Docker+Git效率工作
前言
事情是这样的,首先之前不知道git这个利器,就把代码复制来粘贴去,一个人写代码还好,几个人,特别是一个团队协同工作,这种复制粘贴,U盘拷贝代码,QQ发来发去代码的方式简直就是噩梦,非但麻烦,而且非常凌乱,反正我是受不了。然后,知道git以后才发现自己和它相见恨晚,先别说什么版本控制工具,首先光是托管代码就让我爽一番(svn工作流模式),请注意,我现在是以完全菜鸟的视角阐述,大神们请掠过。
引入了git,整个协同工作有条不紊多了,我的思路也清晰多了,可是问题又来了,项目开始的时候我只是考虑本机开发的问题,嗯,在本机的确没有问题了,但是后面有个新人加进项目后有个问题突然暴露了出来——多人协同开发中除了代码还有环境[环境描述,依赖,缓存,参数,配置等]!首先他和我习惯用不同的系统开发(他用windows,我用linux - -),然后各种环境问题(一会儿缺这个包,一会儿又编译不通过,等下报个错,分分钟折腾死你)。讲真,加班加点不重要,我突然想到,如果以后要部署到很多服务器,那岂不是又要重重复复做同样的功夫?想想都心累,可是docker解决了我这个困扰。
docker是个热门的虚拟容器的技术,其实我是想都没有想过要用到它的时候,虽然我之前知道有docker这么一个玩意,好像很牛逼,但是也就是仅仅停留在知道的程度,至于它能做什么,为什么会存在,我没有任何概念,我曾一度想看懂一点docker,但是各种什么虚拟啊,容器啊,完全搞不懂,想想那时候还是大二的懵懂青春.
git+docker,一个管理代码,一个管理环境
Git
Git相信大家都不陌生,git是linus大神继linux内核以后又一个杰作之一,关于git的历史,可以上Wikipedia看一看,然而在说git之前,我想聊聊svn。
svn也是一种版本控制工具,其实“版本控制工具”这个词乍一听完全不知所云,那就抛开它的定义,直接说它究竟做了什么。一开始呢,写代码的人不多,大家就直接把代码传来传去就好了,对,就是我在前言里面说的各种复制粘贴,QQ传什么的,当然国外不用QQ,可是传着传着就乱套了,你的是什么时候的代码,然后我的又和你发布有什么不同,修改了哪里等等,简直乱成一锅粥,特别是团队的管理者,最不爽就是这种状况,把自己都搞乱了还得了?这时候svn诞生了(当然还有其他的版本控制工具,我这里以svn作为代表),svn是集中式的代码管理,也就是说得有一个中心的svn服务器一直管理着代码,开发者本地是没有这个仓库的,当开发者修改完代码,或者有什么新的代码,就直接提交到中心的svn服务器就好了,非常清楚明确,但是有个很大问题就是,万一中心的svn的服务器挂了呢?或者是我连不上中心的svn服务器?那我岂不是干等着修复问题,而没有办法立即工作?那我打盘阴阳师再回来吧:)
开玩笑的,没有办法立即工作是很不爽的一件事,有什么办法?git,这家伙是分布式的,何为分布式?就是每一个开发者都有一个代码完整的代码仓库,中心服务器就算挂了或者网络无法链接的时候,可以通过其他有仓库的同事克隆一份,而且它可以先提交到本地的仓库,再等中心代码仓库好了或者网络恢复了再一个push命令提交到中心代码仓库,是不是比svn好那么一丢丢?其实基于这个特性,git好的其实不只是一丢丢,不过这个好处得你自己玩玩才能够更加细致地体会了,我就不展开来讲了.
但是svn还是有存在的价值,因为svn的简单易用,而且方便集中式管理,所以企业非常偏爱svn,外加git有一定的学习成本,虽然我倒是不觉得git能有多少学习成本…..- -
Git几点须知
git本身不追踪目录的变化,所以你创建一个空目录,你会发现提交的变更里面并没有这个你创建的空目录,你要问了,如果不追踪目录变化,那为什么我改变了一个目录的名字,而变更又会被包括进去呢?那是因为你这个目录下存在文件,你改变了目录的名字,相当于改变了这个目录下的文件的路径,也就是说改变了文件,所以git要追踪这个变化.
