一张图了解MapReduce全流程
先上图
目录
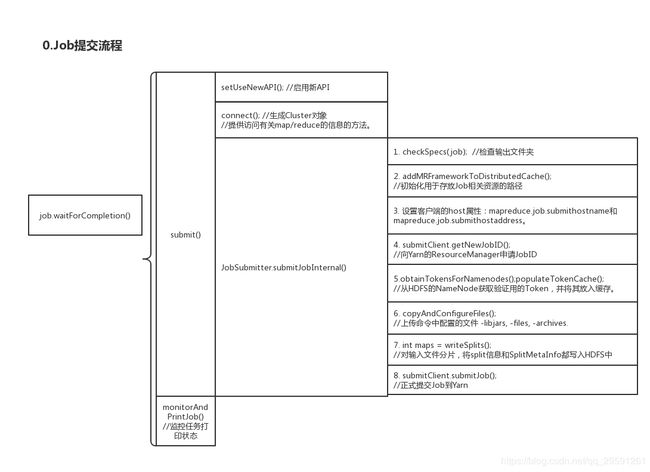
〇、Job提交流程
0.WordCount源码:
1.waitForCompletion
2.submit
3.submitJobInternal
一、getSplits:输入文件分片
二、RecordReader:读取文件
三、Map
〇、Job提交流程
0.WordCount源码:
public class WordCount {
public static class TokenizerMapper extends Mapper {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] ");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 1.waitForCompletion
我们在自己写的MR程序中通过org.apache.hadoop.mapreduce.Job来创建Job,配置好之后通过waitForCompletion方法来提交Job并打印MR执行过程的log。waitForCompletion源码及注释如下:
public boolean waitForCompletion(boolean verbose) throws IOException, InterruptedException,ClassNotFoundException {
if (state == JobState.DEFINE) {
submit(); //判断状态state为DEFINE状态,则可以提交Job后,执行submit()方法。
}
if (verbose) { //verbose表示是否打印Job运行信息
monitorAndPrintJob(); //不断的刷新获取job运行的进度信息,并打印。
} else {
// 从配置里取得轮训的间隔时间,来分析当前job是否执行完毕
int completionPollIntervalMillis =
Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful();
}2.submit
其中调用的函数submit()源码及注释如下:
public void submit()
throws IOException, InterruptedException, ClassNotFoundException {
ensureState(JobState.DEFINE); // 确保当前的Job的状态是处于DEFINE,否则不能提交Job。
setUseNewAPI(); // 启用新的API,即org.apache.hadoop.mapreduce下的Mapper和Reducer
connect(); // Connect方法会产生一个JobClient实例,用来和JobTracker通信。
final JobSubmitter submitter = // 构造提交器
getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
return submitter.submitJobInternal(Job.this, cluster); // 提交
}
});
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
} 3.submitJobInternal
提交函数 submitJobInternal() 源码太长,就不贴了,它主要干了以下事情:
1.checkSpecs:检查输出目录,如果已存在则报错
