Redis数据结构(1)——redisObject对象和string
前言
该系列重点讲解Redis在内存中的数据结构实现(暂不涉及基础api)。Redis本质上是一个数据结构服务器(data structures server),以高效的方式实现了多种现成的数据结构,研究它的数据结构和基于其上的算法,对于我们自己提升局部算法的编程水平有很重要的参考意义。
当我们在本文中提到Redis的“数据结构”,可能是在两个不同的层面来讨论它。
第一个层面,是从使用者的角度。比如:
string
list
hash
set
sorted set
这一层面也是Redis暴露给外部的调用接口。
第二个层面,是从内部实现的角度,属于更底层的实现。比如:
dict
sds
ziplist
quicklist
skiplist
目录:
1 redisObject对象
2 string
2.1 int编码
2.2 简单动态字符串(sds)
2.2.1 SDS 结构
2.2.2 raw编码(长度<=39)
2.2.3 embstr编码(长度>39)
2.2.4 embstr 和 raw 编码区别
2.2.5 预分配机制
注1:整数对象共享池
redisObject对象:
本篇主要讲string 和 sds,开始之前有必要讲下redis redisObject对象。Redis存储的数据都使用redisObject来封装(如图),包括string、hash、list、set、zset在内的所有数据类型。下面针对每个字段做详细说明:
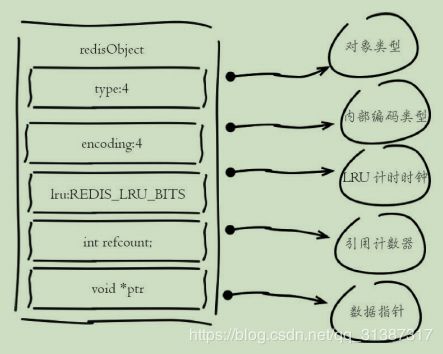
- type字段:表示当前对象使用的数据类型,Redis主要支持5种数据类型:string、hash、list、set、zset。可以使用type{key}命令查看对象所属类型,type命令返回的是值对象类型,键都是string类型。
- encoding字段:表示Redis内部编码类型,encoding在Redis内部使用,代表当前对象内部采用哪种数据结构实现。理解Redis内部编码方式对于优化内存非常重要,同一个对象采用不同的编码实现内存占用存在明显差异。
- lru字段:记录对象最后一次被访问的时间,当配置了maxmemory和maxmemory-policy=volatile-lru或者allkeys-lru时,用于辅助LRU算法删除键数据。可以使用object idletime{key}命令在不更新lru字段情况下查看当前键的空闲时间(object idletime{key}=当前时间-lru记录时间 =空闲时间)。 注:可以使用scan+object idletime命令批量查询哪些键长时间未被访问,找出长时间不访问的键进行清理,可降低内存占用
- refcount字段:记录当前对象被引用的次数,用于通过引用次数回收内存,当refcount=0时,可以安全回收当前对象空间。使用object refcount{key}获取当前对象引用。当对象为整数且范围在[0-9999]时,Redis可以使用共享对象的方式来节省内存(见 注1)。
- *ptr字段:与对象的数据内容相关,如果是整数,直接存储数据;否则表示指向数据的指针。Redis在3.0之后对值对象是字符串且长度<=39字节的数据,内部编码为embstr类型,字符串sds和redisObject一起分配,从而只要一次内存操作即可。
string
字符串类型是Redis最基础的数据结构。键都是字符串类型,而且其他几种数据结构都是在字符串类型基础上构建的,值最大不能超过512MB。
内部编码:字符串对象的编码可以是 int(数字时) 、 raw(字符长度>39) 或者 embstr (字符长度<=39) 。
1.int编码
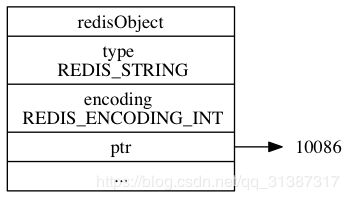
如果一个字符串对象保存的是整数值, 并且这个整数值可以用 long 类型来表示, 那么字符串对象会将整数值保存在字符串对象结构的 ptr 属性里面(将 void* 转换成 long ), 并将字符串对象的编码设置为 int 。(值得注意的是,如果数值在[0,9999] redis使用的是整数缓存池的(见 注1))
举个例子, 如果我们执行以下 SET 命令, 那么服务器将创建一个 int 编码的字符串对象作为 number 键的值:
redis> SET number 10086
OK
redis> OBJECT ENCODING number (返回具体编码类型)
"int"
如图:
2.简单动态字符串(simple dynamic string)SDS (raw 和 embstr内部实现,内存分配方式有区别)
2.1 SDS 结构
/*
* 保存字符串对象的结构 (sds)
*/
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度 (初次申请内存空间为0)
int free;
// 数据空间
char buf[];
};
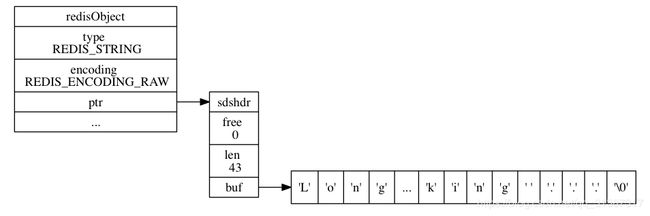
2.2 raw编码
redis> SET story "Long, long, long ago there lived a king ..."
