Traceroute是一个非常便利的网络诊断工具。它可以输出以下三个内容:
1 网络数据包的从源地址到目的地址的整个传输路径。
2 传输路径上的路由设备的信息(IP地址或者hostname)
3 网络数据包在路由设备间的延时(Latency)
从这些功能可以看出,traceroute通常可以用于判断网络故障,检测网络传输路径等场合。Traceroute现在基本随Linux系统发行,所以使用起来非常方便。在Windows系统下,对应的工具是TRACERT.
Traceroute的一个优点是,它不需要你发送实际的数据到目的地址,就能帮你输出整个网络路径(实际上还是要发送数据,只是发送的不是你的实际数据)。
在基于OpenFlow的SDN中,要实现traceroute功能,实际上就是要在SDN中实现traceroute所依赖的网络功能。那么接下来看看traceroute所依赖的网络功能有哪些?
TTL(hop limit)
在IP协议(Internet Protocol)中,TTL(Time To Live)是一个8bit的字段,IPv4协议中,协议头有20个8bit的字段,TTL占第9个8bit;IPv6协议中,协议头有40个8bit的字段,TTL占第8个8bit。因此,TTL在IP协议中,最大值是255,通常的默认值是64。下图是IPv4协议的字段。
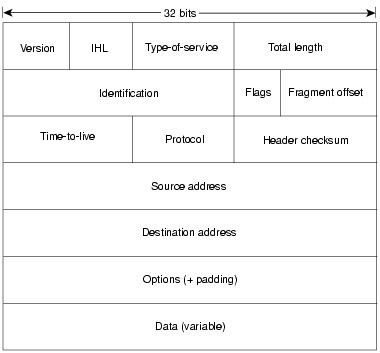
TTL存在的意义是什么?我们假设我们的网络系统中,每个路由设备都有默认路由,我们发出一个以不存在的地址作为目的地址的IP数据包,那么这个数据包将永远在我们的网络系统中转发。把网络系统看成Internet,那么随着时间推移,Internet必然会被大量这样的“永生”IP数据包淹没。正是为了避免这个问题,IP协议中提出了TTL,当TTL为0,IP数据包会被丢弃。
TTL被设计为IP数据包在Internet中最长的存活时间。但是实际上,每个转发了IP数据包的设备,都需要将TTL减1,也就是说TTL等于IP数据包能经历的最大跳(hop)数,而不是时间(秒数)。所以,为了避免误解,在IPv6中,将TTL改名为hop limit。为了省事,我们还是叫它TTL吧。
回过来看前面的描述,有两个问题:
什么是hop?
Hop是指IP数据包传输过程中的一段路径。当IP数据包从一个网络设备传输至另一个网络设备,这可以认为是一个hop(跳)。
IP数据包被谁丢弃了?
被路由设备丢弃了,根据RFC1812,路由设备在转发IP数据包的时候,会将TTL减1,如果减完之后的结果是0,那么IP数据包会被丢弃。所以说,在IP网络中,路由设备需要丢弃TTL为1的数据包。
路由设备在丢弃TTL为1的数据包之后,还会向数据包的源地址发送一个ICMP Time exceeded message(ICMP type 11),在这条信息中,路由设备会将自己的IP地址作为源地址。
总的来说traceroute就是基于TTL和路由设备的特性来实现的。
Traceroute原理
基本实现原理
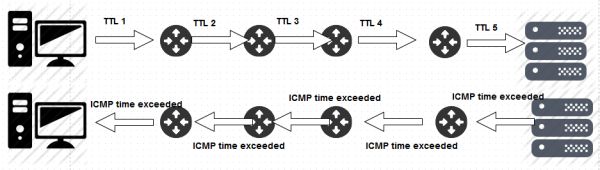
根据前面的描述,只要发送一个IP数据包,将TTL设为1,就能收到第一个路由设备返回的ICMP TTL exceeded message。将TTL设为2,就能收到第二个路由设备的。以此类推,当TTL大到一定数的时候……,IP数据包就被目的设备收到,并且目的设备会做出响应。所以traceroute的原理,简单来说,如下图所示:
探测包(UDP)
Traceroute会发送什么样的IP数据包?默认是UDP数据包。除了前面说过的TTL,这个UDP数据包会包含:
源地址
目的地址
一个UDP端口,端口号在33434和33534之间,这个区间的端口号对UDP来说是无效的端口号。因此目的地址收到了这个UDP数据包,会返回ICMP UDP Port Unreachable(ICMP type 3)的信息。这么一个别致的返回信息,traceroute在收到了它之后,就知道网络路径探测该结束了。
实际的数据流
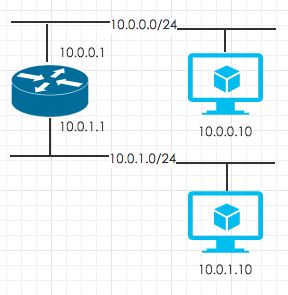
描述的差不多了,我们来看一个简单拓扑下traceroute背后的数据流吧。网络拓扑:
tcpdump抓包:
http://paste.ubuntu.com/23803412/
除了前面已经描述过的,有三点需要注意。
每个TTL都发了三个探测包出来,这是为了对同一个hop获得三次的延时数据,使得结果更加客观。