2.getStagingDir:初始化Job执行过程中会用到的文件的存放路径
3.getHostAddress/Name:获取和设置提交job机器的地址和主机名
4.getNewJobID:获取JobID
5.从HDFS的NameNode获取验证用的Token,并将其放入缓存。携带这个Token就可以去NameNode查询task运行情况
6. copyAndConfigureFiles:上传命令中配置的文件,比如我们打的WordCount.jar
7.writeSplits:对输入文件分片,将分片信息写入HDFS中
8.submitJob:正式提交Job到Yarn至此,Job已经正式提交到Yarn去运行了。
参考博客:mapreduce job提交流程源码级分析: https://www.cnblogs.com/lxf20061900/p/3643581.html
一、getSplits:输入文件分片
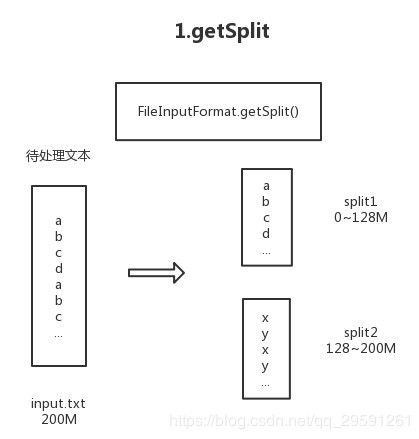
假设我们有一个大小为200M的文件,里面每行是一个单词。在上面的Job提交流程中,有一步就是对输入文件进行分片。
默认情况下我们调用的是TextInputFormat类来对文件进行分片,分片函数getSplits继承自它的抽象父类FileInputFormat,以下是FileInputFormat.getSplits()函数的流程图。
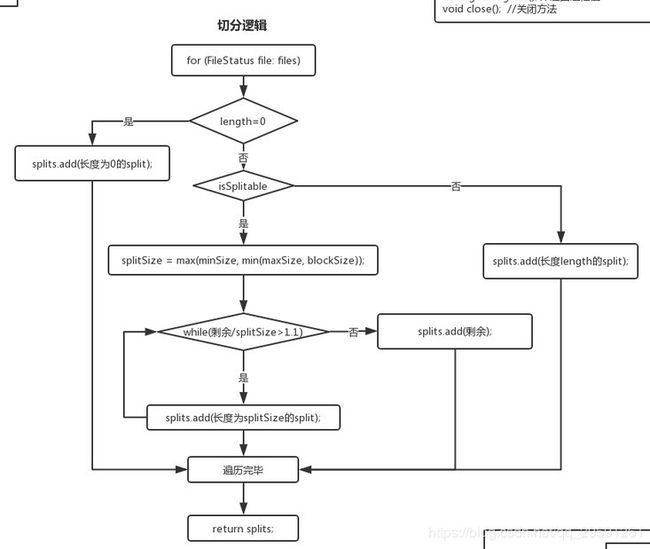
(1)遍历输入文件
(2)如果文件大小=0,则新增一个长度为0的split;否则到第3步
(3)判断文件是否可切分(默认返回True),如果不可切分,则新增一个和文件相同大小的split(即把这个文件全部放到一个split中),否则到第4步
(4)计算一个切片的大小,是minSize,maxSize,blockSize这三个数中的不大不小的那个
(5)如果文件剩余带下/splitSize>1.1,则切分出长度为splitSize的大小的一个切片;否则把剩下的全部都作为一个切片(这样做是为了防止只剩129M的时候被切成了128M+1M,防止了过多小文件的产生)
(6)重复1-5直到文件遍历结束,返回所有切分信息。
minSize 可通过 mapreduce.input.fileinputformat.split.minsize 来设置
maxSize 可通过mapreduce.input.fileinputformat.split.maxsize 来设置
blockSize在Hadoop2中默认128M,Hadoop1中默认64M
FileSplit主要属性如下图:

从上图可以看出一个split只是记录了一个文件的位置、开始、结束等信息,只是逻辑上的一个分片,并不是真正的切出来这样的一个文件放在磁盘上。
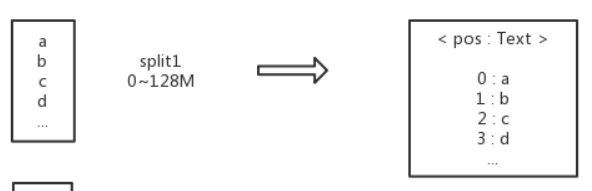
所以经过上面切分之后,我们得到了两个split,第一个是0~128M,第二个是128~200M。
二、RecordReader:读取文件
InputFormat除了对输入文件进行切片,还有一个重要的作用就是读取输入文件,转化为key-value形式的数据传递给Map来处理。InputFormat.createRecordReader()会返回一个RecordReader实例,然后调用RecordReader中的方法对文件进行读取。以LineRecordReader为例,主要变量和函数如下:

其中start、end记录了当前split的开始和结束,pos记录了当前读取的位置。nextKeyValue会判断是否还有下一个k-v,如果有将会获取下一个k-v,然后调用getCurrentKey()获取当前key,getCurrentValue获取当前value。LineRecordReader输出的key是偏移量,value是每一行的内容。所以输入文件的转化过程如下:
