TensorFlow使用深度学习破解字符验证码
本篇环境Ubuntu 16.04.3 LTS,Python 3.5.2,TensorFlow1.4.1
1、验证码制作
首先,为了得到“验证码图片”以及对应的“正确结果”,即训练集。在这里使用php生成而非人力打码。
Ubuntu上安装php
apt-get install libapache2-mod-php
sudo apt-get install php
sudo apt-get install apache2
php生成验证码(PS:借用了网络管理课程的验证码生成代码)
TestCodeLen为2,即验证码长度为2
$TestCodeChars="1234567890";
$TestCodeLen=2;
$TestCode="";
$Num=1000000;
for($n=0;$n<$Num;$n++){
$date = explode(' ', microtime());
$seed = $date[0];
srand($seed*1000);
//根据验证码字符集随机生成验证码字符串
for($i=0;$i<$TestCodeLen;$i++){
$TestCode .=$TestCodeChars[rand(0,strlen($TestCodeChars)-1)];
}
print($TestCode."\n");
//定义验证码输出图像的参数
$font="C:\Windows\Fonts\TIMESBD.ttf";
$FontSize=14;
$angle=10;
$AddSize=6;
$x_size=$TestCodeLen*$FontSize+$AddSize;
$y_size=$FontSize+$AddSize;
$im=@imagecreatetruecolor($x_size,$y_size);
$white=imagecolorallocate($im,255,255,255);
$red=imagecolorallocate($im,255,0,0);
//绘制验证码图像
imagefilledrectangle($im,0,0,$x_size-1,$y_size-1,$white);
for($i=0;$i<$TestCodeLen;$i++){
imagettftext($im,$FontSize,$angle,$FontSize*$i+$AddSize,$FontSize+$AddSize/2,$red,$font,$TestCode[$i]);
}
for($j=0;$j<50;$j++){
imagesetpixel($im,rand(0,$x_size),rand(0,$y_size),$red);
}
imagepng($im,"testdata/".$TestCode."-".$n.".jpg");
$TestCode = "";
}
?>2、TensorFlow卷积神经网络构建
因为是第一次搞这个,所以random_mini_batches()以及整体函数用了以前coursera上的作业。
先是读入文件,然后转为灰度,再经过2层卷积层和最后的全连接层获得输出。
采用端到端的理念,输入直接是验证码图片(不经过分割),为了简便,输入是20*34=680个像素点,对应680个神经元,输出就是“0-9十个数字”乘以验证码长度2,共计20个神经元。
epoch是指把数据集轮了多少次,如果当前次训练集的acc>0.5,则把当前权重对应的网络保存下来。
PS:事实上,就轮了100次,训练集和测试集的正确率就到70%以上了,甚至有时候达到90%
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import math#尝试读取其中一副图片,查看图片像素大小及其他相关信息
img=np.array(Image.open('/home/lygwangyp/TensorflowCaptcha/traindata/28-1708.jpg'))#打开图像并转化为数字矩阵
plt.imshow(img)
plt.show()
print(img.shape)
print(img.dtype)
print(img.size)
print(type(img))(20, 34, 3)
uint8
2040
#将图片转为灰度图
def convert2gray(img):
gray = np.empty((img.shape[0],img.shape[1],1),dtype='float32')
gray[:,:,0] = np.mean(img, -1)
return graygreyimg = convert2gray(img)
plt.imshow(greyimg[:,:,0],cmap = 'gray')
img.shape(20, 34, 3)
greyimg.shape(20, 34, 1)
def load_data(filepath):
#os.listdir(filename)返回filename中所有文件的文件名列表
imgs = os.listdir(filepath)
#获得图片数量
num = len(imgs)
#Return a new array of given shape and type, without initializing entries.
