【深度学习】深度卷积网络AlexNet及其MXNet实现
文章目录
- AlexNet概述
- 网络结构
- FashionMNIST数据集实验
- 实验代码
- 结果讨论
- 参考文献
AlexNet概述
2012年,Alex Krizhevsky使用深度卷积网络在ImageNet 2012图像识别比赛中以很大的优势取胜,这一网络称之为AlexNet1。
AlexNet和LeNet(可参考笔者另一篇博文【深度学习】LeNet网络及其MXNet实现)设计理念和结构类似,但使用了更多的卷积层和更大的参数空间。具体来说有如下四个方面的区别2:
- 相比于LeNet,AlexNet包含了更多的8层变换,其中5层卷积,2层全连接隐藏层和1层全连接输出层;
- AlexNet使用ReLU函数,而非LeNet使用的sigmoid函数;
- AlexNet在全连接隐藏层使用丢弃法来控制模型的复杂度,LeNet并没有;
- AlexNet引入了图像曾广,如翻转、裁剪和颜色变化,增大了数据集缓和过拟合。
网络结构
AlexNet的网络结构如下图所示:
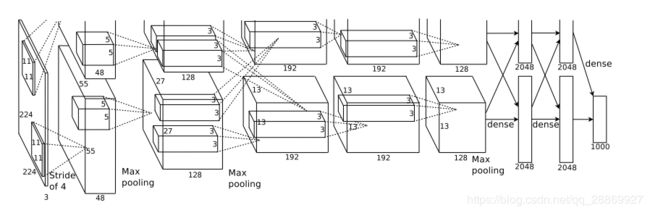
卷积层模块:
- 第1层卷积窗口为11*11。这是因为相比于LeNet,AlexNet针对的数据集为ImageNet,其中图像尺寸较大,图像中的物体占用更多的像素,所以需要大卷积窗口捕获物体;
- 第2层卷积窗口为55,之后的卷积层采用33卷积窗口;
- 第1、2、5卷积层后接最大池化层,池化窗口3*3,步幅为2;
- 相比于LeNet,AlexNet卷积层通道数增大数十倍;
全连接层模块:
- 紧接卷积层模块的是两个输出为4096的全连接层,参数规模接近1GB;
- 最后是全连接输出层,由于ImageNet中包含1000个类别的图像,所以AlexNet输出层有1000个单元。
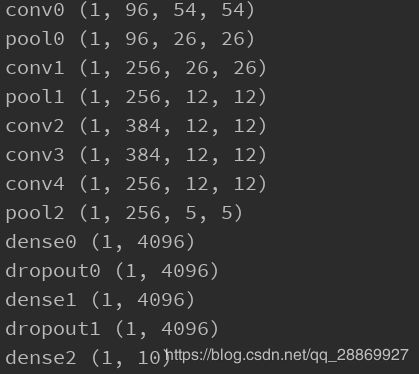
利用MXNet定义模型,并随机生成一个输入数据,打印AlexNet每一层输出数据的形状。由于本文我们使用FashionMNIST数据集(可参考笔者先前博文【深度学习】Fashion-MNIST数据集简介)进行测试,所以输出层仅包含10个单元。
# coding=utf-8
# author: BebDong
# 2019/1/23
# AlexNet:于2012年提出,用于ImageNet比赛,得名于其作者Alex Krizhevsky
# 网络结构:8层变换,包括5层卷积、2层全连接隐藏层、1层全连接输出层
# 卷积结构:第1层卷积窗口为11*11(因为ImageNet数据集图像尺寸大),第二层卷积窗口5*5,其后的卷积窗口为3*3
# 第1、2、5卷积层后都使用最大池化层,池化窗口为3*3,步幅为2
# 卷积层通道数巨大
# 全连接层结构:紧接卷积层的是输出为4096的全连接层
# AlexNet使用丢弃法控制全连接层的模型复杂度
# 这里实现一个简化的AlexNet,通过FashionMNIST数据集测试
from mxnet.gluon import nn, data as gdata, loss as gloss
from mxnet import init, nd
import mxnet as mx
# 通过Sequential定义模型
alexnet = nn.Sequential()
alexnet.add(nn.Conv2D(channels=96, kernel_size=11, strides=4, activation='relu'), # 步幅4较大程度减小输出宽和高
nn.MaxPool2D(pool_size=3, strides=2),
nn.Conv2D(channels=256, kernel_size=5, padding=2, activation='relu'), # 填充,使得输入和输出尺寸一致
nn.MaxPool2D(pool_size=3, strides=2),
nn.Conv2D(channels=384, kernel_size=3, padding=1, activation='relu'), # 连续3层卷积,通道数进一步增加
nn.Conv2D(channels=384, kernel_size=3, padding=1, activation='relu'),
nn.Conv2D(channels=256, kernel_size=3, padding=1, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
nn.Dense(units=4096, activation='relu'), # 使用丢弃法来抑制过拟合
nn.Dropout(rate=0.5),
nn.Dense(units=4096, activation='relu'),
nn.Dropout(rate=0.5),
nn.Dense(10)) # 输出层,FashionMNIST数据集为10个类别,而ImageNet中为1000
gpu_id = 0 # 将模型初始化在gpu上
alexnet.initialize(init=init.Xavier(), ctx=mx.gpu(gpu_id))
# 查看每一层输出的数据尺寸
x = nd.random.uniform(shape=(1, 1, 224, 224), ctx=mx.gpu(gpu_id))
for layer in alexnet:
x = layer(x)