本地的代码仓库由工作区,暂存区和本地分支组成:工作区就是你现在的路径下的文件,而暂存区就是git自己缓存区,把add放在这个区域中,最后就是本地分支,暂存区commit就是commit到本地分支了
工作区<==>暂存区==>本地分支<==>远程仓库分支什么是.gitignore,README.md,LICENCE?
其实我一开始看到github项目里面都会有.gitignore,README.md这两个文件,我也不知道是啥,就懵懵懂懂地往自己的项目加这两个文件,我也是后面才知道,README.md是markdown文件(后面以md作为后缀,markdown写东西体验挺好的,它还有自己的语法,强烈推荐~),里面要写一些你想告诉看你代码的人的话,然后.gitignore的话,我是遇到需要屏蔽一些比如python的pyc文件,不想这些文件放进我的代码仓库,我才知道这个.gitignore有什么用,它就像它字面说的那样ignore一些东西。至于LICENCE的话,主要指的是开源许可,现在主流的就是GPL,BSD,MIT,Apache等等,你可能都有耳闻,它们之间的关系可以这样表达[感谢阮一峰老师做的图解]: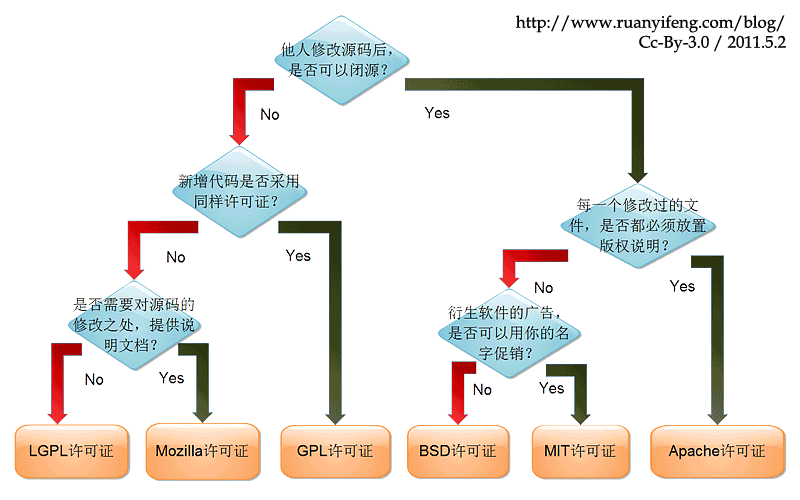
这里我稍微梳理下git的常用指令,贴上来供参考
git命令大合集
git init repo #初始化一个叫repo的本地git仓库
#实际上就是创建一个repo的目录,然后目录下放一个.git,.git包含了git的所有记录,判断一个目录是否为git仓库,就看有没有.git目录,有.git目录往下都属于同一个git仓库
#如果你把.git这个目录删除了,你的代码虽然还在,但是你的历史变更记录就全部没有了,所以一般别动这个.git
git add file #往暂存区添加一个叫file的文件
git diff #对比修改内容和git中最新记录的commit的区别,最好在add之前用git diff看一看,避免一些像加了空白键那种无效提交
git add . #往暂存区添加在git status中提示需要add的文件(git status不会提示被.gitignore忽略的文件)