三、Map
Mapper的驱动函数如下:
run(Context context) throws IOException, InterruptedException {
setup(context);
try {
while (context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context);
}
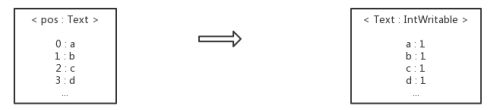
}可以看出,context是RecordReader的一层封装,调用的都是RecordReader中的函数。获取到k-v之后就传递给我们自己写的map函数,输出新的k-v。这一步的转化过程如下:
四、环形缓冲区
Mapper的输出去向如何呢?我们在map()中通过Context.write(k,v)来输出计算好的k-v,通过outputCollector收集之后写到写到环形缓冲区中。
环形内缓冲区就是内存中一块连续的地址,我们从它的一端写数据,也就是Mapper输出的k-v,另一端写这些数据的索引,包括第index个k-v、属于第partition个分区、key的起始位置keystart、value的起始位置valuestart。数据和索引是根据equator区分的,这个equator在发生溢写之后是可以变化的。
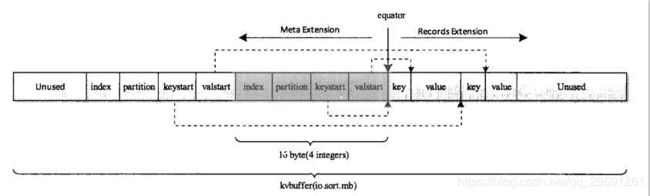
这个环形缓冲区的默认大小是100M,当这个环形数组的数据存储量达到80%的时候就开始执行splill溢写操作,它会锁定这80%的内存数据,并把这些数据给它写到本地磁盘上。在溢写的时候,剩下的20%依然可以接受来自Mapper的数据。
上面所说的partition表示这个k-v属于第几个分区,是通过Partitioner.getPartition()确定的,默认是按照key的哈希值&int最大值,然后对reduce个数取模。当达到80%开始溢写的时候,有几个分区就会产生几个分区文件。在写入文件之前,还会对同一个分区中的数据按照key进行快速排序,然后把排好序的文件写到文件中。
假如我们有两个reduce,第一个80%会产生两个分区文件,分区1和分区2。当第二次达到80%的时候会再产生两个分区文件,分区3和分区4。如果此时map执行结束了,同一个map产生的这四个分区文件还会按照相同的partition进行合并,合并的时候会进行归并排序以保证合并后的文件也是有序的。上面这些操作图示如下:
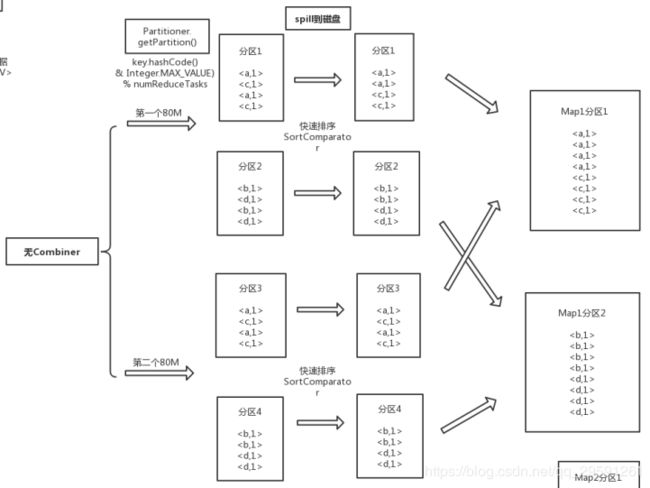
这是在我们没有配置Combiner的情况下的执行方式。如果我们配置了Combiner,则会在spill到磁盘的时候对相同key的数据进行合并,四个分区文件进行合并的时候对相同的key也会执行合并操作。所以有combiner的时候执行过程如下:
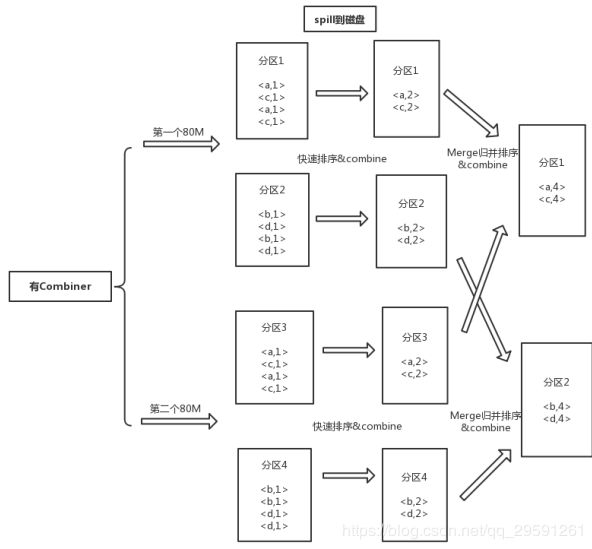
接下来详细看一下Combiner。Combiner继承于Reducer,是对同一key的value列表进行处理。Combiner是对同一key的部分value进行操作,而Reducer是对同一key的所有value进行操作。所以我们只能在部分操作不影响总体操作的时候才能使用Combiner,比如最大值、最小值等。不能用的情况有平均值、中位数等。
Combiner的好处有:它会先对对map输出的结果进行一次合并,减少了map和reduce节点中的数据传输量。同时map阶段已经对部分数据进行了合并,减少了reduce要处理的数据量。
未完待续。。。