data = np.empty((num,20,34,1),dtype='float32')
label = np.empty((num,1),dtype='float32')
for i in range(num):
#PIL 的 open() 函数用于创建 PIL 图像对象
img = np.array(Image.open(filepath+imgs[i]))
greyimg = convert2gray(img)
data[i,:,:] = greyimg
label[i] = int(imgs[i].split('-')[0])
#把即将feed进tensor Y的数据由"21","26"这样的数字形式,转化成所需要的[0 1 0 0][0 0 0 1]向量形式 labels原始 -> label输入
label = label.tolist()
labellist = []
for y in label:
labellist.append(text2vec(str(int(y[0]))))
label = np.array(labellist)
return data,labeldef initialize_parameters():
with tf.variable_scope(""):
W1 = tf.get_variable("W1", [4, 4, 1, 8], initializer = tf.contrib.layers.xavier_initializer(seed = 0))
W2 = tf.get_variable("W2", [2, 2, 8, 16], initializer = tf.contrib.layers.xavier_initializer(seed = 0))
parameters = {"W1": W1,
"W2": W2}
return parameters#将字符串转化为[0,1,0,1...]的向量
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('验证码最长4个字符')
vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
def char2pos(c):
if c =='_':
k = 62
return k
k = ord(c)-48
if k > 9:
k = ord(c) - 55
if k > 35:
k = ord(c) - 61
if k > 61:
raise ValueError('No Map')
return k
for i, c in enumerate(text):
idx = i * CHAR_SET_LEN + char2pos(c)
vector[idx] = 1
return vector# 向量转回文本
def vec2text(vec):
char_pos = vec.nonzero()[0]
text=[]
for i, c in enumerate(char_pos):
char_at_pos = i #c/63
char_idx = c % CHAR_SET_LEN
if char_idx < 10:
char_code = char_idx + ord('0')
elif char_idx <36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx- 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
return "".join(text)def forward_propagation(X, parameters):
W1 = parameters['W1']
W2 = parameters['W2']
### START CODE HERE ###
# CONV2D: stride of 1, padding 'SAME'
Z1 = tf.nn.conv2d(X,W1, strides = [1,1,1,1], padding = 'SAME')
# RELU
A1 = tf.nn.relu(Z1)
# MAXPOOL: window 8x8, sride 8, padding 'SAME'
P1 = tf.nn.max_pool(A1, ksize = [1,8,8,1], strides = [1,8,8,1], padding = 'SAME')
# CONV2D: filters W2, stride 1, padding 'SAME'
Z2 = tf.nn.conv2d(P1,W2, strides = [1,1,1,1], padding = 'SAME')
# RELU
A2 = tf.nn.relu(Z2)
# MAXPOOL: window 4x4, stride 4, padding 'SAME'
P2 = tf.nn.max_pool(A2, ksize = [1,4,4,1], strides = [1,4,4,1], padding = 'SAME')
# FLATTEN
P2 = tf.contrib.layers.flatten(P2)
# FULLY-CONNECTED without non-linear activation function (not not call softmax).
# 6 neurons in output layer. Hint: one of the arguments should be "activation_fn=None"
Z3 = tf.contrib.layers.fully_connected(P2, num_outputs = MAX_CAPTCHA*CHAR_SET_LEN, activation_fn=None)
return Z3def compute_cost(Z3, Y):
cost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits = Z3, labels = Y))
return costdef random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples) (m, Hi, Wi, Ci)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat), of shape (1, number of examples) (m, n_y)
mini_batch_size - size of the mini-batches, integer
seed -- this is only for the purpose of grading, so that you're "random minibatches are the same as ours.
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
m = X.shape[0] # number of training examples
mini_batches = []
np.random.seed(seed)
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[permutation,:,:,:]
shuffled_Y = Y[permutation,:]
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:,:,:]
mini_batch_Y = shuffled_Y[k * mini_batch_size : k * mini_batch_size + mini_batch_size,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
mini_batch_X = shuffled_X[num_complete_minibatches * mini_batch_size : m,:,:,:]
mini_batch_Y = shuffled_Y[num_complete_minibatches * mini_batch_size : m,:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batchesIMAGE_HEIGHT = 20
IMAGE_WIDTH = 34
MAX_CAPTCHA = 2 #验证码文本最长字符数
CHAR_SET_LEN = 10 #验证码字符集字符数1-10
learning_rate = 0.001X_train,Y_train = load_data("/home/lygwangyp/TensorflowCaptcha/traindata/")
X_test,Y_test = load_data("/home/lygwangyp/TensorflowCaptcha/testdata/")def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.009,
num_epochs = 100, minibatch_size = 64, print_cost = True):
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA*CHAR_SET_LEN])
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
cost = compute_cost(Z3, Y)
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
predict = tf.reshape(Z3, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
max_idx_p = tf.argmax(predict, 2)
max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2)
correct_pred = tf.equal(max_idx_p, max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# Initialize all the variables globally
init = tf.global_variables_initializer()
seed = 233
tf.set_random_seed(2333)
costs = [] # To keep track of the cost
m = X_train.shape[0]
saver = tf.train.Saver()
# Start the session to compute the tensorflow graph
with tf.Session() as sess:
# Run the initialization
sess.run(init)
# Do the training loop
for epoch in range(num_epochs):
minibatch_cost = 0.