git commit -m "blablabla" #把暂存区的内容正式提交到本地的当前分支,其中那个blablabla就是对本次提交的说明
git commit
# 最近实践发现加了-m,我会尽可能挤成一行来写,但是push到github后,查看commit的时候就发现写的记录信息全部挤在一行,难看死了,有些还被忽略了
# 所以不如直接git commit记录比较全面的信息
# 不过之前得先指定git config --global core.editor /usr/bin/vim,不然貌似默认用的是vi,vi的话就有可能在你保存的时候会崩溃
# 以至于你写的一堆提交信息全没了.
#git commit 还有一个-a的选项,是表示连同未add的文件改动也一同加进来,因为你可能add以后又改动了文件,而一般你前面add了内容就只用-m就可以了,不用-am
git status #查看当前所在git仓库情况
git log #查看提交历史,你会看到你自己之前commit时候的说明,各种blablabla
git reflog #查看操作历史
git clone HTTPS/SSH #克隆一个项目
# 常见的要么就是长成https型的(e.g. https://github.com/tesseract-ocr/tesseract.git)
# 要么就是长成ssh型的(e.g. [email protected]:tesseract-ocr/tesseract.git)
git remote -v #查看远程代码仓库的信息
git remote add origin HTTPS/SSH #添加一个叫origin远程仓库地址,一般克隆自带,如果是本地新创建的话就得执行这句,然后才能push
git remote remove origin #删除一个叫origin远程仓库地址
git push origin <本地分支>:<远程分支> #如果没有冒号后面的,此时默认推送到远程origin仓库的与<本地分支>同名的分支,如果不存在,则会被新建
git fetch --all #这条命令一般用于如果有人远程push了一条分支到repo,你本地想要拉下来,直接checkout提示本地没有,就可以fetch全部分支了~
git pull origin <远程分支>:<本地分支> #如果没有冒号后面的,此时默认拉取并合并远程仓库origin的 <远程分支>到当前分支,pull相当于fetch+merge
git pull --rebase origin dev <远程分支>:<本地分支> #拉取远程git代码仓库origin的dev分支更新,并以重建的方式合并到本地分支
#一般要是嫌麻烦,就像上面那样直接pull就好了,有些洁癖者喜欢用rebase保证本地的线性干净,本地可以rebase,远程就别这么做了
git merge --no-ff dev master #合并本地dev分支到master分支,洁癖者会为了干净历史加上--no-ff选项(--no-ff意思是no fast forward非快进式合并,某公司面试问了--no-ff含义)
git merge --no-ff dev #合并本地dev分支到本地当前分支,洁癖者会为了干净历史加上--no-ff选项
#冲突解决:在pull 和merge的时候会因为合并双方文件内容不一样而导致冲突,它会显示给你发生冲突的文件,并自动在冲突文件中标注好不一样的段落
#解决冲突其实已经有很多很好的工具了(比如vimdiff之类的),但是我觉得这些工具都稍显得复杂不简约,所以我推荐直接用vim打开发生冲突的脚本,手动修改好,保存
#用vim修改(sublime也不错)清晰方便,再add==>commit==>push就没问题了(第二次push是以你修改后提交为准,git这时候并不理会远程仓库的文件内容,直接覆盖过去~)
#或者修改好冲突以后就git add冲突的文件,再git merge --continue或者git rebase --continue,省去了commit的功夫
git branch #显示本地所有分支
git branch -D dev #-D是-d --force的shotcut,强制删除dev本地分支
git push origin :dev #删除远程仓库的dev分支,相当于把一个空分支push到远程仓库的dev上,等同于删除该分支。
git checkout -b dev #切换到dev分支,-b是没有dev分支时候才需要加上去的,这种情况下是创建并切换到dev分支的意思
git checkout -- file #撤销工作区中一个叫file的文件的修改
git reset HEAD file #撤销暂存区中一个叫file的文件到工作区中
git reset --hard HEAD^ #回滚当前分支到上一个版本,注意末尾的^,有n个^说明回滚多上个版本,也就是回到多少次commit前
#貌似把上面的file 换成*(wildcard)通配符来代指所有是可以的.我就经常多文件撤销工作区修改的时候git checkout -- * ,纯粹因为懒得一个个输入... git stash
#真是没有遇到问题就找不到来学习,用了那么久的git,现在才知道git stash这东西
#使用场景:
#当前工作区内容已被修改,但是并未完成(往往是写到一半有多).
