pymongo 利用gridfs构建大文件存储系统
一、gridfs介绍
GridFS 用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等),适合于不常改变但是经常需要连续访问的大文件。
GridFS 也是文件存储的一种方式,但是它是存储在MonoDB的集合中。
GridFS 可以更好的存储大于16M的文件。
GridFS 会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中。
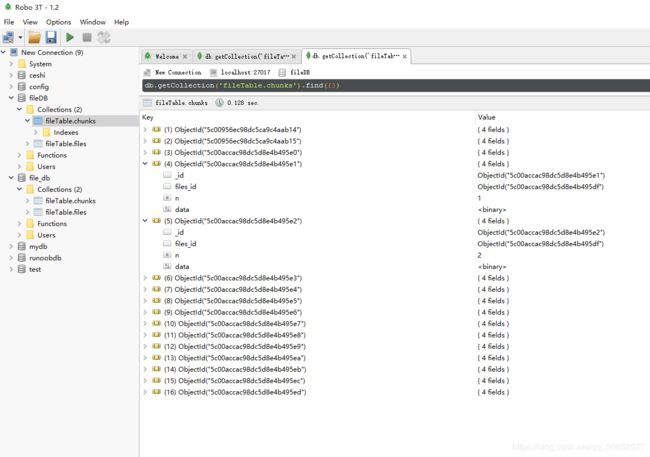
GridFS 用两个集合来存储一个文件:fs.files与fs.chunks。每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。如下,两个图分别是files和chunks的信息。其中,files中存储文件的元信息,默认使用集合为fs.files,除自定义键外,还需包含:
-
_id 主键
-
length 文件所包含的字节数
-
chunkSize 组成文件的每个块的大小,单位为字节,默认值为256KB,可调整
-
uploadDate 文件被上传到GridFS的日期
-
md5 文件内容的MD5校验值,该值由服务器端测试得到
其中,每一个文件存储的各个chunk的files_id相同,如图chunk4和5中files_id相同。

二、文件系统
import pymongo
from pymongo import MongoClient
from gridfs import GridFS
class GFS(object):
def __init__(self, file_db,file_table):
self.file_db = file_db
self.file_table = file_table
def createDB(self): #连接数据库,并创建文件数据库与数据表
client = MongoClient('localhost',27017)
db = client[self.file_db]
file_table = db[self.file_table]
return (db,file_table)
def insertFile(self,db,filePath,query): #将文件存入数据表
fs = GridFS(db,self.file_table)
if fs.exists(query):
print('已经存在该文件')
else:
with open(filePath,'rb') as fileObj:
data = fileObj.read()
ObjectId = fs.put(data,filename = filePath.split('/')[-1])
print(ObjectId)
fileObj.close()
return ObjectId
def getID(self,db,query): #通过文件属性获取文件ID,ID为文件删除、文件读取做准备
fs=GridFS(db, self.file_table)
ObjectId=fs.find_one(query)._id
return ObjectId
def getFile(self,db,id): #获取文件属性,并读出二进制数据至内存
fs = GridFS(db, self.file_table)
gf=fs.get(id)
bdata=gf.read() #二进制数据
attri={} #文件属性信息
attri['chunk_size']=gf.chunk_size
attri['length']=gf.length
attri["upload_date"] = gf.upload_date
attri["filename"] = gf.filename
attri['md5']=gf.md5
print(attri)
return (bdata, attri)
# def listFile(self,db): #列出所有文件名
# fs = GridFS(db, self.file_table)
# gf = fs.list()
# def findFile(self,db,file_table): #列出所有文件二进制数据
# fs = GridFS(db, table)
# for file in fs.find():
# bdata=file.read()
def write_2_disk(self,bdata, attri): #将二进制数据存入磁盘
name = "get_"+attri['filename']
if name:
output = open(name, 'wb')
output.write(bdata)
output.close()
print("fetch image ok!")
def remove(self,db,id): #文件数据库中数据的删除
fs = GridFS(db, self.file_table)
fs.delete(id) #只能是id
if __name__=='__main__':
gfs=GFS('fileDB','fileTable')
(file_db,fileTable) = gfs.createDB() #创建数据库与数据表
filePath = 'C:/Users/Administrator/Desktop/02655.jpeg' #插入的文件
query = {'filename': '02655.jpeg'}
id=gfs.insertFile(file_db,filePath,query) #插入文件
id=gfs.getID(file_db,query)
(bdata,attri)=gfs.getFile(file_db,id) #查询并获取文件信息至内存
gfs.write_2_disk(bdata,attri) #写入磁盘
# gfs.remove(file_db,id) #删除数据库中文件经测试数据库创建、插入、读取、写入磁盘和删除都能正常工作。
三、总结
对于文件存入与读写至磁盘的操作较多,而对于如何删除总结较少,fs的delete参数只能是文件id,因此文件id的获取则成为删除操作的关键,本文通过getID函数获取。