num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set
seed = seed + 1
minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)
for minibatch in minibatches:
# Select a minibatch
(minibatch_X, minibatch_Y) = minibatch
# IMPORTANT: The line that runs the graph on a minibatch.
# Run the session to execute the optimizer and the cost, the feedict should contain a minibatch for (X,Y).
_ , temp_cost ,acc = sess.run([optimizer, cost, accuracy], feed_dict={X: minibatch_X, Y: minibatch_Y})
minibatch_cost += temp_cost / num_minibatches
# Print the cost every epoch
if print_cost == True and epoch % 5 == 0:
print ("Cost after epoch %i: %f\nThis epoch Accuracy is %f" % (epoch, minibatch_cost, acc))
if acc>0.5:
saver.save(sess, "/home/lygwangyp/TensorflowCaptcha/pengpengNet/Saved_model/pengNetCaptcha.model", global_step=epoch)
if print_cost == True and epoch % 1 == 0:
costs.append(minibatch_cost)
# plot the cost
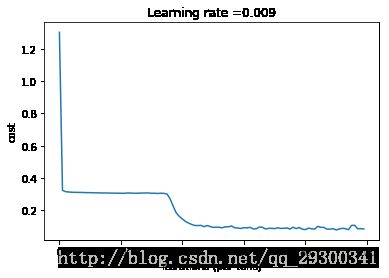
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (per tens)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
train_accuracy = accuracy.eval({X: X_train, Y: Y_train})
print("All Train Accuracy:", train_accuracy)
test_accuracy = accuracy.eval({X: X_test, Y: Y_test})
print("All Test Accuracy:", test_accuracy)
return parametersparameters = model(X_train, Y_train, X_test, Y_test, num_epochs = 100)Cost after epoch 0: 1.301943
This epoch Accuracy is 0.113636
Cost after epoch 5: 0.311392
This epoch Accuracy is 0.113636
Cost after epoch 10: 0.309575
This epoch Accuracy is 0.113636
Cost after epoch 15: 0.307371
This epoch Accuracy is 0.181818
Cost after epoch 20: 0.305834
This epoch Accuracy is 0.068182
Cost after epoch 25: 0.305516
This epoch Accuracy is 0.136364
Cost after epoch 30: 0.305877
This epoch Accuracy is 0.181818
Cost after epoch 35: 0.300717
This epoch Accuracy is 0.318182
Cost after epoch 40: 0.146618
This epoch Accuracy is 0.659091
Cost after epoch 45: 0.105703
This epoch Accuracy is 0.750000
Cost after epoch 50: 0.094605
This epoch Accuracy is 0.931818
Cost after epoch 55: 0.098196
This epoch Accuracy is 0.840909
Cost after epoch 60: 0.093290
This epoch Accuracy is 0.840909
Cost after epoch 65: 0.096823
This epoch Accuracy is 0.750000
Cost after epoch 70: 0.086718
This epoch Accuracy is 0.863636
Cost after epoch 75: 0.083978
This epoch Accuracy is 0.818182
Cost after epoch 80: 0.080751
This epoch Accuracy is 0.931818
Cost after epoch 85: 0.094561
This epoch Accuracy is 0.818182
Cost after epoch 90: 0.078955
This epoch Accuracy is 0.909091
Cost after epoch 95: 0.106287
This epoch Accuracy is 0.772727
All Train Accuracy: 0.770552
All Test Accuracy: 0.770072
3、TensorFlow神经网络测试
随手选了一张图片,加载之前保存的权值,进行测试,测了几张都能准确识别出来。
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import math
from tools import *IMAGE_HEIGHT = 20
IMAGE_WIDTH = 34
MAX_CAPTCHA = 2 #验证码文本最长字符数
CHAR_SET_LEN = 10 #验证码字符集字符数1-10
learning_rate = 0.001def testImg(greyimg):
with tf.Graph().as_default() as g:
# [Variable and model creation goes here.]
X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT, IMAGE_WIDTH, 1])
parameters = initialize_parameters()
Z3 = forward_propagation(X, parameters)
predict = tf.reshape(Z3, [-1, MAX_CAPTCHA, CHAR_SET_LEN])
max_idx_p = tf.argmax(predict, 2)
saver = tf.train.Saver() # Gets all variables in `graph`.
