centos7下完全式hadoop集群搭建
初入数仓坑,搭建hadoop集群折腾了几天险些让我崩溃,好歹是让我看到了结果:
当然虽然过程坑了点耗费了相当心力,但好处是对配置的理解更明白了些,当然流程更是烂熟于心了。下面就开始总结吧:免密通信就不提了需要的话可以直接戳http://blog.csdn.net/qq_29186199/article/details/78428498。
首先说下环境,我是在centos7下面安装的二进制hadoop包(上链接:http://hadoop.apache.org/releases.html),如下图:

1、我将所需要的文件解压到了/usr/local/software(该文件是我自己创建放下载的软件包),解压后放到local目录下并更名Hadoop,jdk8,如图:

2、接下来配置环境变量(知道肯定有人手懒,贴码),如下图:
(只看java与hadoop环境变量配置)
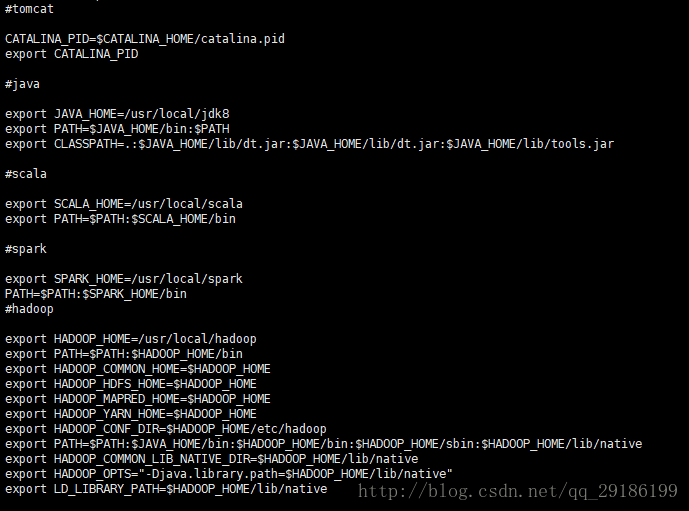
#java
export JAVA_HOME=/usr/local/jdk8
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib/native
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
写入配置信息之后别忘了source /etc/profile使配置生效。
3、nano /etc/hosts 进入该文件编辑主节点与子节点信息,我的节点信息如下:
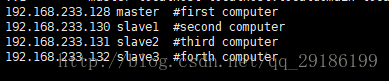
事实上,这里只要写主机IP或者主机名(hostname可以查看主机名,vi /etc/hostname可以永久修改主机名,其他方法都更改的话这个方法优先级别最高,自测欢迎指正)其一就可以,都写的话也不错。
4、接下来就是配置Hadoop文件了,我用的是root账户所以各文件无所谓权限不够的问题了(自己玩的嘛/尴尬笑),首先进入Hadoop主目录(我的cd /usr/local/hadoop):
创建新文件tmp和hdfs以及hdfs下面的name和data文件夹上命令:
mkdir {tem,hdfs} , cd hdfs , mkdir {name,data}上图(总结嘛怎么可能是实时的):

