教程 | 一文入门Python数据分析库Pandas
编辑|陈韵竹&李泽南 首发|机器之心
Pandas 通常用于快速简单的数据操作、聚合和可视化。在这篇文章中,我将概述如何学习这一工具的使用。
Pandas 官网链接:https://pandas.pydata.org/
首先要给那些不熟悉 Pandas 的人简单介绍一下,Pandas 是 Python 生态系统中最流行的数据分析库。它能够完成许多任务,包括:
-
读/写不同格式的数据
-
选择数据的子集
-
跨行/列计算
-
寻找并填写缺失的数据
-
在数据的独立组中应用操作
-
重塑数据成不同格式
-
合并多个数据集
-
先进的时序功能
-
通过 matplotlib 和 seaborn 进行可视化操作
尽管 Pandas 功能强大,但它并不为整个数据科学流程提供完整功能。Pandas 通常是被用在数据采集和存储以及数据建模和预测中间的工具,作用是数据挖掘和清理。
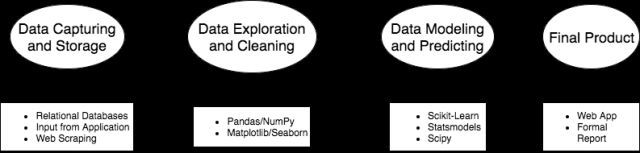
数据科学管道
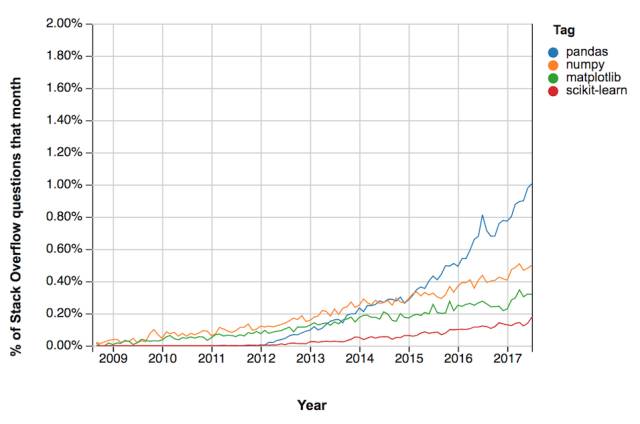
对于典型的数据科学家而言,Pandas 在数据管道传输过程中扮演着非常重要的角色。其中一个量化指标是通过社区讨论频率趋势(Stack Overflow trends app (https://insights.stackoverflow.com/trends))。
手把手教你学 Pandas
首先,你应该摆正目标。你的目标不是真的要「学习 Pandas」。了解如何在库中执行运算是很有用的,但这和你在实际数据分析中需要用到的 Pandas 知识并不一样。你可以将你的学习分为两类:
-
独立于数据分析,学习 Pandas 库
-
学习在实际数据分析中使用 Pandas
打个比方,这两者的区别类似于,前者是学习如何将小树枝锯成两半,后者是在森林里砍一些树。在我们详细讨论之前,让我们先总结一下这两种方法。
独立于数据分析,学习 Pandas 库:此方法主要包括阅读、更关键的是探索 Pandas 官方文档。(http://pandas.pydata.org/pandas-docs/stable/)
学习在实际数据分析中使用 Pandas:此方法涉及查找和收集真实世界的数据,并执行端到端的数据分析。Kaggle 数据集 是查找数据的好地方。不过我强烈建议你避免在流畅使用 Pandas 前使用 Kaggle 的机器学习组件。
交替学习
在你学习如何使用 Pandas 进行数据分析的过程中,你应该交替学习 Pandas 文档的基础以及在真实数据库处理中的 Pandas 运用。这非常重要。否则,你很容易在掌握完成大部分任务所需的 Pandas 基础知识之后对他们产生完全的依赖。但其实在更高级的运算存在时,这些基础又显得太笨重了。
从文档开始
如果你此前从没有接触过 Pandas 但是有着 Python 的足够的基础知识,我建议你从 Pandas 官方文档开始。文档写得非常详细,现在共有 2195 页。即使文档的规模如此庞大,它还是没有涵盖每一个操作,当然也不涵盖你在 Pandas 中能使用的函数/方法与参数的所有组合。
充分利用文档
为了充分利用文档,不要只阅读它。我建议你阅读其中的 15 个 部分。对每个部分,新建一个 Jupyter notebook。如果你对 Jupyter notebook 不太熟悉,请先阅读来源于 Data Camp 的这篇文章:https://www.datacamp.com/community/tutorials/tutorial-jupyter-notebook
建立你的首个 Jupyter notebook