with tf.Session(graph=g) as sess:
saver.restore(sess,tf.train.latest_checkpoint('/home/lygwangyp/TensorflowCaptcha/pengpengNet/Saved_model'))
# Do some work with the model....
text_list = sess.run(max_idx_p, feed_dict={X: [greyimg]})
text = text_list[0].tolist()
vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
i = 0
for n in text:
vector[i*CHAR_SET_LEN + n] = 1
i += 1
print(vec2text(vector))
return vec2text(vector)#选一张测试集里面的图片进行测试
#尝试读取其中一副图片,查看图片像素大小及其他相关信息
img=np.array(Image.open('/home/lygwangyp/TensorflowCaptcha/testdata/53-6547.jpg'))#打开图像并转化为数字矩阵
greyimg = convert2gray(img)
captcha_image = np.array([greyimg.tolist()],dtype = np.float32)predictText = testImg(greyimg)
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1, 0.9,predictText, ha='center', va='center', transform=ax.transAxes)
plt.imshow(img)INFO:tensorflow:Restoring parameters from /home/lygwangyp/TensorflowCaptcha/pengpengNet/Saved_model/pengNetCaptcha.model-95
53

tools.py文件
import os
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import math
IMAGE_HEIGHT = 20
IMAGE_WIDTH = 34
MAX_CAPTCHA = 2 #验证码文本最长字符数
CHAR_SET_LEN = 10 #验证码字符集字符数1-10
learning_rate = 0.001
def initialize_parameters():
with tf.variable_scope(""):
W1 = tf.get_variable("W1", [4, 4, 1, 8], initializer = tf.contrib.layers.xavier_initializer(seed = 0))
W2 = tf.get_variable("W2", [2, 2, 8, 16], initializer = tf.contrib.layers.xavier_initializer(seed = 0))
parameters = {"W1": W1,
"W2": W2}
return parameters
def forward_propagation(X, parameters):
W1 = parameters['W1']
W2 = parameters['W2']
### START CODE HERE ###
# CONV2D: stride of 1, padding 'SAME'
Z1 = tf.nn.conv2d(X,W1, strides = [1,1,1,1], padding = 'SAME')
# RELU
A1 = tf.nn.relu(Z1)
# MAXPOOL: window 8x8, sride 8, padding 'SAME'
P1 = tf.nn.max_pool(A1, ksize = [1,8,8,1], strides = [1,8,8,1], padding = 'SAME')
# CONV2D: filters W2, stride 1, padding 'SAME'
Z2 = tf.nn.conv2d(P1,W2, strides = [1,1,1,1], padding = 'SAME')
# RELU
A2 = tf.nn.relu(Z2)
# MAXPOOL: window 4x4, stride 4, padding 'SAME'
P2 = tf.nn.max_pool(A2, ksize = [1,4,4,1], strides = [1,4,4,1], padding = 'SAME')
# FLATTEN
P2 = tf.contrib.layers.flatten(P2)
# FULLY-CONNECTED without non-linear activation function (not not call softmax).
# 6 neurons in output layer. Hint: one of the arguments should be "activation_fn=None"
Z3 = tf.contrib.layers.fully_connected(P2, num_outputs = MAX_CAPTCHA*CHAR_SET_LEN, activation_fn=None)
return Z3
#将图片转为灰度图
def convert2gray(img):
gray = np.empty((img.shape[0],img.shape[1],1),dtype='float32')
gray[:,:,0] = np.mean(img, -1)
return gray
# 向量转回文本
def vec2text(vec):
char_pos = vec.nonzero()[0]
text=[]
for i, c in enumerate(char_pos):
char_at_pos = i #c/63
char_idx = c % CHAR_SET_LEN
if char_idx < 10:
char_code = char_idx + ord('0')
elif char_idx <36:
char_code = char_idx - 10 + ord('A')
elif char_idx < 62:
char_code = char_idx- 36 + ord('a')
elif char_idx == 62:
char_code = ord('_')
else:
raise ValueError('error')
text.append(chr(char_code))
return "".join(text)