带你玩转kubernetes-k8s(第21篇:k8s-深入掌握Pod-初始化容器、Pod滚动升级)
上节内容的错误,还请大家不要太在意,后面我们会解决的,理解Job的作用,概念就可以了。下面我们进入正题。
Init Container(初始化容器)
在很多应用场景中,应用在启动之前都需要进行如下初始化操作。
◎ 等待其他关联组件正确运行(例如数据库或某个后台服务)。
◎ 基于环境变量或配置模板生成配置文件。
◎ 从远程数据库获取本地所需配置,或者将自身注册到某个中央数据库中。
◎ 下载相关依赖包,或者对系统进行一些预配置操作。
Kubernetes 1.3引入了一个Alpha版本的新特性init container(初始化容器,在Kubernetes 1.5时被更新为Beta版本),用于在启动应用容器(app container)之前启动一个或多个初始化容器,完成应用容器所需的预置条件。init container与应用容器在本质上是一样的,但它们是仅运行一次就结束的任务,并且必须在成功执行完成后,系统才能继续执行下一个容器。根据Pod的重启策略(RestartPolicy),当init container执行失败,而且设置了RestartPolicy=Never时,Pod将会启动失败;而设置RestartPolicy=Always时,Pod将会被系统自动重启。
下面以Nginx应用为例,
apiVersion: v1
kind: Pod
metadata:
name: nginx
annotations:
spec:
initContainers:
- name: install
image: busybox
command:
- wget
- "-O"
- "/work-dir/index.html"
- "http://kubernetes.io"
volumeMounts:
- name: workdir
mountPath: "/work-dir"
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: workdir
mountPath: /usr/share/nginx/html
dnsPolicy: Default
volumes:
- name: workdir
emptyDir: {} 创建这个Pod
kubectl create -f nginx-ini-containers.yaml
在运行init container的过程中查看Pod的状态,可见init过程还未完成:
kubectl get pods
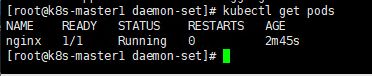
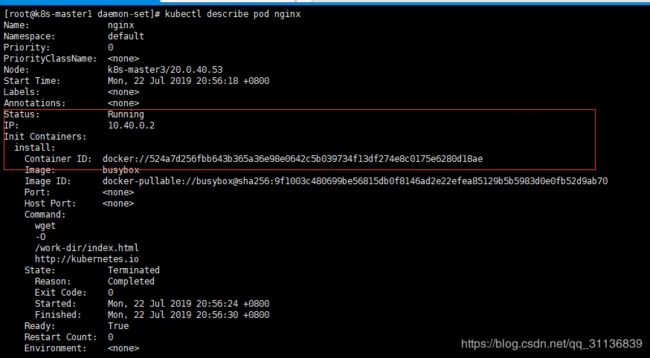

查看Pod的事件,可以看到系统首先创建并运行init container容器(名为install),成功继续创建和运行Nginx容器:
启动成功后,登录进Nginx容器,可以看到/usr/share/nginx/html目录下的index.html文件为init container生成。