OK
redis> STRLEN story
(integer) 43
redis> OBJECT ENCODING story
"raw" //长度大于39编码方式为 raw
如图:
2.3 embstr编码
redis> SET msg "hello"
OK
redis> OBJECT ENCODING msg
"embstr"
如图:

2.4 embstr 和 raw 编码区别(最主要的就是embstr创建字符串redisObject对象的时候直接分配字符串内存空间了)
- embstr 编码将创建字符串对象所需的内存分配次数从 raw 编码的两次降低为一次。
- 释放 embstr 编码的字符串对象只需要调用一次内存释放函数, 而释放 raw 编码的字符串对象需要调用两次内存释放函数。
- 因为 embstr 编码的字符串对象的所有数据都保存在一块连续的内存里面, 所以这种编码的字符串对象比起 raw 编码的字符串对象能够更好地利用缓存带来的优势。
2.5 预分配机制
在字符串拼接的时候如append、setrange操作会引起 SDS 扩容进行内存空间预分配,这样带来的一个好处就是 减少修改字符串时带来的内存重分配次数
如:操作一set 一个60字节长度字符串
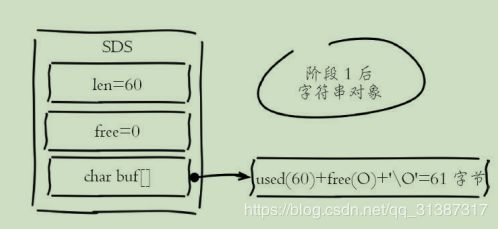
阶段1插入新的字符串后,free字段保留空间为0,总占用空间=实际占用空间+1字节,最后1字节保存‘\0’标示结尾
操作二 append 60 字节
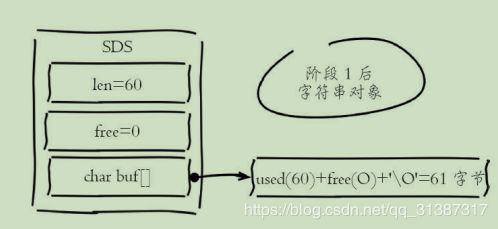
追加操作后字符串对象预分配了一倍容量作为预留空间(并不是所有情况都扩容一倍,见下文),而且大量追加操作需要内存重新分配,造成内存碎片率上升。
操作三 直接插入与阶段2相同数据的空间占用
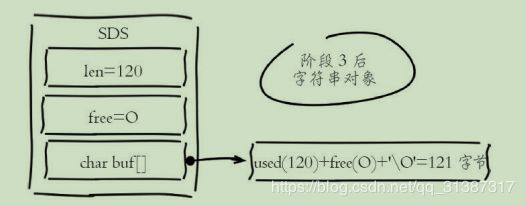
相比阶段二 节省了内存预分配的空间。
字符串之所以采用预分配的方式是防止修改操作需要不断重分配内存和字节数据拷贝(频繁的内存重分配是个耗时的操作,这里算是redis在空间和时间上的一个权衡)。
SDS带来的另一个好处就是降低strlen复杂度(O(n) -> 0(1)),直接获取len的值。
空间预分配规则:
1、第一次创建len属性等于数据实际大小,free等于0,不做预分配
2、修改后如果已有free空间不够且数据小于1M,每次预分配一倍容量。如原有len=60byte,free=0,在追击60byte,预分配120byte,总占用空间:60byte+60byte+120byte+1byte
3、修改后如果已有free空间不够且数据大于1M,每次预分配1M数据。如原有len=30M,free=0,当在追击100byte,预分配1M,总占用空间:1M+100byte+1M+1byte
注1
整数对象共享池
Redis为了节省内存开销,内部维护[0-9999]的整数对象池。创建大量的整数类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚至超过了整数自身空间消耗。所以Redis内存维护一个[0-9999]的整数对象池,用于节约内存。除了整数值对象,其他类型如list、hash、set、zset内部元素也可以使用整数对象池。因此开发中在满足需求的前提下,尽量使用整数对象以节省内存。
可以通过object refcount命令查看对象引用数验证是否启用整数对象池技术(上文中介绍的redisObject refcount 字段),如下:
redis> set foo 100
OK
redis> object refcount foo(integer)