#这时Boss来了,说前面的分支上面有一个Bug(容易出现在线上hotfix),需要立即修复。
#可是我又不想提交目前的修改,因为修改没有完成。
#但是,不提交的话,又没有办法checkout到前面的分支(checkout会报错)。
#此时可以用Git Stash就相当于备份工作区了。
#然后在checkout过去修改,就能够达到保存当前工作区,并及时恢复的作用
#简单应用:(最好不要过多缓存,因为pop的时候容易conflict)
git stash 缓存工作区修改
git stash list 当前的git stash栈打印出来
git stash pop 恢复所缓存内容
git stash clear 清除全部所缓存内容
git stash pop 相当于 git stash apply 加 git stash drop
Reference:
1.Git Stash用法
2.Difference Between Git Stash Pop And Git Stash Apply
3.Git Stash Pop Considered Harmful
4.(Highly Recommended!) Git Stash Tutorial
P.s. 在我用git的时候发生过一个小错误:
“fatal:refusing to merge unrelated histories”,我用的是git2.9.3的版本,然后想要合并远程仓库,可能本地和远程仓库提交历史区别太大,所以会产生这种错误,幸好网上都有答案,其实是git在2.9版本后添加的一个安全措施,避免无相关历史的两个仓库合并在一起,防止误操作的发生,以避免污染了两个代码仓库–“since git 2.9.* ‘git merge’ used to allow merging into branches that havo no common base by default ,which led to a branch new history of an existing project created and then pulled by an unsuspecting maintainer which allow an unnecessary parrallel history merged into the existing project.Here is an escape hatch(逃生舱)”
解决的办法 : 在merge的时候加上–allow-unrelated-histories就可以了
Git本身如果只是要用的话没什么好说的,就是一堆指令,它的精华的地方在于它与它的一些工作流(WorkFlow)结合。不过其实所谓工作流说白了就是开发人员之间,团队内要怎么配合和协调,人与人之间沟通都做不好,工具再好也只是一个空壳而已。
Git工作流
所谓工作流就是团队的怎么打配合,配合的方式可以有千万种,我不敢说哪种配合方式是最好的,我下面主要聊聊我所使用的,仅供参考
一般项目都会分成两个主要分支(至少我现在看过的项目都是),一个是master分支(主分支),一个是dev分支(开发分支)或者是demo(测试分支),master分支应该是最稳定的,而dev/demo则是日常开发更新变动最频繁的,其实对于开发者来说,只用管dev/demo就好了,master分支一般都是项目管理者觉得是时候而且足够稳定,才把dev/demo合并到master发布。
还有另外的一些分支,比如你在开发的时候需要开发一个新功能可以另外从dev中checkout一条新分支来开发新的功能,又比如上线到master代码中被发现了bug,也可以从master分支checkout一条hotfix分支来及时修复bug。这些都可以灵活搭配的 ,只要清楚现在主流都是master-dev这两条主要分支就好了Github工作流(17.9.23更新)
最近又学到了一个工作流,github工作流,这个工作流特点是dev/demo和master永不相交,因为不希望dev/demo的一些期望以外的代码带到master,造成意料以外的状况。那么我的新功能分支又该如何合并到master?直接合并是不行的,毕竟没有经过部署测试过,所以在这个工作流里面你的新功能分支要先merge到dev/demo,等测试到没有问题了,再直接把这条新功能分支merge到master。
你如果习惯了上面的git工作流中的dev/demo测试没问题直接合到master,你会发现新的工作流会不太适应,特别是如果master和dev/demo历史不平行的时候。
当你发现你用github工作流,然后要处理很多conflict,说明你的使用方式存在问题。基于这条工作流的特点,你得把你的要做功能分解到更加细小的更新上,然后尽可能快的完成,提交到测试(合并到dev/demo分支),然后尽可能快地验证,ok就直接merge到master推到线上去,你会感受到整个节奏比以往更加快捷,而且更新粒度会更加小,master会波动更加频繁,所以最好你的部署方式是用户无感的,不然这种master频繁波动会导致频繁部署,而频繁部署会造成频繁的服务中断,用户。解决办法是:要么你就寻找一种平滑过渡的部署方式(docker & docker compose),要么就是还是用回Git工作流那种,一个版本更新一次master好了,即先不断把功能提交到dev/demo,最后统一测试过了,再merge到master,这样也才1-2周中断一次,而不是每天都中断,而githubflow就是持续地提交,部署,提交部署,至少每天一次…
扩展推荐:
1.廖雪峰老师的git基础教程
2.阮一峰老师的git工作流讲解
3.Linus Torvalds on git [Highly Recommended !!! ]
闲话
稍微聊聊为什么选择git作为版本控制工具 [而不是其他的一些CVS,SCM,SVN(Subversion),Merurial etc.]