init container与应用容器的区别如下:
(1)init container的运行方式与应用容器不同,它们必须先于应用容器执行完成,当设置了多个init container时,将按顺序逐个运行,并且只有前一个init container运行成功后才能运行后一个init container。当所有init container都成功运行后,Kubernetes才会初始化Pod的各种信息,并开始创建和运行应用容器。
(2)在init container的定义中也可以设置资源限制、Volume的使用和安全策略,等等。但资源限制的设置与应用容器略有不同。
◎ 如果多个init container都定义了资源请求/资源限制,则取最大的值作为所有init container的资源请求值/资源限制值。
◎ Pod的有效(effective)资源请求值/资源限制值取以下二者中的较大值。
a)所有应用容器的资源请求值/资源限制值之和。
b)init container的有效资源请求值/资源限制值。
◎ 调度算法将基于Pod的有效资源请求值/资源限制值进行计算,也就是说init container可以为初始化操作预留系统资源,即使后续应用容器无须使用这些资源。
◎ Pod的有效QoS等级适用于init container和应用容器。
◎ 资源配额和限制将根据Pod的有效资源请求值/资源限制值计算生效。
◎ Pod级别的cgroup将基于Pod的有效资源请求/限制,与调度机制一致。
(3)init container不能设置readinessProbe探针,因为必须在它们成功运行后才能继续运行在Pod中定义的普通容器。
在Pod重新启动时,init container将会重新运行,常见的Pod重启场景如下:
◎ init container的镜像被更新时,init container将会重新运行,导致Pod重启。仅更新应用容器的镜像只会使得应用容器被重启。
◎ Pod的infrastructure容器更新是,Pod将会重启。
◎ 若Pod中的所有应用容器都终止了,并且RestartPolicy=Always,则Pod会重启。
Pod 的升级和回滚问题。
当集群中的某个服务需要升级时,我们需要停止目前与该服务相关的所有Pod,然后下载新版本镜像并创建新的Pod。如果集群规模比较大,则这个工作变成了一个挑战,并且先全部停止然后逐步升级的方式会导服务在较长时间是不可用的。k8s提供了滚动升级来解决这个问题。
如果Pod是通过Deployment创建的,则用户可以在运行时修改Deployment的Pod定义(spec.template)或镜像名称,并应用到Deployment对象上,系统既可完成Deployment的自动更新操作。如果在更新过程中发生了错误,则可以通过回滚操作恢复Pod的版本。
Deployment的升级
以Deployment nginx为例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
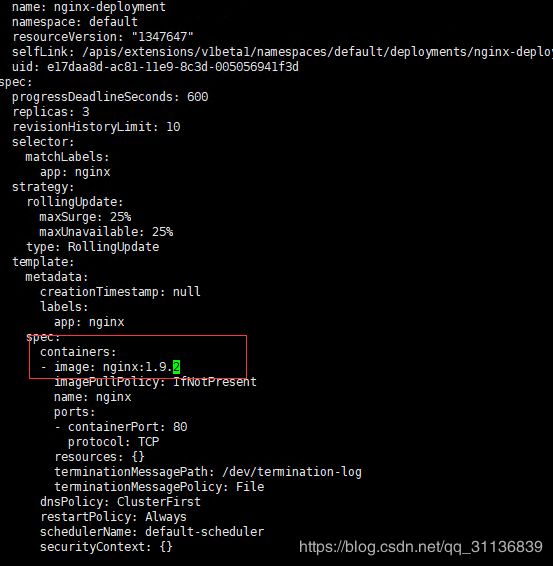
现在Pod镜像需要被更新为Nginx:1.9.1,我们可以通过kubectl set image命令为Deployment设置新的镜像名称:
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.2

另一种更新的方法是使用kubectl edit命令修改Deployment的配置,将spec.template.spec.containers[0].image从nginx:1.7.9更改为nginx:1.9.1
kubectl edit deployment/nginx-deployment

一旦镜像名(或Pod定义)发生了修改,则将触发系统完成该Deployment所有运行Pod的滚动升级操作。可以使用kubectl rollout status命令查看Deployment的更新过程:
kubectl rollout status deployment/nginx-deployment查看pod的详细信息,可以验证Nginx是否更新为Nginx1.9.1。