请从「数据结构入门(Intro to Data Structures)」这个章节开始。在你的 Jupyter notebook 旁边打开这个页面。当你阅读文档时,写下(而不是复制)代码,并且在笔记本中执行。在执行代码的过程中,请探索这些操作,并尝试探索使用它们的新方法。
然后选择「索引和选择数据(Indexing and Selecting Data)」这个部分。新建一个 Jupyter notebook,同样编写、执行代码,然后探索你学到的不同操作。选择数据是初学者最难理解的部分,我专门在 .locvs .iloc 上写了一个长篇文章(https://stackoverflow.com/questions/28757389/loc-vs-iloc-vs-ix-vs-at-vs-iat/47098873#47098873),你可能想从中看到另一个解释。
在学习这两个部分之后,你应该能了解一个 DataFrame 和一个 Series 的组件,也能明白如何从数据中选择不同的子集。现在可以阅读「10 minutes to pandas」,以获得更加其他有用操作的广泛概述。和学习所有部分一样,请新建一个 notebook。
按下 shift + tab + tab 获得帮助
我经常在使用 Pandas 时按下 shift + tab + tab。当指针放在名称中或是在有效 Python 代码括号当中时,被指对象就会弹出一个小滚动框显示其文档。这个小框对我来说十分有用,因为记住所有的参数名称和它们的输入类型是不可能的。
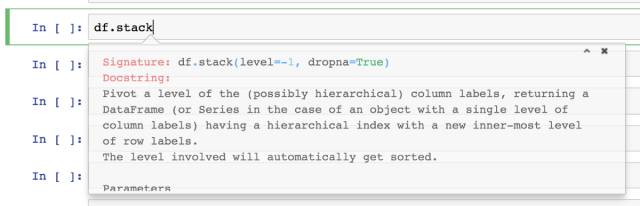
按下 shift + tab + tab,开启 stack 方式的文档
你也可以在「.」之后直接按下 tab 键,得到全部有效对象的下拉菜单
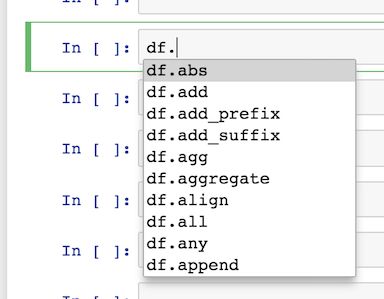
在 DataFrame(df.) 后按下 tab,获得 200+ 有效对象列表
官方文档的主要缺点
虽然官方文档描述得非常详尽,但它并不能很好地指导如何正确使用真实数据进行数据分析。所有数据都是人为设计或者随机生成的。真正的数据分析会涉及好几个、甚至几十个 Pandas 操作串行。如果你只看文档,你永远不会接触到这些。使用文档学习 Pandas 呆板而机械,各个方法学起来相互独立没有联系。
建立你的首次数据分析
在读完上述三部分文档之后,就可以首次接触真实数据了。如前所述,我建议你从 Kaggle 数据集开始。你可以通过大众投票热度进行挑选,例如选择 TMDB 5000 Movie 数据集。下载数据,然后在该数据集上新建一个 Jupyter notebook。你可能目前并不能进行高级的数据处理,但你应该能联系你在文档的前三部分学到的知识。
检视内核
每一个 Kaggle 数据集都有一个内核(kernel)部分。不要被「内核」这个名字迷惑了——它只是一个将 Kaggle 数据集放在 Python 或 R 语言处理的 Jupyter notebook。这是很好的学习机会。在你做了一些基本的数据分析之后,打开一个比较流行的 Python kernel,通读其中的几个,把你感兴趣的几个代码片段插入到自己的代码里。
如果对某些问题不能理解,你可以在评论区提问。其实你可以创建自己的 kernel,不过现在,我觉得你还是在本地笔记本上工作比较好。
回归官方文档
当你完成了你的第一个 kernel 之后,你可以回归文档然后阅读其他部分。下面是我建议的阅读顺序:
-
处理丢失的数据
-
分组:split-apply-combine 模式
-
重塑和数据交叉表
-
数据合并和连接
-
输入输出工具(Text,CSV,HDF5…)
-
使用文本数据
-
可视化
-
时间序列/日期功能
-
时间差
-
分类数据
-
计算工具
-
多重索引/高级索引
