tensorflow实现泰坦尼克号生存率预测(逻辑回归)
目录
1 逻辑回归介绍
2 泰坦尼克号数据集介绍及预处理
2.1 数据集介绍
2.2 数据预处理
3 用 tensorflow 搭建网络进行训练和预测
3.1 搭建训练网络
3.2 进行训练
3.3 测试集进行预测,并上传kaggle查看正确率
4 可视化输出结果
1 逻辑回归介绍
其实我们可以把逻辑回归当成只有一层的神经网络。关于逻辑回归的具体知识可以参考我的上一边博客,地址:https://mp.csdn.net/postedit/82929291。使用交叉熵损失函数,下面两种形式都可以:
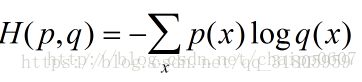

2 泰坦尼克号数据集介绍及预处理
2.1 数据集介绍
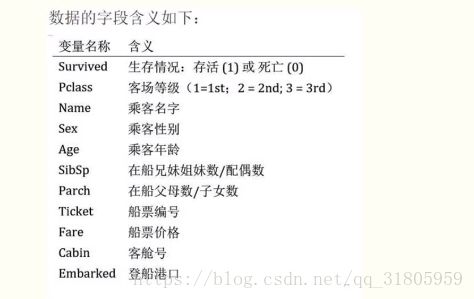
数据集分为:train.csv 和 test.csv
2.2 数据预处理
用pandas和numpy进行处理数据集。把 PassengerId,Name,Ticket 列去掉。把字符串类型变成数值型,缺失的值进行填充。把训练数据分成输入特征x和标签y。在jupyter notebook 编写代码,训练数据预处理,具体代码如下:
import numpy as np
import pandas as pd
data = pd.read_csv('train.csv')
data = data[['Survived', 'Pclass', 'Sex', 'Age', 'SibSp','Parch', 'Fare', 'Cabin', 'Embarked']] #筛选需要的列
data['Age'] = data['Age'].fillna(data['Age'].mean()) #平均值填充
data['Cabin'] = pd.factorize(data.Cabin)[0] #数值化
data.fillna(0,inplace=True) #剩余的缺失值用0填充
data['Sex'] = [1 if x == 'male' else 0 for x in data.Sex] #男变为1女变为0
data['p1'] = np.array(data['Pclass'] == 1).astype(np.int32)#船舱等级变为三列
data['p2'] = np.array(data['Pclass'] == 2).astype(np.int32)
data['p3'] = np.array(data['Pclass'] == 3).astype(np.int32)
del data['Pclass'] #删除此列
data['e1'] = np.array(data['Embarked'] == 'S').astype(np.int32)#也变为三列
data['e2'] = np.array(data['Embarked'] == 'C').astype(np.int32)
data['e3'] = np.array(data['Embarked'] == 'Q').astype(np.int32)
del data['Embarked']
data_train = data[[ 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin', 'p1', 'p2','p3', 'e1', 'e2', 'e3']]
data_target = data['Survived'].values.reshape(len(data),1)
测试数据预处理,代码如下:
data_test = pd.read_csv('test.csv')
data_test = data_test[['Pclass', 'Sex', 'Age', 'SibSp','Parch', 'Fare', 'Cabin', 'Embarked']]
data_test['Age'] = data_test['Age'].fillna(data_test['Age'].mean())
data_test['Cabin'] = pd.factorize(data_test.Cabin)[0]#数值化
data_test.fillna(0,inplace = True)
data_test['Sex'] = [1 if x == 'male' else 0 for x in data_test.Sex]
data_test['p1'] = np.array(data_test['Pclass'] == 1).astype(np.int32)
data_test['p2'] = np.array(data_test['Pclass'] == 2).astype(np.int32)
data_test['p3'] = np.array(data_test['Pclass'] == 3).astype(np.int32)
data_test['e1'] = np.array(data_test['Embarked'] == 'S').astype(np.int32)
data_test['e2'] = np.array(data_test['Embarked'] == 'C').astype(np.int32)
data_test['e3'] = np.array(data_test['Embarked'] == 'Q').astype(np.int32)
del data_test['Pclass']
del data_test['Embarked']
3 用 tensorflow 搭建网络进行训练和预测
3.1 搭建训练网络
import tensorflow as tf
x = tf.placeholder(dtype='float',shape=[None,12])
y = tf.placeholder(dtype='float',shape=[None,1])
#前向传播过程
weight = tf.Variable(tf.random_normal([12,1]))
bias = tf.Variable(tf.random_normal([1]))
output = tf.matmul(x,weight) + bias
pred = tf.cast(tf.sigmoid(output) > 0.5,tf.float32)#预测结果大于0.5值设为1,否则为0
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=output))#交叉熵损失函数
train_step = tf.train.GradientDescentOptimizer(0.0003).minimize(loss)#梯度下降法训练
accuracy = tf.reduce_mean(tf.cast(tf.equal(pred,y),tf.float32))
3.2 进行训练
sess = tf.Session() #开启会话
sess.run(tf.global_variables_initializer())#初始化所有变量
loss_train = []
train_acc = []
for i in range(25000):
#index = np.random.permutation(len(data_target))#打乱数据顺序,防止过拟合
#data_train = data_train[index]
#data_target = data_target[index]
for n in range(len(data_target)//100 + 1):
batch_xs = data_train[n*100:n*100+100]
batch_ys = data_target[n*100:n*100+100]
sess.run(train_step,feed_dict={x: batch_xs,y: batch_ys})
if i % 5000 ==0:
loss_temp = sess.run(loss,feed_dict={x: batch_xs,y: batch_ys})
loss_train.append(loss_temp)
train_acc_temp = sess.run(accuracy,feed_dict={x: batch_xs,y: batch_ys})
train_acc.append(train_acc_temp)
print(loss_temp,train_acc_temp)输出结果如下:

3.3 测试集进行预测,并上传kaggle查看正确率
predictions = sess.run(pred,feed_dict={x:data_test})
data_test = pd.read_csv('test.csv')
predictions = predictions.flatten()#二维数组变成一维数组
submission = pd.DataFrame({
"PassengerId": data_test["PassengerId"],"Survived": predictions
})
submission.to_csv("titanic-submission.csv", index=False)将保存的 titanic-submission.csv 文件上传到kaggle网站,进行查看测试集的正确率。若显示正确率为零,可能就文件的格式不对,您需要打开文件然后另存为,选择utf-8编码的格式即可。下面是我提交的结果:

4 可视化输出结果
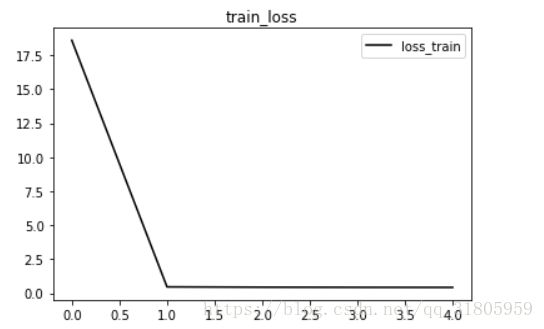
import matplotlib.pyplot as plt
plt.plot(loss_train,'k-',label = 'loss_train')
plt.title('train_loss')
plt.legend()
plt.show()可视化结果:
完整的代码和数据集在github: https://github.com/xiaooudong/tensorflow_titanic_logistic_regression