在程序员世界里面,只要一件事情有同类的工具,这些工具总会有“xxx最好”之争(e.g. PHP是世界上最好的语言),我无意说git是世界上最好的版本控制工具,但是我可以给你几点理由,以下几点理由有些是上网看到说的在理的,有些是个人感悟,你随意参考便可:
1.svn分支代价高;
2.快速开发时候,团队总会遇到conflict,svn提交时候发现其他人提交而且出现conflict,想checkout却发现无法进行,而git用分支结构,每个人走一个分支,conflict出现机会少了,在代码合并时候一次性处理掉conflict,压力不会太大;
3.git是分布式的,每个人都有一个完整的仓库copy,各种commit版本操作切换不需要依赖server,而svn不行;
4.svn下载源码慢[据说几个G文件git需要10min,而svn则需要1h]
5.git鼓励commit,而commit越频繁,后面出现问题的几率小很多,而且出现问题需要承担的担子也会小很多;
6.git makes merge easier!
7.每个工具都有它擅长和不擅长的地方,git也有,它在对付源代码很擅长,但是对付一些大文件(比如影音/高清图片/高品质音频),git甚至会连svn都不如,但是本来git设计就是为了源码的啊…..
16.11.17:这几天用git commit了几个大文件(准确来说是大的二进制文件)到本地分支,然后后面又删除这几个大文件后再commit,最后push的话,发现很大,要push很久,暂停用du -h看看项目大小,发现最大的竟然是.git,稍微算了一下大小和我没有删除的几个大文件之前的大小差不多。原来我虽然已经把项目中删除了那几个大文件,但是.git还帮我保存了一份,这就是为什么git能回滚的原因- -,这真的是呵呵呵了,以后再也不敢commit大文件了,其实主要是Dockerfile要用到的一些软件,我也打包进去了。现在push的话项目太大了,而且容易出现超时失败的问题,我的解决办法是,把本地的.git删除(我不敢reset回滚,因为我在commit时候除了大文件还有一些源代码的修改,回滚的话我修改就没了),然后init一个,再checkout -b一条本地的dev分支,add&commit,最后push,push受限,再pull,发现冲突,解决冲突,再add&commit,最后再push就解决了,所以以后除了源代码,一些依赖的很大的软件最好就不要commit到本地分支了,你push都得有排等.
但是这种办法仅仅适合个人项目,简单粗暴,像公司项目就要慢慢用git gc还有git filter-branch之类一点点清理了,或者如果你只是关心Jenkins自动部署中git拉取代码体积太大的问题,可以看看jenkins的shadow clone
Ref:
1.Removing sensitive data from a repository
2.Jenkins hints for large git repos
3.pro git书里面也有提到git filter-branch7.6 Git 工具 - 重写历史
建议可以看看pro git这本书对git 原理的讲解,我觉得写的很好,它也有线上版本——Pro Git book,理解git原理是你熟悉了一般协作的git命令以后必须要去做的事情~
Docker
作为现在比较火的技术之一,我真不敢说自己能道出其中真理,可是光是用的话,我还是能说说使用感受的。
前言也说了,我用docker并不是因为它多火热,而是因为他帮我解决了几个小问题:首先是系统问题(Linux/OS X/Windows),同样的开发环境,我在linux环境下搭起来非常熟练,不要问我为什么这么熟练,你自己搭多几次就知道了,但是到了windows就不太一样了,操作也好,路径也罢,同样的套路是行不通的,其次就是每搭建一次,我都得从头开始装软件,源码的用源码编译安装,配置环境变量,创建路径等等,第一次你可能新鲜,等你装个两三次就知道有多麻烦,所以能不能就麻烦一次,以后就不麻烦了呢,而且向下能对不同操作系统起到最大程度的屏蔽呢?
16.11.24更新:推荐一篇文章,可以一定程度解决你的困惑,不会涉及太多技术—–为什么能用Docker做那么多事情?
幸好之前有看过docker的一些文章(平时看看各种技术,说不准就那天用上了,手动滑稽:D),docker可以一次配置,随处运行,嗯….貌似很不错,可是刚开始我也是没底的,因为我怕和我的预期有偏差,可是我上网找来找去还是觉得官方的doc做得最适合入门(尽管是英文的,但是作为入门还是比一些中文的要好),其他的一些文章都说的很深奥,搞得我以为如果要用docker我必须把docker原理搞懂才有资格使用docker
Docker是一个daemon,用windows的话说就是一个进程,用过VMware虚拟机的同学,你也可以把docker想象成为一个超小型的虚拟机,然而它并不是虚拟机,它和VMwareWorkStation(还有VirtualBox,KVM,Hyper-V,Xen等)这种系统级虚拟的还是有不同的,docker基于这种轻量级&小开销的特性,可以比较干净地做到运行环境的隔离,而且能在秒级完成启动.