每次发出的探测包,UDP端口都不一样。这是为了将返回的信息跟发出的信息进行匹配。以计算IP数据包从发出到接收的延时(Latency)。在上面的示例中,这似乎没有必要,因为探测包都是一发一收,串行执行。那是因为我用的是简版的traceroute,在高版本的traceroute中,默认是并行发送16个探测包。来感受一下并行发送的凌乱感吧。
https://paste.ubuntu.com/23791252/
Traceroute收到了ICMP信息,都包含有内层信息,内层信息似乎有探测包的大部分信息。
探测包:IP (tos 0x0, ttl 1, id 2143, offset 0, flags [DF], proto UDP (17), length 46)10.0.0.10.33875 > 10.0.1.10.33435: UDP, length 18回复包:IP (tos 0xc0, ttl 64, id 15477, offset 0, flags [none], proto ICMP (1), length 74)10.0.0.1 > 10.0.0.10: ICMP time exceeded in-transit, length 54 IP (tos 0x0, ttl 1, id 2143, offset 0, flags [DF], proto UDP (17), length 46) 10.0.0.10.33875 > 10.0.1.10.33435: UDP, length 18
根据RFC777,ICMP协议要求将产生ICMP error的原数据包的至少前28字节拷贝至ICMP error message的payload,所以我们能看到探测包的内容。28个字节包括了20个字节的IP报头,和8个字节的UDP报头。
三种traceroute的实现方式
之前介绍的都是基于UDP协议的traceroute实现,而实际中traceroute还可以基于ICMP和TCP协议。首先要说的是,这三种方式的基本实现原理是一样的,都是基于TTL和路由设备返回的信息。区别是探测包不一样。为什么会有三种实现方式?因为你的防火墙可能阻止了UDP,为了让traceroute在这样的环境下也能工作,才有了别的实现。
ICMP traceroute
与UDP traceroute的区别就在于:
探测包就是ICMP echo request
目的设备返回的就是ICMP echo reply
linux下的traceroute可以通过指定参数来用ICMP做traceroute,而windows下的tracert默认就是用ICMP来做traceroute。
TCP traceroute
与UDP traceroute的区别在于:
探测方式是与tcp 80(默认)端口建立连接
目的设备的返回时连接成功,或者80端口关闭
即使目的设备返回连接成功,traceroute程序会立即断开连接,因为没有必要。
Traceroute with NAT
问题
这是个比较有意思的方向。前面说过,路由设备返回的ICMP time exceeded message会将探测包的前28个字节拷贝至ICMP的payload。那如果路由设备做了NAT(network address translation),会发生什么结果?为了把问题描述清楚,我搭了一个如下的网络拓扑:
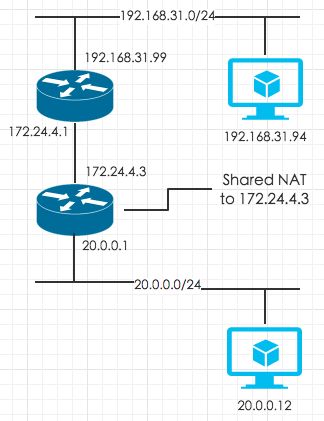
我们来看看TTL=2的探测包是怎么发送的:
第一个路由器上观察到的数据:
IP (tos 0x0, ttl 2, id 6596, offset 0, flags [DF], proto UDP (17), length 46)20.0.0.12.51016 > 192.168.31.94.33438: UDP, length 18
第二个路由器上观察到的数据:
IP (tos 0x0, ttl 1, id 6596, offset 0, flags [DF], proto UDP (17), length 46)172.24.4.3.51016 > 192.168.31.94.33438: UDP, length 18
可以看到,同一个探测包(端口号,ID一致),在第一个路由器,TTL=2,第二个路由器TTL=1,这跟前面的描述一致。并且在第二个路由器上,探测包变成了由172.24.4.3发送了。这是因为第一个路由器对探测包做了源地址NAT。
那第二个路由器如何知道将ICMP time exceeded message返回给20.0.0.12?
