String类常用方法和高级知识点
一:常用的方法
| char charAt(int index) | 返回指定索引处的 char 值 |
| int codePointAt(int index) | 返回指定索引处的字符的Unicode编码 |
| int compareTo(String anotherString) | this与anotherString比较,返回正,负,0 |
| String concat(String str) | 相当于“+”拼接字符串 |
| boolean endsWith(String suffix) | 是否以指定字符串结尾 |
| boolean equalsIgnoreCase(String anotherString) | 和equals一样只不过这个方法忽略大小写 |
| int indexOf(String str) | 指定字符在此字符中第一次出现的索引(另有重载的可以从指定索引后查找) |
| String replaceAll(String regex, String replacement) | 将前一个字符串全部替换为后一个字符串(类似的有replace()) |
| String[] split(String regex) | 把一个有规则的String以参数字符为分割符号,切分成一个String[]; |
以':'截取---->{ "boo", "and", "foo" }
"boo:and:foo" 以下是关于split的官方例子
以'o'截取--->{ "b", "", ":and:f" }//注意API中写到数组中不包括结尾空字符串。
以'b'截取--->{"",oo:and:foo}//当截取元素出现在索引0时,分割后数组索引 0为空字符串""
二:正则表达式
正则表达式是一门独立的语言,是为字符数据提供匹配模板:
以下是匹配邮箱的示例:
public static boolean checkEmail(String email) {
boolean flag = false;
try {
String check = "^([a-z0-9A-Z]+[-|_|\\.]?)+[a-z0-9A-Z]@([a-z0-9A-Z]+(-[a-z0-9A-Z]+)?\\.)+[a-zA-Z]{2,}$";
//在Patten类中(正则表达式的编译表示形式)写到,以下是典型的调用
Pattern regex = Pattern.compile(check); //将正则表达式转换为编译表示形式
Matcher matcher = regex.matcher(email); //matcher()创建匹配给定输入与此模式的匹配器
flag = matcher.matches();//调用matches()是否匹配
} catch (Exception e) {
flag = false;
}
return flag;
}
三:字符缓存区
1.堆中及缓存区中的对象创建
①String str1=new String("Hello");//在堆中和缓存区创建2个对象,并且str1指向堆中的对象
②String Str2="Hello";//在缓存区创建
③String s3 = new String("1") + new String("1"); // 此时生成了四个对象 常量池中的"1" + 2个堆中的"1" + s3指向的堆中的对象(注此时常量池不会生成"11")
在创建相应字符串之前都会到字符串缓存区中查找有没有该字符串的存在,没有则在缓存区中创建该字符串。如果有,则创建。
如果①②两行代码执行按顺序
String str1=new String("Hello");
String Str2="Hello";
System.out.println(str1==Str2);//false第二个是不会再缓存区中创建对象的,此时堆中和缓存区都有一个“Hello”对象,且都是因为str1创建的。但此时str1指向堆中对象,str2指向缓存区中对象,所以str1==str2将为false。
2.intern()方法
说明:intern用来返回常量池中的某字符串,如果常量池中已经存在该字符串,则直接返回常量池中该对象的引用。否则,在常量池中加入该对象,然后 返回引用。
可以看到,这是一个开放给程序员干预字符缓存区的方法。
给出几个测试:
①intern干预字符缓存区(未实际干预)demo1:
String s1 = new String("1");// 同时会生成堆中的对象 以及常量池中1的对象,但是此时s1是指向堆中的对象的
String intern = s1.intern();// 常量池中的已经存在,返回的是上一句执行时,在缓存区中存的"1"
String s2 = "1";//由于缓存区中已经存在了"1",s2直接指向缓存区中的"1"
System.out.println(s1 == s2);// false 注意:s1指向的是堆中的对象
System.out.println(intern==s2);//true②intern干预字符缓存区(实际干预)demo2:
String s3 = new String("2") + new String("2");//注此时缓存区不会生成"11"
String s4 = "22";// 缓存区中不存在22,所以会新开辟一个存储22对象的缓存区地址
String intern = s3.intern();// 缓存区22的地址和s3的地址不同
System.out.println(s3 == s4); // false
System.out.println(intern == s3); // false
System.out.println(intern == s4); // true这里调换初始化顺序
String s3 = new String("2") + new String("2");//注此时缓存区不会生成"11"
//调换初始化顺序
String intern = s3.intern();
String s4 = "22";// 缓存区中存在22,此时intern和s4指向同一个对象
System.out.println(s3 == s4); // true ??这里也是true
System.out.println(intern == s3); // true
System.out.println(intern == s4); // true说明:上面这个图中三个都是true,本次测试用的是jdk1.8。为啥会提到jdk版本?