5、接下来配置文件,根据个人需要主要有以下几个,不敲了上图:
![]()
接下来一个一个来:
vi core-site.xml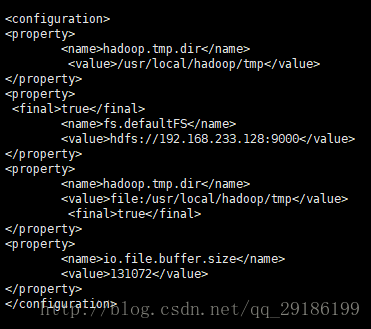
<configuration>
<property>
<final>truefinal>
<name>fs.defaultFSname>
<value>hdfs://192.168.233.128:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
<final>truefinal>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
configuration>
vi hdfs-site.xml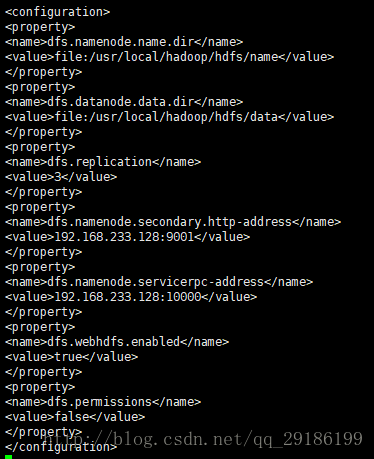
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/hdfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/hdfs/datavalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>192.168.233.128:9001value>
property>
<property>
<name>dfs.namenode.servicerpc-addressname>
<value>192.168.233.128:10000value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>
vi mapred.xml(MapReduce的配置文件)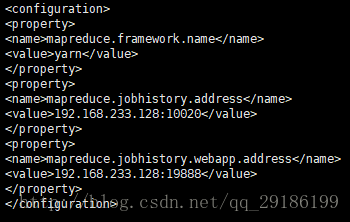
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>192.168.233.128:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>192.168.233.128:19888value>
property>
configuration>vi yarn-site.xml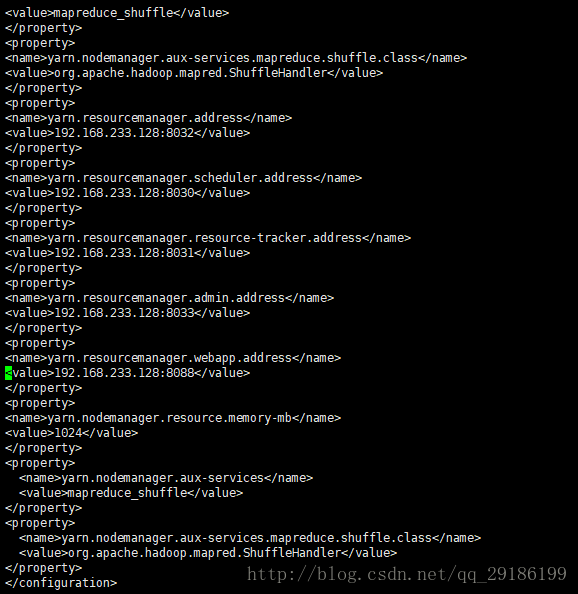
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>192.168.233.128:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>192.168.233.128:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>192.168.233.128:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>192.168.233.128:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>192.168.233.128:8088value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>1024value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>
vi hadoop-env.sh
export JAVA_HOME=/usr/local/jdk8/
vi yarn-env.sh![]()
export JAVA_HOME=/usr/local/jdk8vi slaves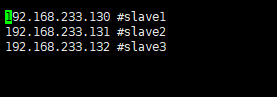
至此主节点配置Hadoop配置完成。
6、把主节点服务器即master主机下的/etc/profile,hadoop主目录即:/usr/local/hadoop,和jdk主目录即/usr/local/jdk8复制到其余各个节点服务器,即:
scp -r /etc/profile 192.168.233.130:/etc/
scp -r /usr/local/hadoop 192.168.233.130:/usr/local/
scp -r /usr/local/jdk8 192.168.233.130:/usr/local/
scp -r /etc/profile 192.168.233.131:/etc/
scp -r /usr/local/hadoop 192.168.233.131:/usr/local/
scp -r /usr/local/jdk8 192.168.233.131:/usr/local/
scp -r /etc/profile 192.168.233.132:/etc/
scp -r /usr/local/hadoop 192.168.233.132:/usr/local/
scp -r /usr/local/jdk8 192.168.233.132:/usr/local/
复制过去之后不要忘记source /etc/profile 使配置生效,另外这里提一下吧,hadoop里面的几个修改的文件各自主机用各自主机的IP(我就在这里面绕不出来了)。
7、第一次启动首先格式化HDFS:
cd /usr/local/hadoop/sbin
hdfs namenode -format
说明:只要看到/usr/local/hadoop/hdfs/name 被格式化成功就没问题了
启动HDFS:start-dfs.sh。
java自带jps命令验证:
主节点:
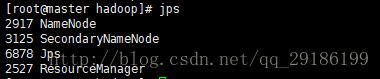
子节点:
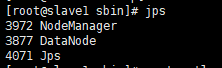
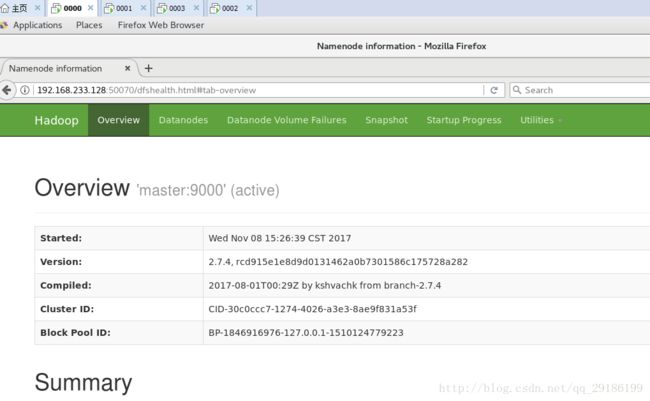
页面验证:
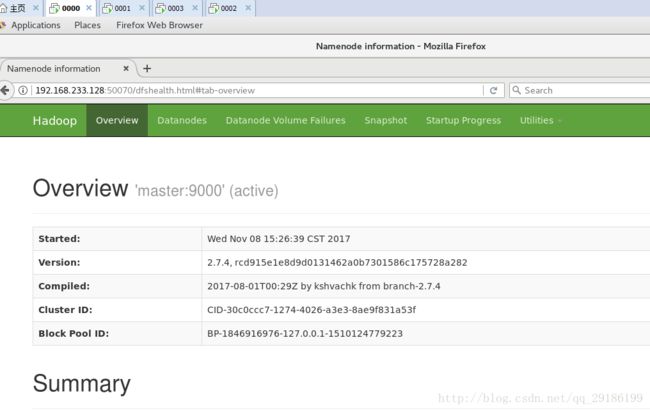
没毛病
8、至此hadoop的配置基本完成,其他组件有需要再加希望帮到正在焦头烂额的朋友,在此也感谢官方文档和Hadoop构建数据仓库实践,是个好东西。