外层NAT
我们来看看第二个路由器(上面那个)返回的ICMP time exceeded message。
IP (tos 0xc0, ttl 64, id 55039, offset 0, flags [none], proto ICMP (1), length 74)172.24.4.1 > 172.24.4.3: ICMP time exceeded in-transit, length 54 IP (tos 0x0, ttl 1, id 6596, offset 0, flags[DF], proto UDP (17), length 46) 172.24.4.3.51016 > 192.168.31.94.33438: UDP, length 18
第二个路由器不关心数据包从哪来,只是将当前它收到的数据包的前28字节拷贝到了ICMP payload。所以ICMP内层数据是从172.24.4.3到192.168.31.94。
第一个路由器(下面那个),自然会对数据包做反向NAT,即将外层的目的地址转换成20.0.0.12。所以,第一个路由器做完外层NAT之后,数据包应该是这样的:
IP (tos 0xc0, ttl 63, id 55039, offset 0, flags [none], proto ICMP (1), length 74)172.24.4.1 > 20.0.0.12: ICMP time exceeded in-transit, length 54 IP (tos 0x0, ttl 1, id 6596, offset 0, flags[DF], proto UDP (17), length 46) 172.24.4.3.51016 > 192.168.31.94.33438: UDP,length 18
内层NAT
但是实际上,第一个路由器收到的ICMP time exceeded message是这样的:
IP (tos 0xc0, ttl 63, id 55039, offset 0, flags [none], proto ICMP (1), length 74)172.24.4.1 > 20.0.0.12: ICMP time exceeded in-transit, length 54 IP (tos 0x0, ttl 1, id 6596, offset 0, flags[DF], proto UDP (17), length 46) 20.0.0.12.51016 > 192.168.31.94.33438: UDP,length 18
内层的地址也被反向NAT了。也就是说对于ICMP time exceeded message,支持NAT的路由器需要同时对外层包和内层包做反向NAT。这样,对于源设备20.0.0.12,它感觉不到外面发生了什么,但是同时又能获取各个路由设备的信息。
RFC5508对此作了明确的定义:
NAT Behavioral Requirements for ICMP
完整的tcpdump记录在:
http://paste.ubuntu.com/23803870/
可以看到ICMP包在经过NAT设备后,内层数据也做了NAT转换。如果不对内层数据做NAT,ICMP包将会是个无效的数据包。
OpenFlow based SDN
前面说的所有的都是基于IP协议栈,而OpenFlow没有这个东西。那就意味着,如果要对基于OpenFlow的router实现traceroute,需要手动实现前面说到的功能。这包括:
路由转发时对IP数据包的TTL减1
路由转发时,对TTL=1的数据包丢弃
丢弃了TTL=1的数据包时,返回ICMP time exceeded message。
由于SDN中的虚拟路由器端口可能是虚拟的,所以要求SDN中的虚拟路由器响应UDP和TCP请求,返回ICMP Port Unreachable。
如果router支持NAT功能,还需要对ICMP error message做内层数据包NAT。
TTL减1
这个在OpenFlow中已经支持这样的action,可以在路由的时候对TTL进行减1。
丢弃invalid TTL packet,并返回ICMP time exceeded message
从OpenFlow 1.2起,支持将TTL invalid packet上送至OpenFlow控制器,在控制器内,可以生成ICMP time exceeded message,并返回给送入端口。
虚拟路由器响应UDP和TCP请求,返回ICMP Port Unreachable
匹配虚拟路由器的端口上的UDP和TCP请求,上送OpenFlow控制器,在控制器内,可以生成ICMP Port Unreachable message,并返回给送入端口。
对ICMP error message做内层数据包NAT
匹配NAT请求中的ICMP error message,上送OpenFlow控制器,在控制器内对内层数据包做NAT,再送到相应的输出端口。
上面有关实现的描述比较简单,具体的实现可以参考到我在Dragonflow项目的代码。
Support traceroute in dragonflow network
本文转载自:https://zhuanlan.zhihu.com/p/24982540