disabled时日志保存多长时间。
- yarn.nodemanager.log-dirs
可如此设置
<name>yarn.nodemanager.log-dirsname>
<value>/export/servers/hadoop2.6.0/yarn_logsvalue>参数解释:yarn node 运行时日志存放地址,记录container日志,并非nodemanager日志存放地址
注意默认的resourcemanager和nodemanager的log存在地址为:
- ResourceManager日志存放位置是Hadoop安装目录下的logs目录下的yarn--resourcemanager-.log
- NodeManager日志存放位置是各个NodeManager节点上hadoop安装目录下的logs目录下的yarn--nodemanager-.log