由于1.7将永久代(即方法区)中的缓存区(常量池)移到了堆中,并且官方文档中明确指出该次更新将显著影响String的intern方法。我们将jdk更改为1.6,代码不变。
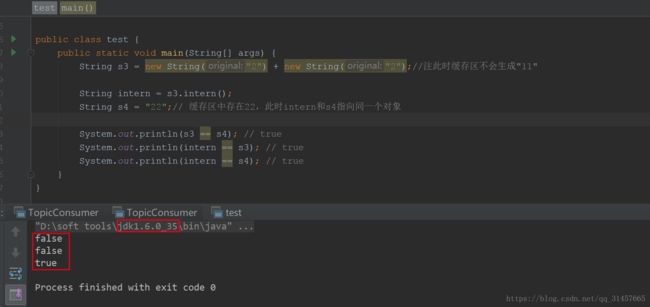
可以看到更换为1.6后,由原来的true,true,ture变成了false,false,ture。
解释:1.6版本之前,缓存池是存在于方法区中的,最近的这个图中,intern方法执行时,发现没有缓存池中没有“11”这个字符串,于是是就在缓存池中创建了,此时s3还是指向堆中的对象,所以s3和intern以及s4不是同一个对象。
而到了1.7及以上,为了方便看,我们把1.7的结果截图贴下:
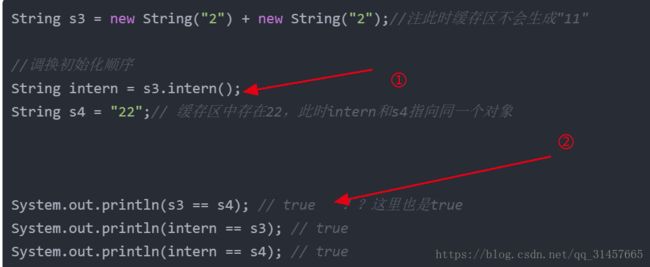
因为方法区中的缓存池被移到了堆中,这里①执行,将实际干预缓存池,由于没有底层源码,我们猜测,先在堆中的缓存池创建这个“22”,既然大家都在堆中,s3的引用指向了缓存中的对象多方便,哈哈(这里只是一个合理化的猜想,没有证实,只是方便理解)。这样,s3和堆中的是同一个对象,所以三个指向的都是同一个对象。
感兴趣的也可以了解下,jdk8将整个永久代(方法区)移除了。
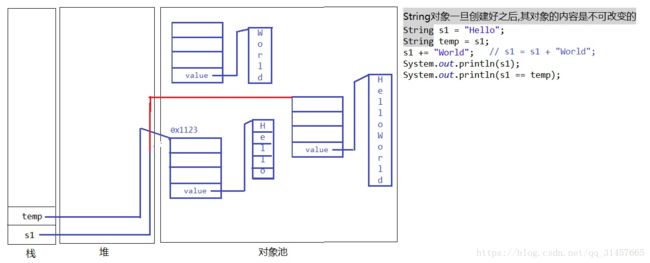
四:String底层空间分配
1.String为什么每拼接一次就会新创建一个新的String对象?