print(layer.name, x.shape)
可以看到AlexNet每一层的输出数据形状,含义为:(样本数,通道数,高,宽)。
FashionMNIST数据集实验
ImageNet数据集包含1000个类别的图像,很是庞大,训练其上的模型需要耗费大量的时间,所以这里进使用FashionMNIST数据集进行模拟实验。FashionMNIST仅包含10个类别的图像,相对较小,其详细信息可参考笔者先前博文【深度学习】Fashion-MNIST数据集简介。
由于ImageNet中图像尺寸更大,为了模拟,这里在模型训练前,将FashionMNIST数据集图像进行了扩大,本文中是扩大到224*224像素大小。扩大操作可以使用MXNet提供的Resize进行,具体可以参考MXNet官方文档。
实验代码
代码逻辑和【深度学习】LeNet网络及其MXNet实现一文LeNet实验完全一致。
# coding=utf-8
# author: BebDong
# 2019/1/23
# AlexNet:于2012年提出,用于ImageNet比赛,得名于其作者Alex Krizhevsky
# 网络结构:8层变换,包括5层卷积、2层全连接隐藏层、1层全连接输出层
# 卷积结构:第1层卷积窗口为11*11(因为ImageNet数据集图像尺寸大),第二层卷积窗口5*5,其后的卷积窗口为3*3
# 第1、2、5卷积层后都使用最大池化层,池化窗口为3*3,步幅为2
# 卷积层通道数相比LeNet增加巨大
# 全连接层结构:紧接卷积层的是输出为4096的全连接层
# AlexNet使用丢弃法控制全连接层的模型复杂度
# 这里实现一个简化的AlexNet,通过FashionMNIST数据集测试
from mxnet.gluon import nn, data as gdata, loss as gloss
from mxnet import init, nd, autograd, gluon
import mxnet as mx
import sys
import time
from IPython import display
import matplotlib
from matplotlib import pyplot as plt
# 通过Sequential定义模型
alexnet = nn.Sequential()
alexnet.add(nn.Conv2D(channels=96, kernel_size=11, strides=4, activation='relu'), # 步幅4较大程度减小输出宽和高
nn.MaxPool2D(pool_size=3, strides=2),
nn.Conv2D(channels=256, kernel_size=5, padding=2, activation='relu'), # 填充,使得输入和输出尺寸一致
nn.MaxPool2D(pool_size=3, strides=2),
nn.Conv2D(channels=384, kernel_size=3, padding=1, activation='relu'), # 连续3层卷积,通道数进一步增加
nn.Conv2D(channels=384, kernel_size=3, padding=1, activation='relu'),
nn.Conv2D(channels=256, kernel_size=3, padding=1, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
nn.Dense(units=4096, activation='relu'), # 使用丢弃法来抑制过拟合
nn.Dropout(rate=0.5),
nn.Dense(units=4096, activation='relu'),
nn.Dropout(rate=0.5),
nn.Dense(10)) # 输出层,FashionMNIST数据集为10个类别,而ImageNet中为1000
gpu_id = 0 # 将模型初始化在gpu上
alexnet.initialize(init=init.Xavier(), ctx=mx.gpu(gpu_id))
# 读取数据,将FashionMNIST图像宽和高扩大到ImageNet的224,通过MXNet中Resize实现
batch_size = 128 # 批量大小
resize = 224 # resize为224*224
transforms = [gdata.vision.transforms.Resize(resize), gdata.vision.transforms.ToTensor()] # 在ToTensor前使用Resize变换
transformer = gdata.vision.transforms.Compose(transforms) # 通过Compose将两个变换串联
mnist_train = gdata.vision.FashionMNIST(train=True) # 加载数据
mnist_test = gdata.vision.FashionMNIST(train=False)
num_workers = 0 if sys.platform.startswith('win32') else 4 # 非windows系统多线程加速数据读取
train_iter = gdata.DataLoader(mnist_train.transform_first(transformer), batch_size, shuffle=True,