上面都是谷歌拼凑到的,其实docker如果只是用的话也就是一堆命令,欧,还有一个Dockerfile的编写,为了方便你后面好理解docker的使用,我得先说明docker中三个主要的东西:Dockerfile,镜像和容器
Dockerfile
github中项目中一般都会有.gitignore,README.md,有时候还会有个Dockerfile,.gitignore和README.md我们都知道是什么,那么Dockerfile又是什么呢?Dockerfile自然就关联到docker了,它是面向开发者(Dev)的,开发者把需要什么系统,需要装什么软件,需要怎么配置环境等等全部都写进Dockerfile里面,相当于是一个基于docker的全自动生成镜像的一个脚本,至少我是这么理解的。而有个这个Dockerfile,别人只用在这个Dockerfile的目录下执行docker build -t image:tag 就可以由你的Dockerfile生成镜像,是不是很方便?
自从有了Dockerfile,开发者就可以取代一部分原来由运维(Ops)做的部署工作(deployment),也就加强了运维和开发的联系,加快的了工作的效率,其实Dockerfile还不算最高效率,最高的效率是直接移植现在做好的docker镜像,把Dockerfile build中各种网络下载安装,还有编译的时间都省去了,真的做到开箱即用镜像
镜像是docker的静态,由Dockerfile生成的是镜像而不是容器,你可以通过sudo docker images查看你现在有多少的镜像,docker的镜像是docker移植的关键,当然容器也可以export出来再import回去,但是一般都是save和load docker镜像为主容器
容器是docker的动态,由镜像run出来的(sudo docker run),容器是docker的精华,你可以理解为容器技术就是应用了集装箱的思维,把所需要的所有东西都放进一个集装箱(container)里面,哪里需要服务,我直接把整个集装箱运过去,然后你进去集装箱享受服务就好了
容器是不会自动保存改动到原来的镜像的,除非你commit容器形成一个快照,但是这个操作其实就是将现在改动过的动态的容器新存为一个静态的镜像,而不是保存为原来的镜像。
[Docker的安装和启动具体教程请参照官网的文档页面的docker engine下的install就足够了,https://docs.docker.com/ ,然后如果你发现sudo service docker start去启动docker服务,输入docker的指令后却没有反应,然后sudo service docker stop + sudo service docker start/sudo service docker restart重启docker 服务却没有反应,请ps -ef|grep docker察看所有docker进程,并且kill掉它们,再sudo service docker start就没有问题了,我试过两次,亲测可行,考虑应该是之前docker的服务没有正确关闭的原因,如果还出问题,那就请自行谷歌.]
同样也是梳理了下命令
#从当前目录下的Dockerfile(命名dockerfile好像也能识别,其他就不行了)建立镜像
sudo docker build -t reponame:tag .
#别忘了最后那个.!
sudo docker images #查看镜像
sudo docker ps #查看当前运行的容器
sudo docker ps -a #查看全部容器(包括运行中的和停止的)
sudo docker run -it --name blabla -p <物理机>:<容器>(e.g. 127.0.0.1:3306:3306) -v /your/local/path/:/map/path/in/docker/ -v /etc/localtime:/etc/localtime --net =host -d reponame:tag
# 启动容器
#[-it 是启动交互和伪终端]
#[-p :<宿主机端口>:<容器端口> 将宿主机(物理机)映射或者可以理解为绑定,可以指定,也可以不指定,不指定默认是0.0.0.0,建议还是指定]
#[-v 是挂载本机目录到到docker目录,最好每次都把-v /etc/localtime:/etc/localtime也带上,确保docker 容器内时间和服务器时间一致]
#[-d 是daemonize的意思,就是使容器成为守护进程,后台运作]
#[--net是设置docker的网络模式,默认不设置的话就是bridge模式,现在设置为和物理机网络绑定的host模式,更多可以看 Docker的4种网络模式(http://www.cnblogs.com/gispathfinder/p/5871043.html)
#[--link 是容器链接]
#复习几个特别的IP:
#①127.0.0.1是本地回环地址,代指本机; [对于绑定在127.0.0.1的端口而言,外部无法访问,不对外打开,仅仅对内打开]
#②0.0.0.0 代表所有不清楚的IP,安全性差,也是指本机?;[对于绑定在0.0.0.0的端口而言,外部可以访问]
#③255.255.255.255 用人类的话说:“嘿,这屋子的所有人听着了!”