上述顺序与文档主页左侧的顺序明显不同,其中涵盖了我认为最重要的主题。文档中的某些部分没有在上面列出,你可以在之后自行阅读他们。
在阅读上述部分的文档并完成大约 10 个 Kaggle kernel 之后,你应该可以无障碍地弄懂 Pandas 的机制,同时可以顺利地进行实际数据分析。
学习探索性数据分析
通过阅读许多流行的 Kaggle kernel,你会在建立良好数据分析方面收获丰富。对于更加正式和严格的方法,我建议你阅读 Howard Seltman 在线书籍的第四章节,「Exploratory Data Analysis」。(http://www.stat.cmu.edu/~hseltman/309/Book/chapter4.pdf)
建立自己的 Kernel
你应该考虑在 Kaggle 上创建自己的 kernel。这是强制自己将程序写得清晰的好方法。通常,那些你自己写的代码都乱糟糟的没有顺序,对他人(包括未来的自己)来说都毫无可读性。但当你在网上发表 Kernel 的时候,我会建议你做得好一些,就像是期待你现在或未来老板读取那样。你可以在开头写一个执行总结或摘要,然后用注释解释每个代码块。我通常会写一个探索性但混乱的程序,然后再写一个完全独立可读的程序作为最终产品。这是我的一位学生在 HR analytics 数据集上写的 kernel:https://www.kaggle.com/aselad/why-are-our-employees-leaving-prematurely
不要只是依赖 Pandas,试着掌握它
一个把 Pandas 用的过得去的人和一个掌握 Pandas 的人有很大的区别。Pandas 的常规用户通常只能写比较差的代码,因为 Pandas 有多种功能和多种方式去实现同样的结果。编写简单的程序也很容易得到你的结果,但其实效率非常低。
使用 Stack Overflow 检验你的知识
如果你不能回答 Stack Overflow 的关于一个 Python 库的大部分问题,你就不算真正了解它。这种论断可能有点绝对,但是大体说来,Stack Overflow 为特定了解一个库提供了很好的测试平台。Stack Overflow 上有超过 50000 个带有 Pandas 标签的问题,所以你有一个无穷无尽的数据库能建立你对 Pandas 的知识。
如果你从没有在 Stack Overflow 上回答过问题,我建议你看看那些已有答案的来问题,并且尝试只通过文档来回答他们。当你觉得你可以将高质量的回答整合起来的时候,我建议你回答一些没有被解答的问题。在 Stack Overflow 回答问题是锻炼我的 Pandas 技能的最佳方式。
完成你自己的项目
Kaggle kernel 非常棒,但最终你需要处理一个独一无二的任务。第一步是寻找数据。其中有许多数据资源,如:
-
data.gov
-
data.world
-
纽约公开数据,休斯顿公开数据,丹佛公开数据——大多数美国大城市都开放了数据门户。
找到想要探索的数据集之后,继续用相同的方式创建 Jupyter notebook,当你有一个很好的最终成果时,可以将它发布到 github 上。
总结
总之,作为一个初学者,我们需要使用文档学习 Pandas 运算的主要机制,使用真实的数据集,从 Kaggle kernel 开始学习做数据分析,最后,在 Stack Overflow 上检验你的知识。
推荐阅读
21个令程序员泪流满面的瞬间 【升级版】
下载 | 斯坦福经典《统计学》教材
我的八年博士生涯——CMU王赟写在入职Facebook之前
深度学习参数怎么调优,这12个trick告诉你
收藏 | Numpy详细教程
下载 | 217页基于深度学习的文本生成
一个理工屌丝男的本硕博十年大学生活综述
收藏 | 97条 Linux 常用命令总结