2
redis> set bar 100
OK
redis> object refcount bar(integer)
3
设置键foo等于100时,直接使用共享池内整数对象,因此引用数是2,再设置键bar等于100时,引用数又变为3。
值得注意的是:使用整数对象共享池会节约大量内存,但是对象池并不是只要存储[0-9999]的整数就可以工作。当设置maxmemory并启用LRU相关淘汰策略(redis淘汰策略另一篇写~)如:volatile-lru,allkeys-lru时,Redis禁止使用共享对象池,测试命令如下:
redis> set key:1 99
OK // 设置key:1=99
redis> object refcount key:1(integer)
2 // 使用了对象共享,引用数为2
redis> config set maxmemory-policy volatile-lru
OK // 开启LRU淘汰策略
redis> set key:2 99
OK // 设置key:2=99
redis> object refcount key:2(integer)
3 // 使用了对象共享,引用数变为3
redis> config set maxmemory 1GB
OK // 设置最大可用内存
redis> set key:3 99
OK // 设置key:3=99
redis> object refcount key:3(integer)
1 // 未使用对象共享,引用数为1
redis> config set maxmemory-policy volatile-tt
OK // 设置非LRU淘汰策略
redis> set key:4 99
OK // 设置key:4=99
redis> object refcount key:4(integer)
4 // 又可以使用对象共享引用数变为4
为什么开启maxmemory和LRU淘汰策略后对象池无效?
LRU算法需要获取对象最后被访问时间,以便淘汰最长未访问数据,每个对象最后访问时间存储在redisObject对象的lru字段。对象共享意味着多个引用共享同一个redisObject,这时lru字段也会被共享,导致无法获取每个对象的最后访问时间。如果没有设置maxmemory,直到内存被用尽Redis也不会触发内存回收,所以共享对象池可以正常工作。
对于ziplist编码的值对象,即使内部数据为整数也无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本过高。
为什么redis不共享包含字符串的对象?
当服务器考虑将一个共享对象设置为键的值对象时,程序需要先检查给定的共享对象和键想创建的目标对象是否完全相同,只有在共享对象和目标对象完全相同的情况下,程序才会将共享对象用作值对象,而一个共享对象保存的值越复杂,验证共享对象和目标对象是否相同所需的复杂度就会越高,消耗cpu时间也会越多。
- 如果共享对象时保存整数值的字符串对象,那么验证操作的复杂度为o(1)
- 如果共享对象时保存字符串值的字符串对象,那么验证操作的复杂度为o(n)
- 如果共享对象时包含了多个值(或者对象的)对象,比如列表对象或者哈希对像,那么那么验证操作的复杂度为o(
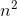 )
)
因此,尽管共享对象更复杂的对象可以节约更多的内存,但受到CPU时间的限制,redis只建立了一个小整数共享池
文章部分内容来自@张铁磊http://zhangtielei.com/posts/blog-redis-dict.html,《redis设计与实现》,《redis开发与运维》