#④localhost 这个是域名,一般都是127.0.0.1,这种对应关系写在你的/etc/hosts里面
sudo docker start/stop/restart/rm blabla #启动/停止/重启/删除 容器
sudo docker cp blabla:/app/file.txt . # 把docker里面/app目录下的file.txt文件复制出来到现在所在的目录
sudo docker exec -it blabla /bin/bash #在启动的容器blabla中运行/bin/bash
sudo docker exec -it blabla /the/path/of/your/command
sudo docker commit blabla repo:tag #提交保存容器到一个新的镜像repo:tag
sudo docker rmi repo:tag #删除镜像
#容器的导出和导入
sudo docker export
sudo docker import
#镜像的导出和导入
[文件]
sudo docker save repo:tag > backup.tar
sudo docker load < backup.tar
[dockerhub]
sudo docker login
sudo docker push repo:tag
sudo docker pull repo:tag
#常用组合命令
#停止所有docker容器
sudo docker kill $(sudo docker ps -q)
#删除所有docker容器
sudo docker rm $(sudo docker ps -aq)
再来张好图,帮助理解命令:

更多关于docker的命令这里有个中文的docker命令大全,如果觉得不够全面,那就官网doc,或者谷歌百度.
最后放一个docker的WebApp应用简易模型:
(强烈推荐ProcessOn在线作图)
下图说明:
①首先是两个容器App代表应用容器(以Tomcat为例),而db代表数据库容器(以Mysql为例),并且两个容器通过–link name相连,准确来说是App容器去–link 连接db容器;
②两个容器分别通过-v向下挂载数据卷,App容器挂载物理机的项目代码目录/project(/project和容器分离,使得代码和环境互相更加干净而不会相互影响),而db容器则挂载物理机的数据存放目录/data;
③两个容器都通过-p 和物理机器端口做了映射,App容器的8080端口和物理机的8080端口对应了起来,而同样的db容器的3306端口和物理机的3306端口对应了起来
(容器和物理机端口对应起来,那么你就可以通过物理机上执行mysql -h localhost -P 3306 -u root -p ,然后键入密码登陆你容器内的数据库了,这一点很重要,因为很方便测试和观察结果,让流程更加清晰)
④无论是开发者测试还是最后环境的部署都可以用下面的模型
⑤平时做开发的时候,我都是在docker容器外(即物理机上)编辑代码,当然还有git管理代码,然后在容器内跑代码.
(详细的可以参考这篇博客,特别是注意mysql容器run 的时候要加-e 指定mysql数据库的登陆密码,这个上面说docker命令的时候没有说到)

Windows机上的实践[16.11.3更新 ]:
因为Docker是Linux的亲儿子,所以在windows中使用docker并不会有丝滑般的体验- -这两天就是在公司一台WindowsServer 2008 R2部署,我是用docker toolbox装docker的,一开始不知道这个Windows Server 2008 R2系统是用Vsphere虚拟出来的,然后安装就出错了![Error in driver during machine creation : read tcp 127.0.0.1:65369 ==> 127.0.0.1:65368 wsarecv:An existing connection was forcily closed by the remote host] ,直到现在这个错误不好意思还没有解决,但是是可解决的,因为根据公司运维小哥所言,虚拟机里面弄docker容器所说应当可行,具体的这个错误怎么fix得细致去分析,于是我就切换到另外一台Windows Server 2008 R2部署了: ),到时候回头有空再回来fix (虚拟中的虚拟的问题[KVM中ToolBox]?)
这次的Windows Server 2008 R2系统是物理机器,不是虚拟出来的,但是还是遇到了问题,就是BIOS的VT-x这个intel虚拟化技术没有启动,这个好解决,下班后,重启服务器,在BIOS打开就好了,再装docker,没问题~ git clone 代码?没问题~ docker load我的镜像?没问题~ docker run -it –name blabla -v /your/local/path/:/map/path/in/docker/ reponame:tag 创建容器?这里就有问题了
首先/your/local/path/是我的代码在windows物理机的路径,我想映射到docker内的/map/path/in/docker/ 目录,结果拿到blabla容器的终端后cd到/map/path/in/docker/ 目录下一看啥都没有!
