数据权限设计(转载)
https://www.cnblogs.com/gcczhongduan/p/4822814.html
https://www.cnblogs.com/leoxie2011/archive/2012/03/18/2400367.html
一、前言
几乎在任何一个系统中,都离不开权限的设计,权限设计 = 功能权限 + 数据权限,而功能权限,在业界常常是基于RBAC(Role-Based Access Control)的一套方案。而数据权限,则根据不同的业务场景,则权限却不尽相同,应该根据具体的场景巧妙设计; 且必须在项目开始时进行设计,不像功能权限一样,在项目结束的时候在追加。
注:更细还可以加入字段权限
1.1 权限类型
【功能权限】:能做什么的问题,如增加产品。
【数据权限】:能看到哪些数据的问题,如查看本人的所有订单。
【字段权限】:能看到哪些信息的问题,如供应商账户,看不到角色、 部门等信息。
二、数据权限设计
2.1 应用场景
- 订单,可以由本人查看
- 销售单,可以由本人或上级领导查看
- 销售单,销售人员可以查看自己的,销售经理只查看 销售金额大于100,000的。
2.2 数据权限设计分析
数据权限跟功能权限有非常大的不同,颗粒度非常小。贯穿于整个项目的开发周期中,无法像功能权限一样在项目要结尾的时候追加。数据权限做不到组件级别,必须在项目设计阶段就已经规划好。之前看网上相同有人想基于SPRING切面的原理去实现数据权限,这样就能够做到了低侵入、低耦合,想法非常好。但是现实非常骨感,这样做使整个应用系统效率大减折扣,相同对数据权限的控制策略也非常不灵活
2.3 SQL语句可扩展,数据权限设计分析
数据权限往往作为功能权限的高级行为。能够从数据对象的幅度方面进行控制。比方用户仅仅能看自己的订单、普通会员看不到某数据对象的高级属性(字段)等等。颗粒度这么细的情况下对结果集处理显然是不可能了,这时仅仅能介入到SQL语句中,此时又不想在开发阶段让开发者过多的考虑数据权限的问题,这个时候就需要将sql 和数据权限策略分开。再调用接口的时候,进行数据权限接口的拼接。这样也算做到的代码的低侵入。
2.4 SQL语句高效解析处理
数据权限模块的核心之中的一个就有SQL语句的高效解析处理,SQL处理指依据当前登录人信息及数据权限策略生成一个带有数据权限处理结果的SQL语句。所以这里对SQL语句的解析处理必需要求精确、准确。在开发阶段由开发者把SQL写入到配置文件里,在执行阶段由数据权限取得该SQL进行分析处理(加上数据权限),这样就完毕了SQL的组装处理。
2.5 数据权限策略设计
最核心的地方就是数据权限策略的设计了,这里先引入几个概念:
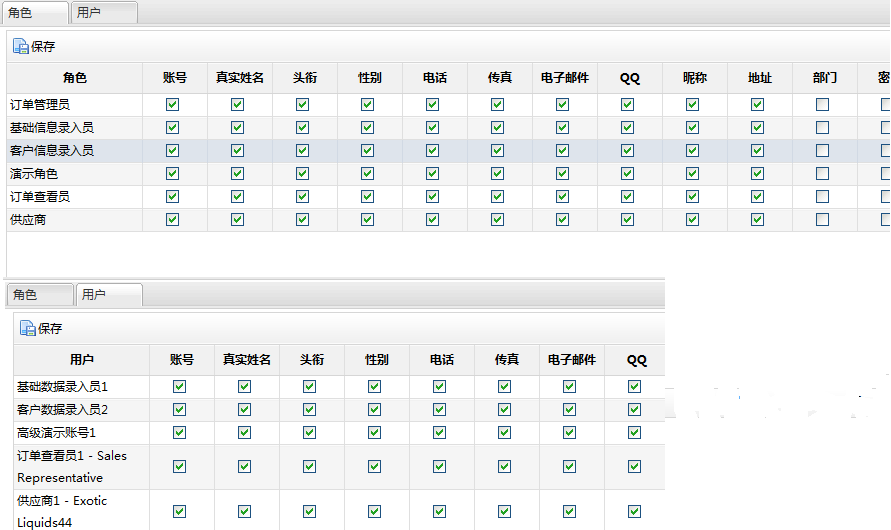