混淆的知识点:String是final的,其不能被继承,但是其引用指向对象的值是可改变的。final修饰的引用一经赋值不可在变
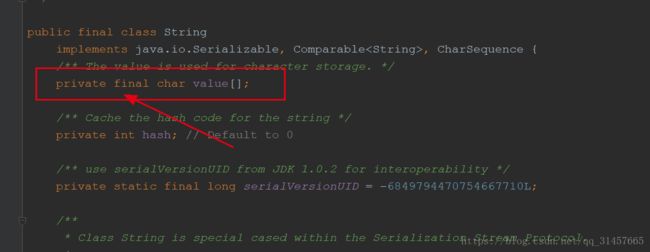
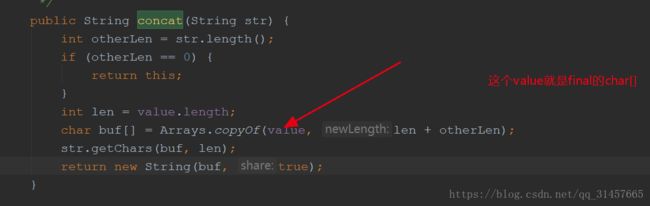
原因:String的底层事实上使用的一个final的char[]来存储的,每一次拼接都是重新创建一个新的String对象返回
所以,底层对其内存分配事实上是这样的
2.String为什么是线程安全的
先说线程不安全出现的条件
①多线程环境下并发的
②修改
③同一个数据
三个条件缺一不可。事实上解决多线程安全问题的方案就是从条件下手。②就不说了,主要是打破①和③。
常见的的线程安全方式:
- 多线程环境变同步环境:
常见的synchronized,lock等方式就是将多线程环境变成同步环境。关键操作依次进行,这样就可以打破条件①
- 数据副本:
典型的就是ThreadLocal,ThreadLocal存储的变量,在多线程环境下会为不同的线程提供不同的变量副本,所以每个线程拿到的数据对象都是不同的,更改也就不影响其他的线程。当然ThreadLocal并不是 synchronized的替代品,而是针对synchronize相对不足的部分的补充。
最经典的例子就是数据库连接使用ThreadLocal的例子。
如果你只用同一个连接,那么多线程条件下必然会出问题(前一个线程关闭了连接,拿着这个连接的所有线程都将挂掉)。这个时候可以使用synchronized,很明显这效率太低。如果使用ThreadLocal,这个时候你可以屏蔽多线程环境的复杂因素,只需要按照正常的环境进行编码就行,这会使代码显得更简洁易懂。
啰嗦了半天只是说明,提供数据副本是可以避免多线程安全问题的.String正是用的这种方案。
因为,无论是多线程环境还是同步环境,只要是修改String的值,其底层会将String对象中的value值复制一份放到一个final的char[]中,然后将引用指向这个新的char[],返回的对象将会是新的对象.那么每次操作,真正操作的不是同一个String对象的value。而是副本。既然是副本也就不存在多线程安全问题。
3.关于字符串拼接的处理
常用的字符串拼接的4种方式 “+”,concat,StringBuffer,StringBuider
https://blog.csdn.net/yh_zeng2/article/details/73441551这个帖子中测试了四种方式的效率。结果是
“+” < concat () < StringBuffer < StringBuilder 。(我要补充一点,如果是明文的字符串拼接比如“aa”+“bb”,事实上编译期间编译器就会优化成为“aabb”,这种情况下效率当然是最快的,运行期没到就完成了。)
为什么会出现这种情况呢。看看底层原理
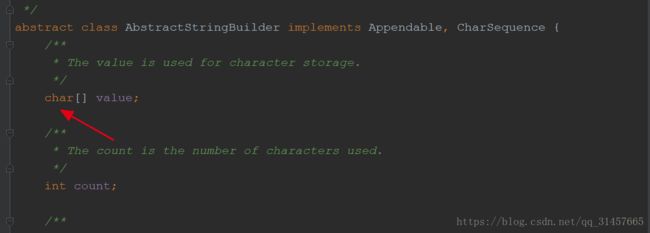
底层原理:java.lang.StringBuilder 与 java.lang.StringBuffer 同是继承于 java.lang.AbstractStringBuilder,具体在功能实现大多在 AbstractStringBuilder 中,这个类与String最大的区别在于摒弃了final的char[]数组(见下图),这个操作会导致原有的String的线程安全特性被破坏,StringBuilder 和 StringBuffer 对其进行了接口封装,区别便是在线程安全方面,一个作了同步封装、一个作非同步封装。
所以
StringBuffer : 速度慢; 线程安全的;
StringBuilder: 速度快; 非线程安全的;
那么StringBuffer < StringBuilder是显而易见的,但是为什么concat () < StringBuffer呢?因为根据1中的源码,String每拼接一次字符串就会创建大量的中间对象以及数组的复制,效率肯定是低的。