Deployment是如何完成Pod更新的呢?
我们可以使用kubectl describe deployments/nginx-deployment命令仔细观察Deployment的更新过程。初始化创建Deployment是,系统创建了一个ReplicaSet并按用户的需求创建了3个Pod副本。当更新Deployment时,系统创建了一个新的ReplicaSet,并将其副本数扩展到1,然后将旧的ReplicaSet缩减为2。之后,系统继续按照相同的更新策略对新旧两个ReplicaS进行逐个调整。最后,新的ReplicaSet运行了3个新版本Pod副本,旧的ReplicaSet副本数量则缩减为0。
可以通过下面命令查看rc
kubectl get rc
在整个升级的过程中,系统会保证至少有两个Pod可用,并且最多同时运行4个Pod,这是Deployment通过复杂的算法完成的。Deployment需要确保在整个更新过程中只有一定数量的Pod可能处于不可用状态。在默认情况下,Deployment确保可用的Pod总数至少为所需要的副本数量(Desired)减1,也就是最多1个不可用(maxUnavailable=1)。Deployment还需要确保在整个更新过程中Pod的总数量不会超过所需的副本数量太多。在默认情况下,Deployment确保Pod的总数最多比所需Pod数多1个,也就是最多1个浪涌值(masSurge=1)。k8s1.6版本开始,maxUnavailable和maxSurage的默认值将从1、1更新为所需要副本数量的25%、25%。
这样,在升级过程中,Deployment就能够保证服务不中断,并且副本数量始终维持为用户指定的数量(Desired)
对更新策略的说明如下:
在Deployment的定义中,可以通过spec.strategy指定Pod更新的策略,目前支持两种策略:Recrete(重建)和RollingUpdate(滚动更新),默认值为Rolling Update。在前面的例子中使用的就是Rolling Update策略。
◎ Recreate: 设置spec.strategy.type=Recreate,表示Deployment在更新Pod时,会先杀掉所有正在运行的Pod,然后创建新的Pod。
◎ RollingUpdate: 设置spec.strategy.type = RollingUpdate,表示Deployment会以滚动更新的方式来逐个更新Pod。同时,可以通过设置spec.strategy.rollingUpdate下的两个参数(maxUnavailable和maxSurge)来控制滚动更新的过程。
下面对滚动更新时两个主要参数的说明如下:
◎ spec.strategy.rollingUpdate.maxUnavailable:用于指定Deployment在更新过程中不可用状态的Pod数量的上限。该maxUnavailable的数值可以是绝对值(例如5)或Pod期望的副本数的百分比(例如10%),如果被设置为百分比,那么系统会先以向下取整的方式计算出绝对值(整数)。而当另一个参数maxSurge被设置为0时,maxUnavailable则必须被设置为绝对数值大于0(从Kubernetes 1.6开始,maxUnavailable的默认值从1改为25%)。举例来说,当maxUnavailable被设置为30%时,旧的ReplicaSet可以在滚动更新开始时立即将副本数缩小到所需副本总数的70%。一旦新的Pod创建并准备好,旧的ReplicaSet会进一步缩容,新的ReplicaSet又继续扩容,整个过程中系统在任意时刻都可以确保可用状态的Pod总数至少占Pod期望副本总数的70%。
◎ spec.strategy.rollingUpdate.maxSurge:用于指定在Deployment更新Pod的过程中Pod总数超过Pod期望副本数部分的最大值。该maxSurge的数值可以是绝对值(例如5)或Pod期望副本数的百分比(例如10%)。如果设置为百分比,那么系统会先按照向上取整的方式计算出绝对数值(整数)。从Kubernetes 1.6开始,maxSurge的默认值从1改为25%。举例来说,当maxSurge的值被设置为30%时,新的ReplicaSet可以在滚动更新开始时立即进行副本数扩容,只需要保证新旧ReplicaSet的Pod副本数之和不超过期望副本数的130%即可。一旦旧的Pod被杀掉,新的ReplicaSet就会进一步扩容。在整个过程中系统在任意时刻都能确保新旧ReplicaSet的Pod副本总数之和不超过所需副本数的130%。
这里需要注意多重更新(Rollover)的情况。如果Deployment的上一次更新正在进行,此时用户再次发起Deployment的更新操作,那么Deployment会为每一次更新都创建一个ReplicaSet,而每次在新的ReplicaSet创建成功后,会逐个增加Pod副本数,同时将之前正在扩容的ReplicaSet停止扩容(更新),并将其加入旧版本ReplicaSet列表中,然后开始缩容至0的操作。
例如,假设我们创建一个Deployment,这个Deployment开始创建5个Nginx:1.7.9的Pod副本,在这个创建Pod动作尚未完成时,我们又将Deployment进行更新,在副本数不变的情况下将Pod模板中的镜像修改为Nginx:1.9.1,又假设此时Deployment已经创建了3个Nginx:1.7.9的Pod副本,则Deployment会立即杀掉已创建的3个Nginx:1.7.9 Pod,并开始创建Nginx:1.9.1 Pod。Deployment不会在等待Nginx:1.7.9的Pod创建到5个之后再进行更新操作。
还需要注意更新Deployment的标签选择器(Label Selector)的情况。通常来说,不鼓励更新Deployment的标签选择器,因为这样会导致Deployment选择的Pod列表发生变化,也可能与其他控制器产生冲突。如果一定要更新标签选择器,那么请务必谨慎,确保不会出现其他问题。关于Deployment标签选择器的更新的注意事项如下
(1)添加选择器标签时,必须同步修改Deployment配置的Pod的标签,为Pod添加新的标签,否则Deployment的更新会报验证错误而失败:
添加标签选择器是无法向后兼容的,这意味着新的标签选择器不会匹配和使用旧选择器创建的ReplicaSets和Pod,因此添加选择器将会导致所有旧版本的ReplicaSets和由旧ReplicaSets创建的Pod处于孤立状态(不会被系统自动删除,也不受新的ReplicaSet控制)。
(2)更新标签选择器,即更改选择器中标签的键或者值,也会产生与添加选择器标签类似的效果。
(3)删除标签选择器,即从Deployment的标签选择器中删除一个或者多个标签,该Deployment的ReplicaSet和Pod不会受到任何影响。但需要注意的是,被删除的标签仍会存在于现有的Pod和ReplicaSets上。
小结:
今天的内容到此结束,希望大家可以点点关注哦。
谢谢大家的支持。