num_workers=num_workers)
test_iter = gdata.DataLoader(mnist_test.transform_first(transformer), batch_size, shuffle=False,
num_workers=num_workers)
# 训练模型,同LeNet
lr = 0.01 # 学习率
epochs = 130 # 训练次数
trainer = gluon.Trainer(alexnet.collect_params(), optimizer='sgd', optimizer_params={'learning_rate': lr})
loss = gloss.SoftmaxCrossEntropyLoss()
train_acc_array, test_acc_array = [], [] # 记录训练过程中的数据,作图
for epoch in range(epochs):
train_los_sum, train_acc_sum = 0.0, 0.0 # 每个epoch的损失和准确率
epoch_start = time.time() # epoch开始的时间
for X, y in train_iter:
X, y = X.as_in_context(mx.gpu(gpu_id)), y.as_in_context(mx.gpu(gpu_id)) # 将数据复制到GPU中
with autograd.record():
y_hat = alexnet(X)
los = loss(y_hat, y)
los.backward()
trainer.step(batch_size)
train_los_sum += los.mean().asscalar() # 计算训练的损失
train_acc_sum += (y_hat.argmax(axis=1) == y.astype('float32')).mean().asscalar() # 计算训练的准确率
test_acc_sum = nd.array([0], ctx=mx.gpu(gpu_id)) # 计算模型此时的测试准确率
for features, labels in test_iter:
features, labels = features.as_in_context(mx.gpu(gpu_id)), labels.as_in_context(mx.gpu(gpu_id))
test_acc_sum += (alexnet(features).argmax(axis=1) == labels.astype('float32')).mean()
test_acc = test_acc_sum.asscalar() / len(test_iter)
print('epoch %d, time %.1f sec, loss %.4f, train acc %.4f, test acc %.4f' %
(epoch + 1, time.time() - epoch_start, train_los_sum / len(train_iter), train_acc_sum / len(train_iter),
test_acc))
train_acc_array.append(train_acc_sum / len(train_iter)) # 记录训练过程中的数据
test_acc_array.append(test_acc)
# 作图
display.set_matplotlib_formats('svg') # 矢量图
plt.rcParams['figure.figsize'] = (3.5, 2.5) # 图片尺寸
plt.xlabel('epochs') # 横坐标
plt.ylabel('accuracy') # 纵坐标
plt.semilogy(range(1, epochs + 1), train_acc_array)
plt.semilogy(range(1, epochs + 1), test_acc_array, linestyle=":")
plt.legend(['train accuracy', 'test accuracy'])
plt.show()
结果讨论
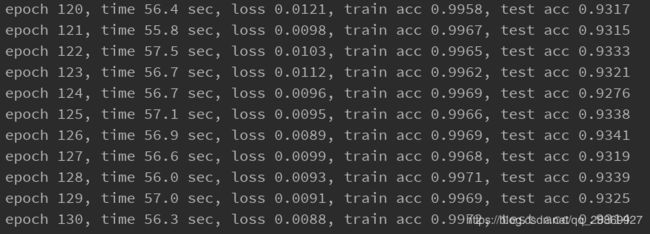
笔者设置的参数如上代码所示,得到结果:
我们作出准确率随着epoch的变化曲线图:
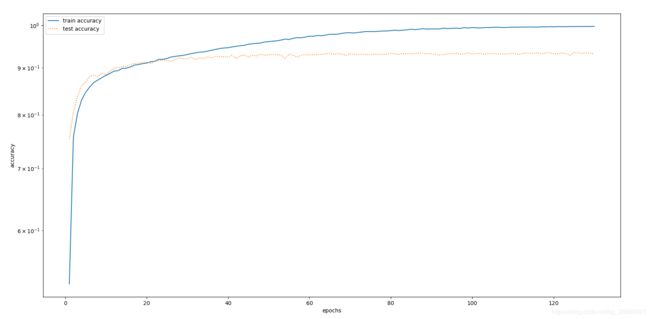
从上面的结果中可以看到,随着训练次数的增加,虽然训练的准确率持续提高,几乎接近100%,但是测试准确率在第50个epoch往后基本维持在93%,已无明显变化。对比【深度学习】LeNet网络及其MXNet实现一文中对FashionMNIST数据集的实验结果有所提升。
其实AlexNet模型对于FashionMNIST这样的数据集来说还是稍显复杂,非常容易出现过拟合现象,测试准确率反而下降。
参考文献
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105). ↩︎
Aston Zhang, Mu Li et al. Hands on Deep Learning[EB/OL]. http://zh.d2l.ai/chapter_convolutional-neural-networks/alexnet.html ↩︎