资源:数据权限的控制对象,业务系统中的各种资源。比方订单单据、销售单等主体:用户、部门、角色等条件规则:用于检索数据的条件定义数据规则:用于【数据权限】的条件规则
简单例子:包含了资源,主体,规则。
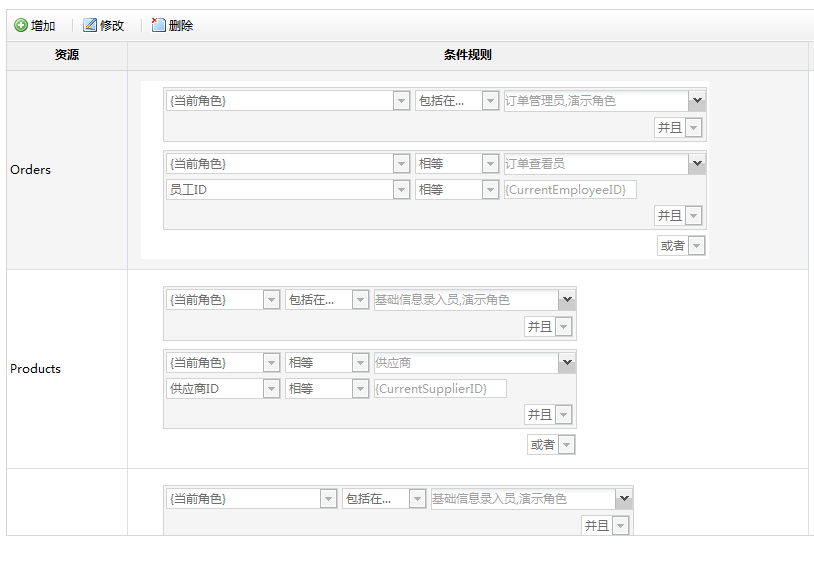
规则应用中:销售员只能查看到自己的销售订单。
2.6 思考两个问题:
第一,如何配置
第二,如何拼接sql语句
2.6.1 应用示例
- 订单,可以由本人查看
- 销售单,可以由本人或上级领导查看
- 销售单,销售人员可以查看自己的,销售经理只查看 销售金额大于100,000的。
我们能想到直接的方法,在访问数据的入口加入SQL Where条件来实现,组织sql语句
where UserID = {CurrentUserID}
where UserID = {CurrentUserID} or {CurrentUserID} in (领导)
where UserID = {CurrentUserID} or ({CurrentUserID} in (销售经理) and 销售金额 > 100000)
这些一个一个的条件,简单理解为一个【数据规则】。
不同的人应该对应不同的规则,那么也可以理解为,一个用户对应不同的角色,每一个角色有不一样的【数据规则】,那么设计就变成
【资源】 - 【主体】 - 【数据规则】
根据提供者的不同,准备不同的权限应对策略。
2.6.2 资源 - 规则
使用JSON 格式,将资源和规则得到应用。
{
"rules": [{
"field": "CustomerID",
"op": "like",
"value": "AN",
"type": "string"
}],
"op": "and"
}
上面的格式再考虑安全性的时候,不够高,推荐下面这种方式:
{
"rules": [{
"field": "OrderDate",
"op": "less",
"value": "2012-01-01"
},
{
"field": "CustomerID",
"op": "equal",
"value": "VINET"
}
],
"op": "and"
}
(过滤规则分为三个部分:【分组】、【规则】(字段、值、操作符)、【操作符】(and or),而自身就是一个分组。)
规则描述:
查找顾客VINET所有订单时间小于2011-01-01的单据
这样的数据是安全的,而且是通用的(你甚至可以再加一个OR子查询)。无论是在前端还是后台,无论你使用什么样的组件,都可以很好地利用。
通用后台的翻译,就可以生成这样SQL的参数:
Text:
([OrderDate] < @p1 and [CustomerID] = @p2)
Parameters:
p1:2012-01-01
p2:VINET
2.6 字段权限
如果说数据权限是对功能权限在纵向的扩展,那么字段权限就是在横向的扩展。可以禁止指定用户/角色 对某些字段的访问