分析问题:问题好像出在了在windows里面docker生成原理上,docker toolbox它是先用oracle的Virtual Box虚拟出一个linux环境,然后再在这个虚拟的linux环境中跑docker daemon,那么docker和windows物理机中间就隔了一层VirtualBox虚拟环境,所以我应该在VirtualBox里面先映射windows物理机的代码路径 /your/local/path/进去虚拟机形成一个/virtualboxpath/,然后再docker run -v挂载数据卷的时候去挂载VitualBox虚拟机中的/vitualboxpath/? ……..有点复杂解决办法:
简单来说就是:
0.先假设你在windows中docker toolbox已经安装成功了
1. VirtualBox中设置共享文件夹,把你在windows服务器中的代码路径写进去,这里假设是 /your/local/path/,然后共享文件夹起名为localpath
2. 进入Linux虚拟机
mkdir -p /virtualboxpath/
mount -t vboxsf -o uid=1000,git=50 localpath /virtualboxpath/
3. docker run -it –name blabla -v /virtualboxpath/: /map/path/in/docker/ reponame:tag
来源是这篇博客的5.2更新感悟:还是linux里面才能享受docker丝滑般的体验啊啊啊!
17.2.23更新:
docker中文支持问题
原生的ubuntu镜像,用locale发现都是POSIX,要在Dockerfile写上ENV LANG C.UTF-8才可以,不推荐暂时修改的办法(比如在容器内用export LANG=C.UTF-8),这种办法在你exit出容器就失效了
17.9.23更新:
最近调优的时候学到的:原来并不是什么都适合用docker打包! 数据库(mysql,postgresql,redis,mongodb等)最好不要也放到docker容器里面,因为第一,会让查询隔多了一层docker的容器,查询速度变慢(从docker容器里面拿出数据库,查询至少可以快一倍);第二,数据也不是经常需要重新启动的存在,不像web应用那样有点新功能就要重新部署
Ref:WHY DATABASES ARE NOT FOR CONTAINERS
后记
最近也是在看持续集成(CI)和持续交付还有持续部署的东西(以下简称’三持续’),还有DevOps,其实上面无论是docker还是git这些效率工作的工具,都是’三持续’的概念范围.
时代变化很快,人们越来越避免重复机械工作,或者说重复机械的工作全部交回给机械去做,’三持续’ 就是个中典型的代表之一,本来代码写好了,需要部署(代码依赖解决),测试,测试通过后就是发布,出现bug就通知开发去修复,这些都是重重复复的工作,可是持续集成就可以让这个过程自动化,现在最经典的组合就是jenkins+docker+git+maven+shell完成持续交付和集成,jenkins算是大脑,负责调度任务,docker负责把解决运行环境问题,git负责从代码仓库拉取代码,maven解决java的jar包依赖,shell负责测试和系统巡查等,当然你还可以在这个基础上自己按需求叠加/删减和打包,比如我现在就是只是用到docker+git+pip(因为是python程序,所以用pip),由于项目性质,还用不到jenkins,所以没有部署,后期需要部署也是很快的.
至于DevOps,有人说是一种文化,也有人说是一个职位,需要有相应的技能,我觉得DevOps是开发和运维从分家以后重新紧密联合的象征,其实讲真,所谓程序员不过是用计算机,用1/0去解决问题的一群人,不要把自己分的太清楚,说自己是开发,自己是前端或者后端,自己是搞数据开发什么的,能解决问题才是我们这个职业的终极目的,也是工程的意义,去应用计算机科学去解决现实的问题,如果没有后端,前端也得去写后端逻辑,如果没有运维,开发得学会自己去部署,分工只是为了工作高效,可是分工的前提是大家都清楚并且高效地交付,如果没有这一点,又何必对身份对语言太较真,解决问题才是王道,而狭义上来讨论DevOps,一个就是Dev向Ops靠拢做了一些部署的工作,不仅仅提交了代码,把环境也提交了(docker),解决了“我本地可以,提交部署就不行,或者其他地方就不行”的问题;另外一个就是Ops向Dev靠拢,因为我本来不是Ops,所以我也不太清楚怎么个靠拢法,这里就不举例了,如果朋友有相关经验的,欢迎下方留言